
Вештачка интелигенција
Проверка на пристрасност управувана од вештачка интелигенција за написи од вести, достапна во Python

Истражувачи од Канада, Индија, Кина и Австралија соработуваа за да произведат слободно достапен Пајтон пакет кој може ефективно да се користи за да се забележи и замени „нефер јазик“ во копијата на вестите.
Системот, насловен Дбијас, користи различни технологии и бази на податоци за машинско учење за да развие тристепен кружен работен тек што може да го усоврши пристрасен текст додека не врати непристрасна, или барем понеутрална верзија.

Вчитаниот јазик во исечок од вести идентификуван како „пристрасен“ е трансформиран во помалку запалива верзија од Dbias. Извор: https://arxiv.org/ftp/arxiv/papers/2207/2207.03938.pdf
Системот претставува еднократно и самостоен гасовод што може да биде инсталиран преку Pip од Hugging Face и интегриран во постоечки проекти како дополнителна фаза, додаток или приклучок.
Во април, слична функционалност беше имплементирана во Google Docs наиде на критики, не само поради недостатокот на уредување. Dbias, од друга страна, може да биде поселективно обучен за кој било корпус на вести што го посакува крајниот корисник, задржувајќи ја способноста да развие нарачани упатства за правичност.
Критичната разлика е во тоа што гасоводот Dbias е наменет автоматски да го трансформира „натоварениот јазик“ (зборови кои додаваат критичен слој на фактичката комуникација) во неутрален или прозаичен јазик, наместо да го учи корисникот на постојана основа. Во суштина, крајниот корисник ќе ги дефинира етичките филтри и соодветно ќе го обучи системот; во пристапот на Google Docs, системот – веројатно – го обучува корисникот, на унилатерален начин.
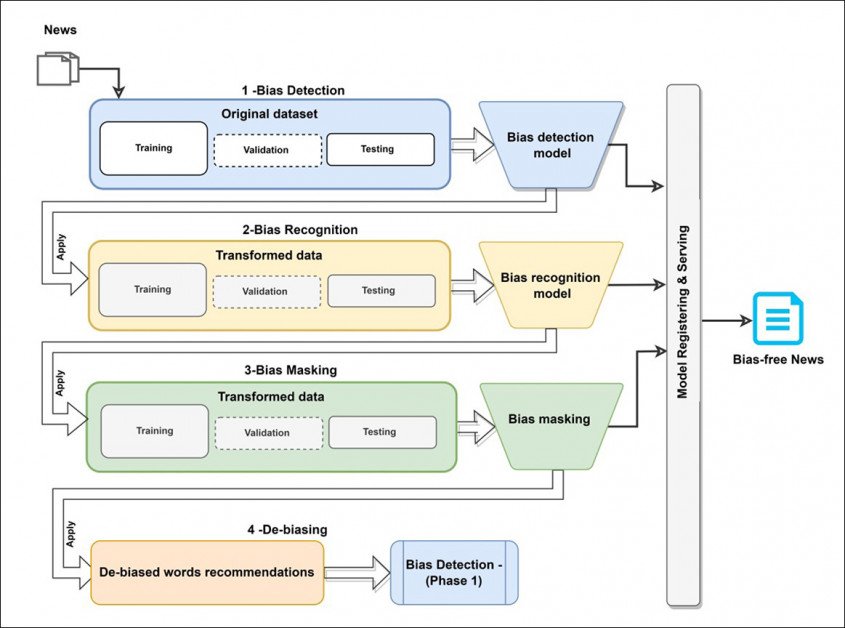
Концептуална архитектура за работниот тек на Dbias.
Според истражувачите, Dbias е првиот вистински конфигурабилен пакет за откривање пристрасност, за разлика од проектите за склопување што е на располагање, што го карактеризираа овој потсектор на обработка на природни јазици (NLP) до денес.
на нова хартија е насловен Пристап за да се обезбеди правичност во написите од вести, и доаѓа од соработници на Универзитетот во Торонто, Торонто Метрополитен универзитет, Управување со еколошки ресурси во Бангалор, Академијата на науките ДипБлу во Кина и Универзитетот во Сиднеј.
Метод
Првиот модул во Dbias е Откривање на пристрасност, што го поткрепува на ДистилБЕРТ пакет – високо оптимизирана верзија на прилично машинско интензивна на Google БЕРТ. За проектот, DistilBERT беше фино подесен на Медиумската пристрасност прибелешка (MBIC) база на податоци.

