
Вештачка интелигенција
ST-NeRF: Композитирање и уредување за видео синтеза

Кинески истражувачки конзорциум има развиена техники за да се донесат способностите за уредување и компонирање во еден од најжешките истражувачки сектори за синтеза на слики во минатата година - Neural Radiance Fields (NeRF). Системот го носи насловот ST-NeRF (Просторно-временско кохерентно невронско поле за зрачење).
Она што се чини дека е физичка тава за камерата на сликата подолу е всушност само корисникот „скролува“ низ гледиштата на видео содржините што постојат во 4D простор. POV не е заклучен за перформансите на луѓето прикажани на видеото, чии движења може да се гледаат од кој било дел од радиус од 180 степени.

Секој аспект во видеото е дискретно снимен елемент, комбиниран заедно во кохезивна сцена што може динамички да се истражи.
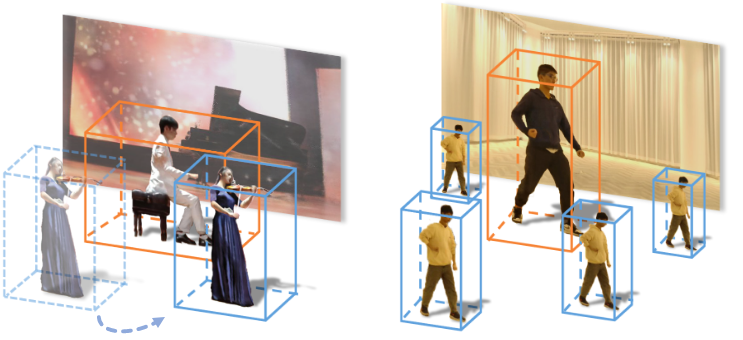
Фасетите може слободно да се дуплираат во сцената или да се преголемат:

Дополнително, временското однесување на секој аспект може лесно да се менува, успори, да се движи наназад или да се манипулира на кој било број начини, отворајќи ја патеката за филтрирање архитектури и исклучително високо ниво на интерпретабилност.

Два посебни аспекти на NeRF работат со различна брзина во иста сцена. Извор: https://www.youtube.com/watch?v=Wp4HfOwFGP4
Нема потреба да се ротоскопираат изведувачите или опкружувањата, или изведувачите да ги извршуваат своите движења слепо и надвор од контекстот на предвидената сцена. Наместо тоа, снимката се снима природно преку низа од 16 видео камери кои покриваат 180 степени:


Трите елементи прикажани погоре, двете лица и околината, се различни и се наведени само за илустративни цели. Секој може да се замени и секој може да се вметне во сцената во порана или подоцнежна точка во нивната индивидуална временска линија за снимање.
ST-NeRF е иновација за истражување во полиња со невронски зрачење (NeRF), рамка за машинско учење каде што повеќекратни снимки од гледиште се синтетизираат во виртуелен простор што може да се плови со обемна обука (иако снимањето на една гледна точка е исто така под-сектор на истражувањето на NeRF).

Полињата за невронско зрачење работат со собирање на повеќе гледишта за снимање во единствен кохерентен и пловен 3D простор, со празнините помеѓу покриеноста проценета и прикажана од невронска мрежа. Онаму каде што се користи видео (наместо неподвижни слики), потребните ресурси за рендерирање се често значителни. Извор: https://www.matthewtancik.com/nerf
Интересот за NeRF стана интензивен во последните девет месеци, а Reddit се одржува листа на деривативни или истражувачки NeRF документи моментално наведува шеесет проекти.

Само неколку од многуте изданија на оригиналната NeRF хартија. Извор: https://crossminds.ai/graphlist/nerf-neural-radiance-fields-ai-research-graph-60708936c8663c4cfa875fc2/
Достапна обука
Трудот е соработка помеѓу истражувачите од Шангајскиот Tech University и Дигитална технологија DGene, и е прифатен со одреден ентузијазам на Отворен преглед.
ST-NeRF нуди голем број иновации во однос на претходните иницијативи во пловните видео простори добиени од ML. Не помалку важно, постигнува високо ниво на реализам со само 16 камери. Иако на Фејсбук DyNeRF користи само две камери повеќе од ова, нуди многу поограничен пловен лак.

Пример за DyNeRF околина на Facebook, со поограничено поле на движење и повеќе камери по квадратен метар потребни за реконструкција на сцената. Извор: https://neural-3d-video.github.io
Покрај тоа што нема способност за уредување и составување на поединечни аспекти, DyNeRF е особено скап во однос на пресметковните ресурси. Спротивно на тоа, кинеските истражувачи наведуваат дека трошоците за обука за нивните податоци се некаде помеѓу 900-3,000 долари, во споредба со 30,000 долари за најсовремениот модел на видео генерирање DVDGAN и интензивните системи како што е DyNeRF.
Рецензентите, исто така, забележаа дека ST-NeRF прави голема иновација во одвојувањето на процесот на учење движење од процесот на синтеза на слики. Ова одвојување е она што овозможува уредување и составување, со претходните пристапи рестриктивни и линеарни во споредба.
Иако 16 камери се многу ограничена низа за таков целосен полукруг на гледање, истражувачите се надеваат дека ќе ја намалат оваа бројка дополнително во подоцнежната работа преку употреба на прокси претходно скенирани статични позадини и повеќе пристапи за моделирање сцени управувани од податоци. Тие исто така се надеваат дека ќе вклучат можности за повторно осветлување, а неодамнешна иновација во истражувањето на NeRF.
Адресирање на ограничувањата на ST-NeRF
Во контекст на академските CS трудови кои имаат тенденција да ја фрлат вистинската употребливост на новиот систем во фрлен крај, дури и ограничувањата што истражувачите ги признаваат за ST-NeRF се невообичаени.
Тие забележуваат дека системот во моментов не може да поедини и одделно да прикажува одредени предмети во сцената, бидејќи луѓето на снимката се сегментирани во поединечни ентитети преку систем дизајниран да препознава луѓе, а не предмети - проблем што изгледа лесно решен со YOLO и слично. рамки, со потешката работа за извлекување човечко видео веќе завршена.
Иако истражувачите забележуваат дека моментално не е возможно да се генерира бавно движење, се чини дека има малку за да се спречи имплементацијата на ова со користење на постоечките иновации во интерполацијата на рамки, како на пр. ДАИН РИФЕ.
Како и со сите имплементации на NeRF, и во многу други сектори на истражување на компјутерската визија, ST-NeRF може да пропадне во случаи на тешка оклузија, каде што субјектот е привремено заматен од друго лице или објект и може да биде тешко постојано да се следи или прецизно повторно стекнете потоа. Како и на друго место, оваа тешкотија можеби ќе треба да чека нагоре решенија. Во меѓувреме, истражувачите признаваат дека е неопходна рачна интервенција во овие оклудирани рамки.
Конечно, истражувачите забележуваат дека процедурите за човечка сегментација моментално се потпираат на разликите во бојата, што може да доведе до ненамерно споредување на две лица во еден сегментирање блок - камен на сопнување што не е ограничен на ST-NeRF, туку е суштински на библиотеката што се користи, и која можеби би можело да се реши со оптичка анализа на проток и други техники кои се појавуваат.
Прво објавено на 7 мај 2021 година.















