
АИ 101 година
Што е спуштање на градиент?
Што е спуштање на градиент?
Ако сте прочитале за тоа како се обучуваат невронските мрежи, речиси сигурно сте го сретнале терминот „спуштање градиент“ претходно. Градиентско потекло е примарен метод за оптимизирање на перформансите на невронската мрежа, намалувајќи ја стапката на загуба/грешка на мрежата. Сепак, спуштањето со градиент може да биде малку тешко да се разбере за оние кои се нови во машинското учење, а овој напис ќе се обиде да ви даде пристојна интуиција за тоа како функционира спуштањето со градиент.
Спуштањето на градиент е алгоритам за оптимизација. Се користи за подобрување на перформансите на невронската мрежа со правење измени на параметрите на мрежата, така што разликата помеѓу предвидувањата на мрежата и реалните/очекуваните вредности на мрежата (наведени како загуба) е што е можно помала. Спуштањето на градиент ги зема почетните вредности на параметрите и ги користи операциите засновани на пресметка за да ги прилагоди нивните вредности кон вредностите што ќе ја направат мрежата што е можно попрецизна. Не треба да знаете многу калкулус за да разберете како функционира спуштањето на градиент, но треба да имате разбирање за градиентите.
Што се градиенти?
Да претпоставиме дека постои график кој ја претставува количината на грешка што ја прави невронската мрежа. Дното на графиконот ги претставува точките со најниска грешка, додека горниот дел од графиконот е местото каде што грешката е најголема. Сакаме да се движиме од врвот на графиконот надолу кон дното. Градиентот е само начин за квантифицирање на врската помеѓу грешката и тежините на невронската мрежа. Односот помеѓу овие две работи може да се прикаже графички како наклон, со неточни тежини кои произведуваат поголема грешка. Стрмноста на наклонот/градиентот претставува колку брзо учи моделот.
Поостриот наклон значи дека се прават големи намалувања на грешките и моделот брзо учи, додека ако наклонот е нула, моделот е на плато и не учи. Можеме да се движиме надолу по наклонот кон помала грешка со пресметување на градиент, насока на движење (промена на параметрите на мрежата) за нашиот модел.
Ајде малку да ја смениме метафората и да замислиме низа ридови и долини. Сакаме да стигнеме до дното на ридот и да го најдеме делот од долината што претставува најмала загуба. Кога тргнуваме на врвот на ридот, можеме да направиме големи чекори по ридот и да бидеме уверени дека се движиме кон најниската точка во долината.
Меѓутоа, како што се приближуваме до најниската точка во долината, нашите чекори ќе треба да станат помали, или во спротивно би можеле да ја надминеме вистинската најниска точка. Слично на тоа, можно е при прилагодување на тежините на мрежата, приспособувањата всушност да ја оддалечат од точката на најмала загуба, и затоа прилагодувањата мора да стануваат помали со текот на времето. Во контекст на спуштање по рид кон точка со најмала загуба, градиентот е вектор/инструкции кои детално го опишуваат патот што треба да го одиме и колку големи треба да бидат нашите чекори.
Сега знаеме дека градиентите се инструкции кои ни кажуваат во која насока да се движиме (кои коефициенти треба да се ажурираат) и колку се големи чекорите што треба да ги преземеме (колку коефициентите треба да се ажурираат), можеме да истражиме како се пресметува градиентот.
Пресметување градиенти и спуштање на градиент
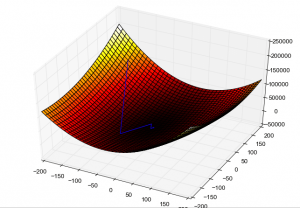
Спуштањето на градиент започнува на место со голема загуба и преку повеќекратни повторувања, презема чекори во насока на најмала загуба, со цел да се најде оптималната конфигурација на тежината. Фото: Роман Сузи преку Wikimedia Commons, CCY BY SA 3.0 (https://commons.wikimedia.org/wiki/File:Gradient_descent_method.png)
За да се изврши спуштање на градиент, прво мора да се пресметаат градиентите. Во ред да се пресмета градиентот, треба да ја знаеме функцијата загуба/трошок. Ќе ја користиме функцијата на трошоци за да го одредиме дериватот. Во пресметката, изводот само се однесува на наклонот на функцијата во дадена точка, така што ние во основа само го пресметуваме наклонот на ридот врз основа на функцијата на загуба. Загубата ја одредуваме со извршување на коефициентите низ функцијата загуба. Ако ја претставиме функцијата на загуба како „f“, тогаш можеме да кажеме дека равенката за пресметување на загубата е следнава (само ги извршуваме коефициентите преку избраната функција на трошоци):
Загуба = f (коефициент)
Потоа го пресметуваме дериватот или го одредуваме наклонот. Добивањето на дериватот на загубата ќе ни каже која насока е нагоре или надолу по наклонот, со тоа што ќе ни даде соодветен знак за да ги прилагодиме нашите коефициенти. Соодветната насока ќе ја претставиме како „делта“.
