
Вештачка интелигенција
YOLOv7: Најнапредниот алгоритам за откривање објекти?

6 јули 2022 година ќе биде означен како обележје во историјата на вештачката интелигенција бидејќи токму на овој ден беше објавен YOLOv7. Уште од неговото лансирање, YOLOv7 е најжешката тема во заедницата на развивачи на Computer Vision и тоа од вистински причини. YOLOv7 веќе се смета за пресвртница во индустријата за откривање објекти.
Кратко по Објавен е трудот YOLOv7, се покажа како најбрзиот и најточниот модел за откривање приговори во реално време. Но, како YOLOv7 ги надминува своите претходници? Што го прави YOLOv7 толку ефикасен во извршувањето на задачите за компјутерска визија?
Во оваа статија ќе се обидеме да го анализираме моделот YOLOv7 и да се обидеме да го најдеме одговорот зошто YOLOv7 сега станува стандард во индустријата? Но, пред да можеме да одговориме на тоа, ќе треба да ја погледнеме кратката историја на откривање објекти.
Што е откривање на објекти?
Откривањето на објекти е гранка во компјутерската визија што идентификува и лоцира објекти во слика или видео датотека. Откривањето објекти е градежен блок на бројни апликации, вклучително и самоуправувачки автомобили, следен надзор, па дури и роботика.
Моделот за откривање објекти може да се класифицира во две различни категории, детектори со еден истрел, детектори за повеќе истрели.
Откривање на објекти во реално време
За вистински да разбереме како функционира YOLOv7, од суштинско значење е да ја разбереме главната цел на YOLOv7, “Откривање на објекти во реално време“. Откривањето на објекти во реално време е клучна компонента на модерната компјутерска визија. Моделите за откривање објекти во реално време се обидуваат да ги идентификуваат и лоцираат објектите од интерес во реално време. Моделите за откривање објекти во реално време го направија навистина ефикасно за програмерите да ги следат објектите од интерес во подвижна рамка како видео или влезен надзор во живо.

Моделите за откривање објекти во реално време се во суштина чекор понапред од конвенционалните модели за откривање слики. Додека првото се користи за следење на објекти во видео-датотеки, вториот ги лоцира и идентификува објектите во стационарна рамка како слика.
Како резултат на тоа, моделите за откривање објекти во реално време се навистина ефикасни за видео аналитика, автономни возила, броење објекти, следење повеќе објекти и многу повеќе.
Што е ЈОЛО?
YOLO или „Гледате само еднаш“ е семејство на модели за откривање објекти во реално време. Концептот YOLO првпат беше воведен во 2016 година од Џозеф Редмон, и стана збор за градот речиси веднаш бидејќи беше многу побрз и многу попрецизен од постоечките алгоритми за откривање објекти. Не помина долго време пред алгоритмот YOLO да стане стандард во индустријата за компјутерска визија.

