Artificial Intelligence
Supercharging Large Language Models with Multi-token Prediction
By
Aayush Mittal Mittal
Large language models (LLMs) like GPT, LLaMA, and others have taken the world by storm with their remarkable ability to understand and generate human-like text. However, despite their impressive capabilities, the standard method of training these models, known as “next-token prediction,” has some inherent limitations.
In next-token prediction, the model is trained to predict the next word in a sequence given the preceding words. While this approach has proven successful, it can lead to models that struggle with long-range dependencies and complex reasoning tasks. Moreover, the mismatch between the teacher-forcing training regime and the autoregressive generation process during inference can result in suboptimal performance.
A recent research paper by Gloeckle et al. (2024) from Meta AI introduces a novel training paradigm called “multi-token prediction” that aims to address these limitations and supercharge large language models. In this blog post, we’ll dive deep into the core concepts, technical details, and potential implications of this groundbreaking research.
Single-token Prediction: The Conventional Approach
Before delving into the details of multi-token prediction, it’s essential to understand the conventional approach that has been the workhorse of large language model training for years – single-token prediction, also known as next-token prediction.
The Next-token Prediction Paradigm
In the next-token prediction paradigm, language models are trained to predict the next word in a sequence given the preceding context. More formally, the model is tasked with maximizing the probability of the next token xt+1, given the previous tokens x1, x2, …, xt. This is typically done by minimizing the cross-entropy loss:
L = -Σt log P(xt+1 | x1, x2, …, xt)
This simple yet powerful training objective has been the foundation of many successful large language models, such as GPT (Radford et al., 2018), BERT (Devlin et al., 2019), and their variants.
Teacher Forcing and Autoregressive Generation
Next-token prediction relies on a training technique called “teacher forcing” where the model is provided with the ground truth for each future token during training. This allows the model to learn from the correct context and target sequences, facilitating more stable and efficient training.
However, during inference or generation, the model operates in an autoregressive manner, predicting one token at a time based on the previously generated tokens. This mismatch between the training regime (teacher forcing) and the inference regime (autoregressive generation) can lead to potential discrepancies and suboptimal performance, especially for longer sequences or complex reasoning tasks.
Limitations of Next-token Prediction
While next-token prediction has been remarkably successful, it also has some inherent limitations:
- Short-term Focus: By only predicting the next token, the model may struggle to capture long-range dependencies and the overall structure and coherence of the text, potentially leading to inconsistencies or incoherent generations.
- Local Pattern Latching: Next-token prediction models can latch onto local patterns in the training data, making it challenging to generalize to out-of-distribution scenarios or tasks that require more abstract reasoning.
- Reasoning Capabilities: For tasks that involve multi-step reasoning, algorithmic thinking, or complex logical operations, next-token prediction may not provide sufficient inductive biases or representations to support such capabilities effectively.
- Sample Inefficiency: Due to the local nature of next-token prediction, models may require larger training datasets to acquire the necessary knowledge and reasoning skills, leading to potential sample inefficiencies.
These limitations have motivated researchers to explore alternative training paradigms, such as multi-token prediction, which aims to address some of these shortcomings and unlock new capabilities for large language models.
By contrasting the conventional next-token prediction approach with the novel multi-token prediction technique, readers can better appreciate the motivation and potential benefits of the latter, setting the stage for a deeper exploration of this groundbreaking research.
What is Multi-token Prediction?
The key idea behind multi-token prediction is to train language models to predict multiple future tokens simultaneously, rather than just the next token. Specifically, during training, the model is tasked with predicting the next n tokens at each position in the training corpus, using n independent output heads operating on top of a shared model trunk.
For example, with a 4-token prediction setup, the model would be trained to predict the next 4 tokens at once, given the preceding context. This approach encourages the model to capture longer-range dependencies and develop a better understanding of the overall structure and coherence of the text.
A Toy Example
To better understand the concept of multi-token prediction, let’s consider a simple example. Suppose we have the following sentence:
“The quick brown fox jumps over the lazy dog.”
In the standard next-token prediction approach, the model would be trained to predict the next word given the preceding context. For instance, given the context “The quick brown fox jumps over the,” the model would be tasked with predicting the next word, “lazy.”