делта = дериват_функција(загуба)
Сега утврдивме која насока е надолу кон точката на најмала загуба. Ова значи дека можеме да ги ажурираме коефициентите во параметрите на невронската мрежа и се надеваме дека ќе ја намалиме загубата. Ќе ги ажурираме коефициентите врз основа на претходните коефициенти минус соодветната промена на вредноста како што е определено со насоката (делта) и аргументот што ја контролира големината на промената (големината на нашиот чекор). Аргументот што ја контролира големината на ажурирањето се нарекува „стапка на учење“ и ќе го претставиме како „алфа“.
коефициент = коефициент – (алфа * делта)
Потоа само го повторуваме овој процес додека мрежата не се спои околу точката на најмала загуба, која треба да биде близу нула.
Многу е важно да се избере вистинската вредност за стапката на учење (алфа). Избраната стапка на учење не смее да биде ниту премала ниту преголема. Запомнете дека како што се приближуваме до точката на најмала загуба, нашите чекори мора да станат помали или во спротивно ќе ја надминеме вистинската точка на најмала загуба и ќе завршиме на другата страна. Точката на најмалата загуба е мала и ако нашата стапка на промена е преголема, грешката може повторно да се зголеми. Ако големините на чекорите се преголеми, перформансите на мрежата ќе продолжат да отскокнуваат околу точката на најмала загуба, надминувајќи ја од едната, а потоа од другата страна. Ако тоа се случи, мрежата никогаш нема да се приближи кон вистинската оптимална конфигурација на тежина.
Спротивно на тоа, ако стапката на учење е премногу мала, на мрежата потенцијално може да и треба извонредно долго време за да се спои со оптималните тежини.
Видови на градиентско спуштање
Сега кога разбираме како функционира спуштањето на градиент воопшто, ајде да погледнеме некои од различните видови на спуштање на градиент.
Сериско спуштање со градиент: Оваа форма на спуштање со градиент поминува низ сите примероци за обука пред да се ажурираат коефициентите. Овој тип на спуштање на градиент веројатно е компјутерски најефикасен облик на спуштање на градиент, бидејќи тежините се ажурираат само откако ќе се обработи целата серија, што значи дека вкупно има помалку ажурирања. Меѓутоа, ако базата на податоци содржи голем број примери за обука, тогаш сериското спуштање на градиент може да направи обуката да трае долго.
Стохастичко спуштање со градиент: во Стохастичко спуштање градиент се обработува само еден пример за обука за секое повторување на спуштање на градиент и ажурирање на параметрите. Ова се случува за секој пример за обука. Бидејќи само еден пример за обука се обработува пред да се ажурираат параметрите, тој има тенденција да се спојува побрзо од Batch Gradient Descent, бидејќи ажурирањата се прават порано. Меѓутоа, бидејќи процесот мора да се изврши на секоја ставка во комплетот за обука, може да потрае доста време за да се заврши доколку сетот на податоци е голем, и затоа се користи еден од другите типови на спуштање со градиент доколку се претпочита.
Спуштање на градиент со мини серија: Спуштање со градиент со мини серија работи со поделба на целата база на податоци за обука на подсекции. Создава помали мини-серии кои се извршуваат низ мрежата, а кога мини-серија се користи за пресметување на грешката, коефициентите се ажурираат. Спуштање на мини-степен градиент навлегува во средината помеѓу Стохастичко спуштање на градиент и сериско спуштање со градиент. Моделот се ажурира почесто отколку во случајот со сериско спуштање со градиент, што значи малку побрзо и поцврсто конвергенција на оптималните параметри на моделот. Исто така е поефикасна од пресметковно од Стохастичко спуштање на градиент