Фундаменталниот концепт што го предлага YOLO алгоритмот е да се користи невронска мрежа од крај до крај користејќи кутии за ограничување и веројатности за класи за да се направат предвидувања во реално време. YOLO беше различен од претходниот модел за детекција на објекти во смисла дека предложи различен пристап за извршување на откривање објекти со пренаменување на класификаторите.
Промената во пристапот функционираше бидејќи YOLO наскоро стана индустриски стандард бидејќи јазот во изведбата меѓу себе, а другите алгоритми за откривање објекти во реално време беа значајни. Но, која беше причината зошто YOLO беше толку ефикасен?
Кога ќе се споредат со YOLO, тогаш алгоритмите за откривање објекти користеа мрежи за предлог регион за откривање на можни региони од интерес. Процесот на препознавање потоа беше извршен за секој регион посебно. Како резултат на тоа, овие модели често изведуваа повеќекратни повторувања на иста слика, а оттука и недостатокот на точност и поголемо време на извршување. Од друга страна, алгоритмот YOLO користи еден целосно поврзан слој за да го изврши предвидувањето одеднаш.
Како работи YOLO?
Постојат три чекори кои објаснуваат како функционира алгоритамот YOLO.
Реформирање на откривање на објекти како проблем со единечна регресија
на Алгоритмот YOLO се обидува да го реформира откривањето на објекти како единствен проблем на регресија, вклучувајќи ги пикселите на сликата, веројатностите на класите и координатите на граничните кутии. Оттука, алгоритмот треба да ја погледне сликата само еднаш за да ги предвиди и лоцира целните објекти на сликите.
Причини за сликата на глобално ниво
Исто така, кога алгоритмот YOLO прави предвидувања, тој ја објаснува сликата на глобално ниво. Тој е различен од техниките засновани на предлог-регион и лизгачки техники бидејќи алгоритмот YOLO ја гледа целосната слика за време на обуката и тестирањето на базата на податоци и може да ги кодира контекстуалните информации за класите и како тие се појавуваат.
Пред YOLO, Fast R-CNN беше еден од најпопуларните алгоритми за откривање на објекти кој не можеше да го види поголемиот контекст на сликата затоа што порано ги погрешуваше закрпите во заднината на сликата со објект. Во споредба со алгоритамот Fast R-CNN, YOLO е 50% попрецизен кога станува збор за грешки во позадина.
Генерализира претставување на објекти
Конечно, алгоритмот YOLO исто така има за цел да ги генерализира претставите на објектите во сликата. Како резултат на тоа, кога YOLO алгоритам беше извршен на база на податоци со природни слики и тестиран за резултатите, YOLO ги надмина постоечките R-CNN модели со голема разлика. Тоа е затоа што YOLO е многу генерализирано, шансите да се распадне кога се имплементира на неочекувани влезови или нови домени беа мали.
YOLOv7: Што има ново?
Сега кога имаме основно разбирање за тоа што се моделите за откривање објекти во реално време и што е алгоритам YOLO, време е да разговараме за алгоритмот YOLOv7.
Оптимизирање на процесот на обука
Алгоритмот YOLOv7 не само што се обидува да ја оптимизира архитектурата на моделот, туку има и за цел да го оптимизира процесот на обука. Таа има за цел да користи модули и методи за оптимизација за да ја подобри точноста на откривањето на објекти, да ги зајакне трошоците за обука, а истовремено да ги одржува трошоците за пречки. Овие модули за оптимизација може да се наведат како a торба со гратис за обука.
Доделување на етикета со водени од груби до фини олово
Алгоритмот YOLOv7 планира да користи нова ознака со водена ознака од груб до фино олово наместо конвенционална Динамична ознака за доделување. Тоа е така затоа што со динамичко доделување етикети, обуката на модел со повеќе излезни слоеви предизвикува некои проблеми, а најчестиот од нив е како да се доделат динамички цели за различни гранки и нивните излези.
Повторна параметаризација на моделот
Повторната параметриза на моделот е важен концепт во откривањето на објекти, а неговата употреба генерално се следи со некои проблеми за време на обуката. Алгоритмот YOLOv7 планира да го користи концептот на патека за ширење на градиент за да се анализираат политиките за репараметризација на моделот применливи за различни слоеви во мрежата.
Проширување и сложено скалирање
Алгоритмот YOLOv7 исто така го воведува проширени и сложени методи на скалирање да се користат и ефективно да се користат параметрите и пресметките за откривање на објекти во реално време.