With multi-token prediction, however, the model would be trained to predict multiple future words at once. For example, if we set n=4, the model would be trained to predict the next 4 words simultaneously. Given the same context “The quick brown fox jumps over the,” the model would be tasked with predicting the sequence “lazy dog .” (Note the space after “dog” to indicate the end of the sentence).
By training the model to predict multiple future tokens at once, it is encouraged to capture long-range dependencies and develop a better understanding of the overall structure and coherence of the text.
Technical Details
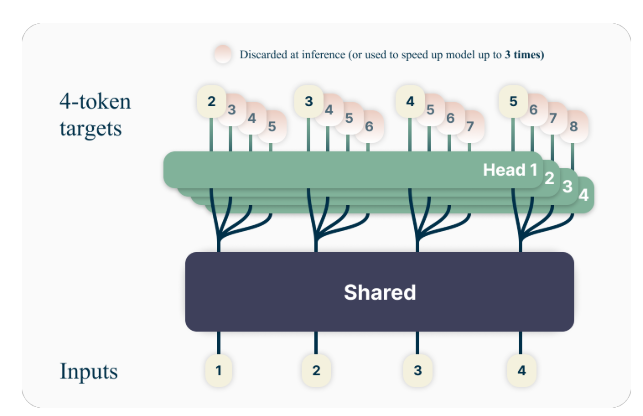
The authors propose a simple yet effective architecture for implementing multi-token prediction. The model consists of a shared transformer trunk that produces a latent representation of the input context, followed by n independent transformer layers (output heads) that predict the respective future tokens.
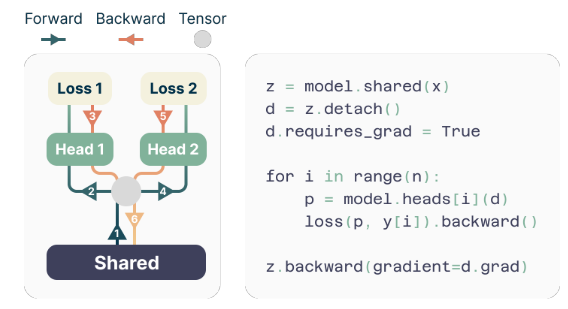
During training, the forward and backward passes are carefully orchestrated to minimize the GPU memory footprint. The shared trunk computes the latent representation, and then each output head sequentially performs its forward and backward pass, accumulating gradients at the trunk level. This approach avoids materializing all logit vectors and their gradients simultaneously, reducing the peak GPU memory usage from O(nV + d) to O(V + d), where V is the vocabulary size and d is the dimension of the latent representation.
The Memory-efficient Implementation
One of the challenges in training multi-token predictors is reducing their GPU memory utilization. Since the vocabulary size (V) is typically much larger than the dimension of the latent representation (d), logit vectors become the GPU memory usage bottleneck.
To address this challenge, the authors propose a memory-efficient implementation that carefully adapts the sequence of forward and backward operations. Instead of materializing all logits and their gradients simultaneously, the implementation sequentially computes the forward and backward passes for each independent output head, accumulating gradients at the trunk level.
This approach avoids storing all logit vectors and their gradients in memory simultaneously, reducing the peak GPU memory utilization from O(nV + d) to O(V + d), where n is the number of future tokens being predicted.
Advantages of Multi-token Prediction
The research paper presents several compelling advantages of using multi-token prediction for training large language models:
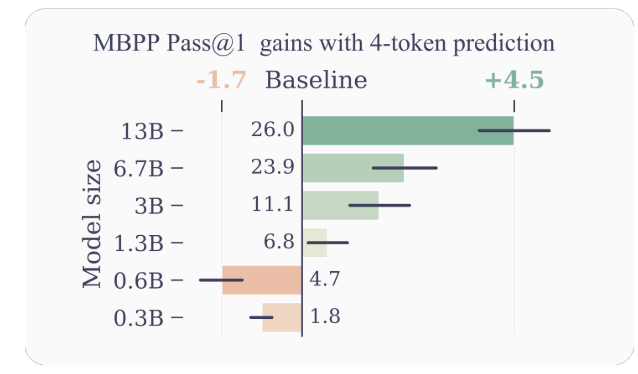
- Improved Sample Efficiency: By encouraging the model to predict multiple future tokens at once, multi-token prediction drives the model towards better sample efficiency. The authors demonstrate significant improvements in performance on code understanding and generation tasks, with models up to 13B parameters solving around 15% more problems on average.
