
АИ 101 година
Што е линеарна регресија?
Што е линеарна регресија?
Линеарната регресија е алгоритам кој се користи за предвидување, или визуелизирање, a врска помеѓу две различни карактеристики/променливи. Во задачите за линеарна регресија, се испитуваат два вида променливи: на зависна променлива и независната променлива. Независната променлива е променливата која стои сама по себе, а не под влијание на другата променлива. Како што се прилагодува независната променлива, нивоата на зависната променлива ќе флуктуираат. Зависната променлива е променливата што се проучува и тоа е она што регресивниот модел го решава/се обидува да го предвиди. Во задачите за линеарна регресија, секое набљудување/пример се состои и од вредноста на зависната променлива и од вредноста на независната променлива.
Тоа беше брзо објаснување за линеарната регресија, но ајде да се погрижиме да дојдеме до подобро разбирање на линеарната регресија со тоа што ќе погледнеме пример за неа и ќе ја испитаме формулата што ја користи.
Разбирање на линеарна регресија
Да претпоставиме дека имаме база на податоци што ги покрива големини на хард-дискови и цената на тие хард дискови.
Да претпоставиме дека базата на податоци што ја имаме се состои од две различни карактеристики: количина на меморија и цена. Колку повеќе меморија купуваме за компјутер, толку повеќе се зголемуваат трошоците за купување. Ако ги нацртаме поединечните точки на податоци на заплетот на расејување, може да добиеме график кој изгледа вака:

Точниот сооднос меморија-трошок може да варира помеѓу производителите и моделите на хард дискот, но генерално, трендот на податоците е оној што започнува во долниот лев агол (каде што хард дисковите се и поевтини и имаат помал капацитет) и се движи кон горниот десен (каде што погоните се поскапи и имаат поголем капацитет).
Ако ја имавме количината на меморија на оската X и цената на оската Y, линијата што ја прикажува врската помеѓу променливите X и Y ќе започне во долниот лев агол и ќе се протега на горниот десен агол.
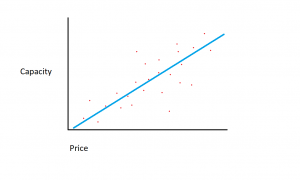
Функцијата на регресиониот модел е да определи линеарна функција помеѓу X и Y променливите што најдобро ја опишува врската помеѓу двете променливи. Во линеарната регресија, се претпоставува дека Y може да се пресмета од некоја комбинација на влезните променливи. Врската помеѓу влезните променливи (X) и целните променливи (Y) може да се прикаже со цртање линија низ точките на графикот. Линијата ја претставува функцијата што најдобро ја опишува врската помеѓу X и Y (на пример, за секој пат кога X се зголемува за 3, Y се зголемува за 2). Целта е да се најде оптимална „линија на регресија“ или линија/функција што најдобро одговара на податоците.
Линиите обично се претставени со равенката: Y = m*X + b. X се однесува на зависната променлива додека Y е независна променлива. Во меѓувреме, m е наклонот на линијата, како што е дефинирано со „подигнувањето“ над „трчањето“. Практичарите на машинско учење ја претставуваат познатата равенка на линијата на наклон малку поинаку, користејќи ја оваа равенка наместо тоа:
y(x) = w0 + w1 * x
Во горната равенка, y е целната променлива додека „w“ се параметрите на моделот, а влезот е „x“. Значи, равенката се чита како: „Функцијата што го дава Y, во зависност од X, е еднаква на параметрите на моделот помножени со карактеристиките“. Параметрите на моделот се приспособуваат за време на тренингот за да се добие најдобрата регресивна линија.
Повеќекратна линеарна регресија

Фото: Cbaf преку Wikimedia Commons, јавен домен (https://commons.wikimedia.org/wiki/File:2d_multiple_linear_regression.gif)
Процесот опишан погоре се однесува на едноставна линеарна регресија или регресија на сетови на податоци каде што има само една карактеристика/независна променлива. Сепак, регресија може да се направи и со повеќе карактеристики. Во случајот на "повеќекратна линеарна регресија”, равенката се проширува со бројот на променливи пронајдени во базата на податоци. Со други зборови, додека равенката за правилна линеарна регресија е y(x) = w0 + w1 * x, равенката за повеќекратна линеарна регресија би била y(x) = w0 + w1x1 плус тежините и влезовите за различните карактеристики. Ако го претставиме вкупниот број на тежини и карактеристики како w(n)x(n), тогаш би можеле да ја претставиме формулата вака:
y(x) = w0 + w1x1 + w2x2 + … + w(n)x(n)
По воспоставувањето на формулата за линеарна регресија, моделот за машинско учење ќе користи различни вредности за тежините, цртајќи различни линии на вклопување. Запомнете дека целта е да се најде линијата која најдобро одговара на податоците за да се одреди која од можните комбинации на тежина (а со тоа и која можна линија) најдобро одговара на податоците и ја објаснува врската помеѓу променливите.
Функцијата на трошоците се користи за да се измери колку се блиски претпоставените вредности на Y до вистинските Y вредности кога се дава одредена тежина. Функцијата на трошоците за линеарна регресија е средна квадратна грешка, која само ја зема просечната (квадратна) грешка помеѓу предвидената вредност и вистинската вредност за сите различни точки на податоци во збирката податоци. Функцијата на трошоци се користи за пресметување на трошок, што ја доловува разликата помеѓу предвидената целна вредност и вистинската целна вредност. Ако линијата за вклопување е далеку од податочните точки, трошокот ќе биде поголем, додека трошокот ќе стане помал колку што линијата се приближува до зафаќањето на вистинските односи помеѓу променливите. Тежините на моделот потоа се приспособуваат додека не се најде конфигурацијата на тежината што произведува најмала количина на грешка.