YOLOv7: Поврзана работа
Откривање на објекти во реално време
YOLO е моментално индустриски стандард, а повеќето детектори на објекти во реално време користат YOLO алгоритми и FCOS (Целосно конволуционо едностепено детекција на објекти). Најсовремениот детектор на предмети во реално време обично ги има следните карактеристики
- Посилна и побрза мрежна архитектура.
- Ефективен метод за интеграција на карактеристики.
- Прецизен метод за откривање на објекти.
- Функција за робусна загуба.
- Ефикасен метод за доделување етикети.
- Ефикасен метод за обука.
Алгоритмот YOLOv7 не користи методи за учење и дестилација со само-надгледување кои често бараат големи количини на податоци. Спротивно на тоа, алгоритмот YOLOv7 користи метод на торба-of-freebies што може да се обучи.
Повторна параметаризација на моделот
Техниките за повторна параметризација на моделот се сметаат за ансамбл техника која спојува повеќе пресметковни модули во фаза на пречки. Техниката понатаму може да се подели во две категории: Ансамбл на ниво на модел, ансамбл на ниво на модул.
Сега, за да се добие конечниот модел на пречки, техниката на репараметризација на ниво на модел користи две практики. Првата практика користи различни податоци за обука за да обучи бројни идентични модели, а потоа ги просекува тежините на обучените модели. Алтернативно, другата практика ги просекува тежините на моделите за време на различни повторувања.
Повторната параметаризација на нивото на модулот неодамна добива огромна популарност бидејќи го дели модулот на различни гранки на модулот, или различни идентични гранки за време на фазата на обука, а потоа продолжува да ги интегрира овие различни гранки во еквивалентен модул додека интерференција.
Сепак, техниките за повторна параметризација не можат да се применат на сите видови архитектура. Тоа е причината зошто на Алгоритмот YOLOv7 користи нови техники за репараметаризација на модели за да дизајнира поврзани стратегии погоден за различни архитектури.
Скалирање на моделот
Скалирањето на моделот е процес на скалирање нагоре или надолу на постоечки модел за да се вклопи во различни компјутерски уреди. Скалирањето на моделот генерално користи различни фактори како што се бројот на слоеви (длабочина), големината на влезните слики (резолуција), број на карактеристични пирамиди (фаза), и број на канали (ширина). Овие фактори играат клучна улога во обезбедувањето балансирана размена за мрежните параметри, брзината на пречки, пресметувањето и точноста на моделот.
Еден од најчесто користените методи на скалирање е NAS или мрежна архитектура пребарување кој автоматски бара соодветни фактори за скалирање од пребарувачите без никакви комплицирани правила. Главниот недостаток на користењето на NAS е тоа што е скап пристап за пребарување на соодветни фактори за скалирање.
Речиси секој модел за повторна параметризација на модели независно ги анализира индивидуалните и единствените фактори на скалирање, а дополнително дури и независно ги оптимизира овие фактори. Тоа е затоа што архитектурата на NAS работи со не-корелирани фактори на скалирање.
Вреди да се напомене дека моделите базирани на конкатенација како VoVNet or DenseNet промена на влезната ширина на неколку слоеви кога длабочината на моделите е намалена. YOLOv7 работи на предложена архитектура базирана на конкатенација и оттука користи метод на сложено скалирање.

