Anderson's Angle
The Perils of Using Quotations to Authenticate NLG Content

Opinion Natural Language Generation models such as GPT-3 are prone to ‘hallucinate’ material that they present in the context of factual information. In an era that’s extraordinarily concerned with the growth of text-based fake news, these ‘eager to please’ flights of fancy represent an existential hurdle for the development of automated writing and summary systems, and for the future of AI-driven journalism, among various other sub-sectors of Natural Language Processing (NLP).
The central problem is that GPT-style language models derive key features and classes from very large corpora of training texts, and learn to use these features as building blocks of language adroitly and authentically, irrespective of the generated content’s accuracy, or even its acceptability.
NLG systems therefore currently rely on human verification of facts in one of two approaches: that the models are either used as seed text-generators that are immediately passed to human users, either for verification or some other form of editing or adaptation; or that humans are used as expensive filters to improve the quality of datasets intended to inform less abstractive and ‘creative’ models (which in themselves are inevitably still difficult to trust in terms of factual accuracy, and which will require further layers of human oversight).
Old News and Fake Facts
Natural Language Generation (NLG) models are capable of producing convincing and plausible output because they have learned semantic architecture, rather than more abstractly assimilating the actual history, science, economics, or any other topic on which they might be required to opine, which are effectively entangled as ‘passengers’ in the source data.
The factual accuracy of the information that NLG models generate assumes that the input on which they are trained is in itself reliable and up-to-date, which presents an extraordinary burden in terms of pre-processing and further human-based verification – a costly stumbling block that the NLP research sector is currently addressing on many fronts.
GPT-3-scale systems take an extraordinary amount of time and money to train, and, once trained, are difficult to update at what might be considered the ‘kernel level’. Though session-based and user-based local modifications can increase the utility and accuracy of the implemented models, these useful benefits are difficult, sometimes impossible to pass back to the core model without necessitating full or partial retraining.
For this reason, it’s difficult to create trained language models that can make use of the latest information.

Trained prior even to the advent of COVID, text-davinci-002 – the iteration of GPT-3 considered ‘most capable’ by its creator OpenAI – can process 4000 tokens per request, but knows nothing of COVID-19 or the 2022 Ukrainian incursion (these prompts and responses are from 5th April 2022). Interestingly, ‘unknown’ is actually an acceptable answer in both failure cases, but further prompts easily establish that GPT-3 is ignorant of these events. Source: https://beta.openai.com/playground
A trained model can only access ‘truths’ that it internalized at training time, and it is difficult to get an accurate and pertinent quote by default, when attempting to get the model to verify its claims. The real danger of obtaining quotes from default GPT-3 (for instance) is that it sometimes produces correct quotes, leading to a false confidence in this facet of its capabilities:

Top, three accurate quotes obtained by 2021-era davinci-instruct-text GPT-3. Center, GPT-3 fails to cite one of Einstein’s most famous quotes (“God does not play dice with the universe”), despite a non-cryptic prompt. Bottom, GPT-3 assigns a scandalous and fictitious quote to Albert Einstein, apparently overspill from earlier questions about Winston Churchill in the same session. Source: The author’s own 2021 article at https://www.width.ai/post/business-applications-for-gpt-3
GopherCite
Hoping to address this general shortcoming in NLG models, Google’s DeepMind recently proposed GopherCite, a 280-billion parameter model that’s capable of citing specific and accurate evidence in support of its generated responses to prompts.



Three examples of GopherCite backing up its claims with real quotations. Source: https://arxiv.org/pdf/2203.11147.pdf
GopherCite leverages reinforcement learning from human preferences (RLHP) to train query models capable of citing real quotations as supporting evidence. The quotations are drawn live from multiple document sources obtained from search engines, or else from a specific document provided by the user.
The performance of GopherCite was measured through human evaluation of model responses, which were found to be ‘high quality’ 80% of the time on Google’s NaturalQuestions dataset, and 67% of the time on the ELI5 dataset.
Quoting Falsehoods
However, when tested against Oxford University’s TruthfulQA benchmark, GopherCite’s responses were rarely scored as truthful, in comparison to the human-curated ‘correct’ answers.
The authors suggest that this is because the concept of ‘supported answers’ does not in any objective way help to define truth in itself, since the usefulness of source quotes may be compromised by other factors, such as the possibility that the author of the quote is themselves ‘hallucinating’ (i.e. writing about fictional worlds, producing advertising content, or otherwise fantasticating inauthentic material.