MBIC се состои од написи од вести од различни медиумски извори, вклучувајќи ги Хафингтон Пост, USA Today и MSNBC. Истражувачите ја користеа проширената верзија на сетот на податоци.
Иако оригиналните податоци беа прибележани од работници со групни извори (метод кој се најде под оган кон крајот на 2021 година), истражувачите на новиот труд беа во можност да идентификуваат дополнителни неозначени случаи на пристрасност во базата на податоци, и рачно ги додадоа. Идентификуваните случаи на пристрасност поврзани со раса, образование, етничка припадност, јазик, религија и пол.
Следниот модул, Препознавање на пристрасност, користи Именувано признавање на субјектот (NER) за да се индивидуализираат пристрасни зборови од влезниот текст. Во весникот се наведува:
„На пример, веста „Не купувајте псевдонаучна возбуда за торнада и климатски промени“ е класифицирана како пристрасна од претходниот модул за откривање пристрасност, а модулот за пристрасно препознавање сега може да го идентификува терминот „псевдонаучна возбуда“ како пристрасен збор“.
NER не е специјално дизајниран за оваа задача, но е користен пред за идентификација на пристрасност, особено за а 2021 проект од Универзитетот Дурам во Велика Британија.
За оваа фаза, истражувачите користеа РоБЕРТА во комбинација со гасоводот SpaCy English Transformer NER.

Следната фаза, Маскирање на пристрасност, вклучува нова повеќекратна маска на идентификуваните пристрасни зборови, која функционира последователно во случаи на повеќе идентификувани пристрасни зборови.

Вчитаниот јазик е заменет со прагматичен јазик во третата фаза на Dbias. Забележете дека „устањето“ и „користењето“ се еднакви на истото дејство, иако првото се смета за потсмев.
По потреба, повратните информации од оваа фаза ќе бидат испратени назад до почетокот на гасоводот за понатамошна евалуација додека не се генерираат голем број соодветни алтернативни фрази или зборови. Оваа фаза користи моделирање со маскиран јазик (МЛМ) по линии утврдени со а Соработка од 2021 година предводена од Facebook Research.
Вообичаено, задачата MLM ќе маскира 15% од зборовите по случаен избор, но работниот тек на Dbias наместо тоа му кажува на процесот да ги земе идентификуваните пристрасни зборови како влез.
Архитектурата беше имплементирана и обучена на Google Colab Pro на NVIDIA P100 со 24 GB VRAM во серија од 16, користејќи само две ознаки (пристрасно непристрасен).
Тестови
Истражувачите го тестираа Dbias против пет споредливи пристапи: LG-TFIDF со Логистичка регресија TfidfВекторизатор (TFIDF) вградување зборови; LG-ELMO; MLP-ELMO (вештачка невронска мрежа која содржи ELMO вградувања); БЕРТ; и РоБЕРТА.
Метрики користени за тестовите беа точност (ACC), прецизност (PREC), отповикување (Rec) и F1 резултат. Со оглед на тоа што истражувачите немаа знаење за кој било постоечки систем што може да ги исполни сите три задачи во една линија, беше направено ослободување за конкурентните рамки, со оценување само на примарните задачи на Dbias - откривање и препознавање на пристрасност.

Резултати од испитувањата на Dbias.
Dbias успеа да ги надмине резултатите од сите конкурентски рамки, вклучително и оние со потежок процесорски отпечаток
Во трудот се вели:
„Резултатот, исто така, покажува дека длабоките нервни вградувања, генерално, можат да ги надминат традиционалните методи на вградување (на пример, TFIDF) во задачата за класификација на пристрасност. Ова го покажува подобрите перформанси на вградувањето на длабоки невронски мрежи (т.е. ELMO) во споредба со векторизацијата TFIDF кога се користи со LG.
„Ова е веројатно затоа што длабоките нервни вградувања можат подобро да го доловат контекстот на зборовите во текстот во различни контексти. Длабоките нервни вградувања и длабоките нервни методи (MLP, BERT, RoBERTa) исто така имаат подобри резултати од традиционалниот ML метод (LG).'
Истражувачите, исто така, забележуваат дека методите базирани на трансформатори ги надминуваат конкурентните методи во откривањето на пристрасност.
Дополнителен тест вклучуваше споредба помеѓу Dbias и различните вкусови на SpaCy Core Web, вклучувајќи core-sm (мал), core-md (среден) и core-lg (голем). Дбиас можеше да го води одборот и во овие испитувања:

Истражувачите заклучуваат со набљудување дека задачите за препознавање на пристрасност генерално покажуваат подобра точност кај поголемите и поскапи модели, поради - тие шпекулираат - на зголемениот број на параметри и точки на податоци. Тие, исто така, забележуваат дека ефикасноста на идната работа на ова поле ќе зависи од поголемите напори да се прибележат висококвалитетни сетови на податоци.
Шумата и дрвјата
Се надеваме дека овој вид на ситно-грануларен проект за препознавање на пристрасност на крајот ќе биде вграден во рамки за барање пристрасност кои се способни да имаат помалку кратковиден поглед и да се земе предвид дека изборот да се покрие која било одредена приказна е само по себе чин на пристрасност што е потенцијално поттикнати од повеќе од само пријавени статистики за гледање.
Прво објавено на 14 јули 2022 година.