Сликата спомената погоре го споредува проширени ефикасни мрежи за агрегација на слоеви (Е-ЕЛАН) на различни модели. Предложениот метод E-ELAN ја одржува патеката на пренос на градиент на оригиналната архитектура, но има за цел да ја зголеми кардиналноста на додадените карактеристики користејќи групна конволуција. Процесот може да ги подобри карактеристиките научени од различни карти и дополнително да ја направи употребата на пресметките и параметрите поефикасна.
Архитектура YOLOv7
Моделот YOLOv7 ги користи моделите YOLOv4, YOLO-R и Scaled YOLOv4 како основа. YOLOv7 е резултат на експериментите извршени на овие модели за да се подобрат резултатите и да се направи моделот попрецизен.
Проширена ефикасна мрежа за агрегација на слоеви или E-ELAN
E-ELAN е основниот градежен блок на моделот YOLOv7 и е изведен од веќе постоечките модели за ефикасност на мрежата, главно од ЕЛАН.
Главните размислувања при дизајнирање на ефикасна архитектура се бројот на параметри, пресметковната густина и количината на пресметување. Други модели, исто така, ги земаат предвид факторите како што се влијанието на односот на влезно/излезниот канал, гранките во архитектурата мрежа, брзината на мрежни пречки, бројот на елементи во тензорите на конволутивната мрежа и многу повеќе.
на CSPVoNet моделот не само што ги зема предвид горенаведените параметри, туку ја анализира и патеката на градиент за да научи повеќе различни карактеристики со овозможување на тежините на различни слоеви. Пристапот овозможува пречките да бидат многу побрзи и точни. На ELAN архитектурата има за цел да дизајнира ефикасна мрежа за да ја контролира најкратката најдолга патека на градиент, така што мрежата може да биде поефикасна во учењето и конвергирање.
ELAN веќе достигна стабилна фаза без оглед на бројот на редење на пресметковните блокови и должината на патеката на градиент. Стабилната состојба може да биде уништена ако пресметковните блокови се наредени неограничено, а стапката на искористување на параметрите ќе се намали. На предложената E-ELAN архитектура може да го реши проблемот бидејќи користи проширување, мешање и спојување кардиналност за постојано подобрување на способноста за учење на мрежата додека ја задржува оригиналната патека на градиент.
Понатаму, кога се споредува архитектурата на E-ELAN со ELAN, единствената разлика е во пресметковниот блок, додека архитектурата на преодниот слој е непроменета.
E-ELAN предлага да се прошири кардиналноста на пресметковните блокови и да се прошири каналот со користење групна конволуција. Картата на карактеристики потоа ќе се пресмета и ќе се меша во групи според параметарот на групата, а потоа ќе се спои заедно. Бројот на канали во секоја група ќе остане ист како во оригиналната архитектура. На крај, групите на карти со карактеристики ќе бидат додадени за да се изврши кардиналност.
Скалирање на модели за модели базирани на конкатенација
Скалирањето на моделот помага во прилагодување на атрибутите на моделите што помага при генерирање модели според барањата и од различни размери за да се исполнат различните брзини на пречки.

Сликата зборува за скалирање на модели за различни модели базирани на конкатенација. Како што можете на сликите (а) и (б), излезната ширина на пресметковниот блок се зголемува со зголемување на скалирањето на длабочината на моделите. Како резултат на тоа, влезната ширина на слоевите на преносот е зголемена. Ако овие методи се имплементираат на архитектура заснована на конкатенација, процесот на скалирање се изведува длабински, и тоа е прикажано на слика (в).
Така, може да се заклучи дека не е можно независно да се анализираат факторите на скалирање за моделите базирани на конкатенација, туку тие мора да се разгледуваат или анализираат заедно. Затоа, за модел базиран на конкатенација, погодно е да се користи соодветниот метод на скалирање на сложениот модел. Дополнително, кога факторот на длабочина е намален, мора да се скалира и излезниот канал на блокот.
Торба со бесплатни можности за обука
Торба со гратис е термин што програмерите го користат за да го опишат збир на методи или техники кои можат да ја променат стратегијата или трошоците за обука во обид да се зголеми точноста на моделот. Значи, што се овие торби со бесплатни ливчиња што може да се обучуваат во YOLOv7? Ајде да погледнеме.
Планирано повторно параметризирана конволуција
Алгоритмот YOLOv7 користи патеки за ширење на протокот на градиент за одредување како идеално да се комбинира мрежата со повторно параметризирана конволуција. Овој пристап на YOLov7 е обид да се спротивстави Алгоритам RepConv кој иако има спокоен ефект на VGG моделот, има слаби перформанси кога се применува директно на моделите DenseNet и ResNet.
За да се идентификуваат врските во конволуционерен слој, на Алгоритмот RepConv комбинира 3×3 конволуција и 1×1 конволуција. Ако го анализираме алгоритмот, неговите перформанси и архитектурата, ќе забележиме дека RepConv го уништува конкатенација во DenseNet, а резидуалот во ResNet.