GopherCite cases where plausibility does not necessarily equate to ‘truth’.
Effectively, it becomes necessary to distinguish between ‘supported’ and ‘true’ in such cases. Human culture is currently far in advance of machine learning in terms of the use of methodologies and frameworks designed to obtain objective definitions of truth, and even there, the native state of ‘important’ truth seems to be contention and marginal denial.
The problem is recursive in NLG architectures that seek to devise definitive ‘corroborating’ mechanisms: human-led consensus is pressed into service as a benchmark of truth through outsourced, AMT-style models where the human evaluators (and those other humans that mediate disputes between them) are in themselves partial and biased.
For example, the initial GopherCite experiments use a ‘super rater’ model to choose the best human subjects to evaluate the model’s output, selecting only those raters who scored at least 85% in comparison to a quality assurance set. Finally, 113 super-raters were selected for the task.
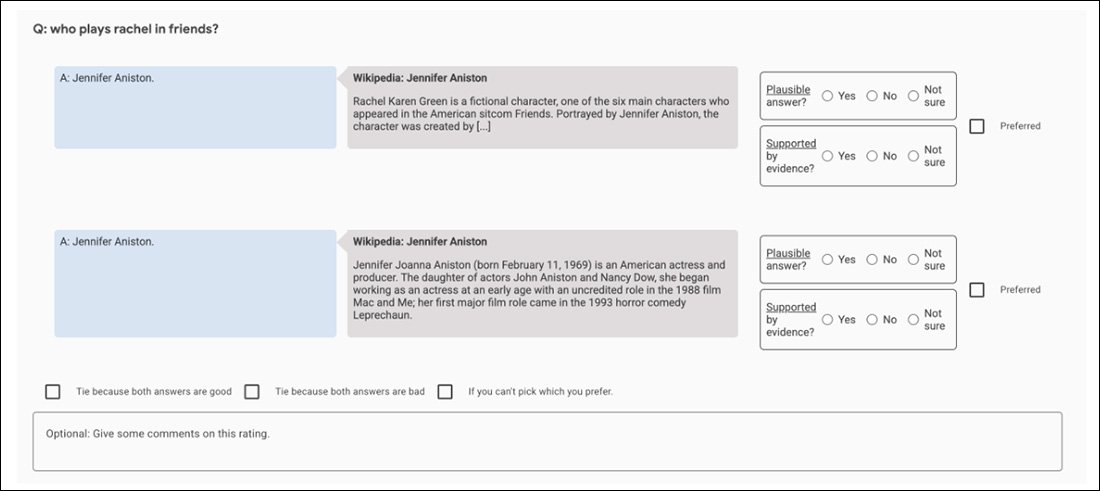
Screenshot of the comparison app used to help evaluate GopherCite’s output.
Arguably, this is a perfect picture of an unwinnable fractal pursuit: the quality assurance set used to rate the raters is in itself another ‘human-defined’ metric of truth, as is the Oxford TruthfulQA set against which GopherCite has been found wanting.
In terms of supported and ‘authenticated’ content, all that NLG systems can hope to synthesize from training on human data is human disparity and diversity, in itself an ill-posed and unsolved problem. We have an innate tendency to quote sources that support our viewpoints, and to speak authoritatively and with conviction in cases where our source information may be out of date, entirely inaccurate, or else deliberately misrepresented in other ways; and a disposition to diffuse these viewpoints directly into the wild, at a scale and efficacy unsurpassed in human history, straight into the path of the knowledge-scraping frameworks that feed new NLG frameworks.
Therefore the danger entailed in the development of citation-supported NLG systems seems bound up with the unpredictable nature of the source material. Any mechanism (such as direct citation and quotes) that increases user confidence in NLG output is, at the current state of the art, adding dangerously to the authenticity, but not the veracity of the output.
Such techniques are likely to be useful enough when NLP finally recreates the fiction-writing ‘kaleidoscopes’ of Orwell’s Nineteen Eighty-Four; but they represent a perilous pursuit for objective document analysis, AI-centered journalism, and other possible ‘non-fiction’ applications of machine summary and spontaneous or guided text generation.
First published 5th April 2022. Updated 3:29pm EET to correct term.












