
АИ 101 година
Што е Overfitting?
Што е Overfitting?
Кога тренирате невронска мрежа, треба да избегнете преоптоварување. Преклопување е проблем во рамките на машинското учење и статистиката каде што моделот премногу добро ги учи шемите на базата на податоци за обука, совршено објаснувајќи го збирот на податоци за обуката, но не успевајќи да ја генерализира својата моќ на предвидување на други групи на податоци.
Поинаку кажано, во случај на преоптоварувачки модел, тој често ќе покаже исклучително висока точност на базата на податоци за обука, но мала точност на податоците собрани и пуштени низ моделот во иднина. Тоа е брза дефиниција за префитување, но ајде да го разгледаме концептот на прекумерно поставување подетално. Ајде да погледнеме како настанува прекумерното поставување и како може да се избегне.
Разбирање на „Fit“ и Underfitting
Корисно е да се погледне концептот на недоволно вклопување и „одговара” генерално кога се разговара за прекумерно поставување. Кога обучуваме модел, се обидуваме да развиеме рамка која е способна да ја предвиди природата или класата на ставките во базата на податоци, врз основа на карактеристиките што ги опишуваат тие ставки. Моделот треба да биде способен да објасни шема во рамките на базата на податоци и да ги предвиди класите на идните точки на податоци врз основа на оваа шема. Колку подобро моделот ја објаснува врската помеѓу карактеристиките на комплетот за обука, толку повеќе „погоден“ е нашиот модел.
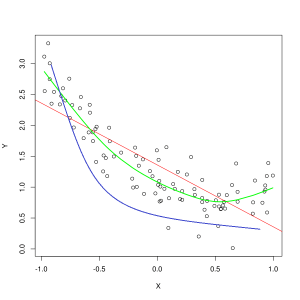
Сината линија ги претставува предвидувањата на модел кој не одговара, додека зелената линија претставува подобар модел. Фото: Пеп Рока преку Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Модел кој слабо ја објаснува врската помеѓу карактеристиките на податоците за обука и на тој начин не успева точно да ги класифицира идните примери на податоци е недоволно одговарање податоците за обуката. Ако треба да ја прикажете предвидената врска на недоволниот модел наспроти вистинското вкрстување на карактеристиките и етикетите, предвидувањата ќе се оддалечат од марката. Ако имавме график со означени вистинските вредности на множеството за обука, моделот со сериозно недоволно усогласување драстично ќе ги пропушти повеќето точки на податоци. Модел со подобро приспособување може да пресече патека низ центарот на податочните точки, при што поединечните точки на податоци се исклучени од предвидените вредности само за малку.
Недостатокот често може да се случи кога нема доволно податоци за да се создаде точен модел или кога се обидувате да дизајнирате линеарен модел со нелинеарни податоци. Повеќе податоци за обука или повеќе функции честопати ќе помогнат да се намали недоволното вклопување.
Па, зошто едноставно не би создале модел кој совршено ја објаснува секоја точка во податоците за обуката? Сигурно е пожелна совршена точност? Создавањето модел кој премногу добро ги научил шаблоните на податоците за обука е она што предизвикува преоптоварување. Збирот на податоци за обука и другите, идни збирки на податоци што ги извршувате низ моделот нема да бидат сосема исти. Тие веројатно ќе бидат многу слични во многу аспекти, но ќе се разликуваат и на клучни начини. Затоа, дизајнирањето модел кој совршено ја објаснува базата на податоци за обука значи дека ќе завршите со теорија за односот помеѓу карактеристиките што не се генерализира добро со другите збирки на податоци.
Разбирање на Overfitting
Прекумерното поставување се случува кога моделот премногу добро ги учи деталите во базата на податоци за обука, што предизвикува моделот да страда кога се прават предвидувања за надворешни податоци. Ова може да се случи кога моделот не само што ќе ги научи карактеристиките на сетот, туку ќе научи и случајни флуктуации или бучава во рамките на базата на податоци, ставајќи им важност на овие случајни/неважни појави.
Поголема е веројатноста да се појави преоптоварување кога се користат нелинеарни модели, бидејќи тие се пофлексибилни кога ги учат карактеристиките на податоци. Непараметриските алгоритми за машинско учење често имаат различни параметри и техники кои можат да се применат за да се ограничи чувствителноста на моделот на податоци и со тоа да се намали преоптоварувањето. Како пример, модели на стебла на одлуки се многу чувствителни на преоптоварување, но техниката наречена кастрење може да се користи за случајно да се отстранат некои од деталите што моделот ги научил.
Ако ги прикажете предвидувањата на моделот на оските X и Y, ќе имате линија на предвидување што цик-цак оди напред и назад, што го одразува фактот дека моделот премногу се трудел да ги вклопи сите точки од сетот на податоци во неговото објаснување.
Контролирање на прекумерно поставување
Кога тренираме модел, идеално сакаме моделот да не прави грешки. Кога перформансите на моделот се приближуваат кон правење точни предвидувања за сите точки на податоци во базата на податоци за обука, одговарањето станува подобро. Модел со добро вклопување може да ја објасни речиси целата база на податоци за обука без преоптоварување.
Како што тренира модел, неговите перформанси се подобруваат со текот на времето. Стапката на грешка на моделот ќе се намалува со текот на времето за обука, но се намалува само до одредена точка. Точката во која перформансите на моделот на тест гарнитурата почнуваат повторно да се зголемуваат е типично точката во која се случува прекумерно поставување. Со цел да го добиеме најдоброто вклопување за моделот, сакаме да престанеме да го тренираме моделот на точката на најмала загуба во сетот за обука, пред грешката повторно да почне да се зголемува. Оптималната точка на сопирање може да се утврди со графика на перформансите на моделот во текот на времето на обука и прекин на тренингот кога загубата е најмала. Сепак, еден ризик со овој метод за контрола на преоптоварување е дека специфицирањето на крајната точка за обуката врз основа на перформансите на тестот значи дека податоците од тестот донекаде се вклучени во процедурата за обука и тие го губат статусот на чисто „недопрени“ податоци.
Постојат неколку различни начини на кои некој може да се бори против претерувањето. Еден од методите за намалување на преоптоварувањето е да се користи тактика за повторно земање примероци, која функционира со проценка на точноста на моделот. Можете исто така да користите а валидација база на податоци во прилог на тест множеството и исцртајте ја точноста на обуката во однос на множеството за валидација наместо тест базата. Ова ја задржува вашата тест база на податоци невидена. Популарен метод за преземање примероци е вкрстена валидација со K-folds. Оваа техника ви овозможува да ги поделите вашите податоци на подмножества на кои моделот е обучен, а потоа се анализираат перформансите на моделот на подмножествата за да се процени како моделот ќе функционира на надворешните податоци.
Користењето на вкрстена валидација е еден од најдобрите начини да се процени точноста на моделот на невидени податоци, и кога се комбинира со базата на податоци за валидација, преоптоварувањето често може да се сведе на минимум.