Сликата погоре прикажува планиран повторно параметризиран модел. Може да се види дека алгоритмот YOLov7 откри дека слој во мрежата со конкатенација или преостанати врски не треба да има идентитетска врска во алгоритмот RepConv. Како резултат на тоа, прифатливо е да се префрлате со RepConvN без врски со идентитетот.
Груби за помошни и парична казна за губење на олово
Длабок надзор е гранка во компјутерската наука која често наоѓа своја употреба во процесот на обука на длабоки мрежи. Основниот принцип на длабокиот надзор е дека тоа додава дополнителна помошна глава во средните слоеви на мрежата заедно со плитките мрежни тегови со губење на асистент како нејзин водич. Алгоритмот YOLOv7 се однесува на главата што е одговорна за конечниот излез како водечка глава, а помошната глава е главата што помага при обуката.
Движејќи се заедно, YOLOv7 користи различен метод за доделување етикети. Конвенционално, доделувањето етикети се користи за генерирање етикети со директно упатување на основната вистина и врз основа на даден сет на правила. Меѓутоа, во последниве години, дистрибуцијата и квалитетот на влезот за предвидување игра важна улога за генерирање на доверлива ознака. YOLOv7 генерира мека ознака на објектот со користење на предвидувањата на граничната кутија и основната вистина.
Понатаму, новиот метод за доделување етикети на алгоритмот YOLOv7 ги користи предвидувањата на главата на олово за да ги насочи и доводот и помошната глава. Методот за доделување етикети има две предложени стратегии.
Доделувач на етикети со воден раководител
Стратегијата прави пресметки врз основа на резултатите од предвидувањата на водечката глава и основната вистина, а потоа користи оптимизација за да генерира меки етикети. Овие меки етикети потоа се користат како модел за обука и за водечката глава и за помошната глава.
Стратегијата работи на претпоставката дека бидејќи главната глава има поголема способност за учење, етикетите што ги генерира треба да бидат порепрезентативни и да корелираат помеѓу изворот и целта.
Груб до фино Доделувач на етикети со водени води
Оваа стратегија, исто така, прави пресметки врз основа на резултатите од предвидувањата на водечката глава и основната вистина, а потоа користи оптимизација за да генерира меки етикети. Сепак, има една клучна разлика. Во оваа стратегија, постојат две групи на меки етикети, грубо ниво, фина етикета.
Грубата ознака се создава со релаксирање на ограничувањата на позитивниот примерок
процес на доделување кој третира повеќе мрежи како позитивни цели. Тоа е направено за да се избегне ризикот од губење на информации поради послабата сила за учење на помошната глава.

Сликата погоре ја објаснува употребата на торба со бесплатни можности за обука во алгоритмот YOLOv7. Прикажува грубо за помошната глава и фино за оловната глава. Кога ќе споредиме модел со помошна глава(б) со нормалниот модел (а), ќе забележиме дека шемата во (б) има помошна глава, додека таа не е во (а).
Сликата (в) го прикажува заедничкиот независен доделувач на етикети, додека сликата (г) и сликата (д) соодветно го претставуваат Доделувачот со водени води и Груп до фино водени олово користени од YOLOv7.
Друга торба со бесплатни можности за обука
Покрај горенаведените, алгоритмот YOLOv7 користи дополнителни вреќи со бесплатни понуди, иако тие првично не беа предложени од нив. Тие се
- Нормализација на серија во технологијата за активирање Conv-Bn: Оваа стратегија се користи за поврзување на конволутивен слој директно со слојот за нормализирање на серија.
- Имплицитно знаење во YOLOR: YOLOv7 ја комбинира стратегијата со мапата на карактеристики Convolutional.
- Модел на EMA: Моделот EMA се користи како конечен референтен модел во YOLOv7, иако неговата примарна употреба треба да се користи во методот на средна вредност на наставникот.
YOLOv7: Експерименти
Експериментално поставување
Алгоритмот YOLOv7 го користи Microsoft COCO база на податоци за обука и валидација нивниот модел за откривање на објекти и не сите овие експерименти користат претходно обучен модел. Програмерите ја користеа базата на податоци за воз за 2017 година за обука и ја користеа базата на податоци за валидација од 2017 година за избирање на хиперпараметрите. Конечно, перформансите на резултатите од откривањето објекти YOLOv7 се споредуваат со најсовремените алгоритми за откривање објекти.
Програмерите дизајнираа основен модел за Edge GPU (YOLOv7-мал), нормален GPU (YOLOv7) и cloud GPU (YOLOv7-W6). Понатаму, алгоритмот YOLOv7 исто така користи основен модел за скалирање на модели според различни барања за услуги и добива различни модели. За алгоритмот YOLOv7, скалирањето на оџакот се врши на вратот, а предложените соединенија се користат за зголемување на длабочината и ширината на моделот.
Основни линии
Алгоритмот YOLOv7 користи претходни модели на YOLO, а алгоритмот за откривање објекти YOLOR како основна линија.

Горенаведената слика ја споредува основната линија на моделот YOLOv7 со другите модели за откривање објекти, а резултатите се сосема очигледни. Кога ќе се спореди со YOLOv4 алгоритам, YOLOv7 не само што користи 75% помалку параметри, туку користи и 15% помалку пресметки и има 0.4% поголема точност.
Споредба со најсовремените модели на детектори за објекти

Горенаведената слика ги прикажува резултатите кога YOLOv7 се споредува со најсовремените модели за откривање објекти за мобилни и општи графички процесори. Може да се забележи дека методот предложен од алгоритмот YOLOv7 има најдобар резултат за размена на брзина-точност.
Студија за аблација: Предложен метод за скалирање на соединенија

Сликата прикажана погоре ги споредува резултатите од користењето различни стратегии за зголемување на моделот. Стратегијата за скалирање во моделот YOLOv7 ја зголемува длабочината на пресметковниот блок за 1.5 пати и ја намалува ширината за 1.25 пати.
Во споредба со модел кој само ја зголемува длабочината, моделот YOLOv7 има подобри перформанси за 0.5% додека користи помалку параметри и пресметковна моќ. Од друга страна, во споредба со моделите кои само ја зголемуваат длабочината, прецизноста на YOLOv7 е подобрена за 0.2%, но бројот на параметри треба да се скалира за 2.9%, а пресметката за 1.2%.
Предлог планиран повторно параметризиран модел
За да се потврди општоста на неговиот предложен повторно параметризиран модел, на Алгоритмот YOLOv7 го користи за верификација на модели базирани на резидуално и врз основа на конкатенација. За процесот на верификација, алгоритмот YOLOv7 користи 3-наредени ELAN за моделот базиран на конкатенација, и CSPDarknet за моделот базиран на преостанатост.
За моделот базиран на конкатенација, алгоритмот ги заменува 3×3 конволутивните слоеви во 3-наредениот ELAN со RepConv. Сликата подолу ја прикажува деталната конфигурација на Planned RepConv и 3-наредениот ELAN.
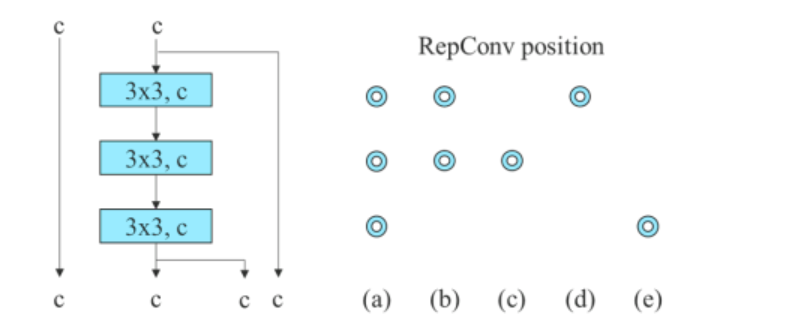
Понатаму, кога се работи со моделот заснован на резидуално, алгоритмот YOLOv7 користи обратен темен блок бидејќи оригиналниот темен блок нема конволуционен блок 3×3. Сликата подолу ја прикажува архитектурата на Reversed CSPDarknet што ги менува позициите на 3×3 и 1×1 конволуциониот слој. 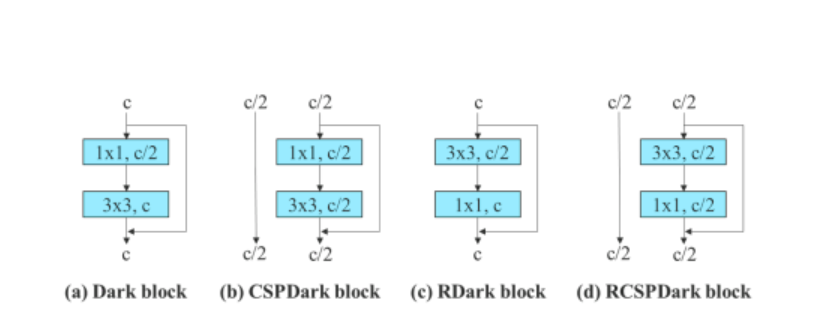
Предложена загуба на помошник за помошна глава
За губењето на помошната глава за помошна глава, моделот YOLOv7 го споредува независното доделување на етикетата за методите за помошна глава и глава на олово.

Сликата погоре ги содржи резултатите од студијата за предложената помошна глава. Може да се види дека вкупните перформанси на моделот се зголемуваат со зголемување на загубата на асистент. Понатаму, доделувањето на етикетата со водени води предложена од моделот YOLOv7 функционира подобро од независните стратегии за доделување на водечките води.
Резултати од YOLOv7
Врз основа на горенаведените експерименти, еве го резултатот од перформансите на YOLov7 во споредба со другите алгоритми за откривање објекти.

Горенаведената слика го споредува моделот YOLOv7 со другите алгоритми за откривање објекти и може јасно да се забележи дека YOLOv7 ги надминува другите модели за откривање приговори во однос на Просечна прецизност (АП) v/s серија пречки.
Понатаму, сликата подолу ги споредува перформансите на YOLOv7 v/s другите алгоритми за откривање приговори во реално време. Уште еднаш, YOLOv7 ги наследува другите модели во однос на севкупните перформанси, точноста и ефикасноста.

Еве неколку дополнителни набљудувања од резултатите и перформансите на YOLOv7.
- YOLOv7-Tiny е најмалиот модел во семејството YOLO, со над 6 милиони параметри. YOLOv7-Tiny има просечна прецизност од 35.2%, и ги надминува моделите YOLOv4-Tiny со споредливи параметри.
- Моделот YOLOv7 има над 37 милиони параметри и ги надминува моделите со повисоки параметри како YOLov4.
- Моделот YOLOv7 има највисока стапка на mAP и FPS во опсег од 5 до 160 FPS.
Заклучок
YOLO или You Only Look Once е најсовремен модел за откривање објекти во модерната компјутерска визија. Алгоритмот YOLO е познат по својата висока точност и ефикасност, и како резултат на тоа, наоѓа широка примена во индустријата за откривање објекти во реално време. Уште од воведувањето на првиот алгоритам YOLO во 2016 година, експериментите им овозможија на програмерите континуирано да го подобруваат моделот.
Моделот YOLOv7 е најновото дополнување во семејството YOLO и е најмоќниот YOLo алгоритам досега. Во оваа статија, разговаравме за основите на YOLOv7 и се обидовме да објасниме што го прави YOLOv7 толку ефикасен.