- Faster Inference: The additional output heads trained with multi-token prediction can be leveraged for self-speculative decoding, a variant of speculative decoding that allows for parallel token prediction. This results in up to 3x faster inference times across a wide range of batch sizes, even for large models.
- Promoting Long-range Dependencies: Multi-token prediction encourages the model to capture longer-range dependencies and patterns in the data, which is particularly beneficial for tasks that require understanding and reasoning over larger contexts.
- Algorithmic Reasoning: The authors present experiments on synthetic tasks that demonstrate the superiority of multi-token prediction models in developing induction heads and algorithmic reasoning capabilities, especially for smaller model sizes.
- Coherence and Consistency: By training the model to predict multiple future tokens simultaneously, multi-token prediction encourages the development of coherent and consistent representations. This is particularly beneficial for tasks that require generating longer, more coherent text, such as storytelling, creative writing, or generating instructional manuals.
- Improved Generalization: The authors’ experiments on synthetic tasks suggest that multi-token prediction models exhibit better generalization capabilities, especially in out-of-distribution settings. This is potentially due to the model’s ability to capture longer-range patterns and dependencies, which can help it extrapolate more effectively to unseen scenarios.

Examples and Intuitions
To provide more intuition on why multi-token prediction works so well, let’s consider a few examples:
- Code Generation: In the context of code generation, predicting multiple tokens simultaneously can help the model understand and generate more complex code structures. For instance, when generating a function definition, predicting just the next token might not provide enough context for the model to generate the entire function signature correctly. However, by predicting multiple tokens at once, the model can better capture the dependencies between the function name, parameters, and return type, leading to more accurate and coherent code generation.
- Natural Language Reasoning: Consider a scenario where a language model is tasked with answering a question that requires reasoning over multiple steps or pieces of information. By predicting multiple tokens simultaneously, the model can better capture the dependencies between the different components of the reasoning process, leading to more coherent and accurate responses.
- Long-form Text Generation: When generating long-form text, such as stories, articles, or reports, maintaining coherence and consistency over an extended period can be challenging for language models trained with next-token prediction. Multi-token prediction encourages the model to develop representations that capture the overall structure and flow of the text, potentially leading to more coherent and consistent long-form generations.
Limitations and Future Directions
While the results presented in the paper are impressive, there are a few limitations and open questions that warrant further investigation:
- Optimal Number of Tokens: The paper explores different values of n (the number of future tokens to predict) and finds that n=4 works well for many tasks. However, the optimal value of n may depend on the specific task, dataset, and model size. Developing principled methods for determining the optimal n could lead to further performance improvements.
- Vocabulary Size and Tokenization: The authors note that the optimal vocabulary size and tokenization strategy for multi-token prediction models may differ from those used for next-token prediction models. Exploring this aspect could lead to better trade-offs between compressed sequence length and computational efficiency.
- Auxiliary Prediction Losses: The authors suggest that their work could spur interest in developing novel auxiliary prediction losses for large language models, beyond the standard next-token prediction. Investigating alternative auxiliary losses and their combinations with multi-token prediction is an exciting research direction.
- Theoretical Understanding: While the paper provides some intuitions and empirical evidence for the effectiveness of multi-token prediction, a deeper theoretical understanding of why and how this approach works so well would be valuable.
Conclusion
The research paper “Better & Faster Large Language Models via Multi-token Prediction” by Gloeckle et al. introduces a novel training paradigm that has the potential to significantly improve the performance and capabilities of large language models. By training models to predict multiple future tokens simultaneously, multi-token prediction encourages the development of long-range dependencies, algorithmic reasoning abilities, and better sample efficiency.
The technical implementation proposed by the authors is elegant and computationally efficient, making it feasible to apply this approach to large-scale language model training. Furthermore, the ability to leverage self-speculative decoding for faster inference is a significant practical advantage.
While there are still open questions and areas for further exploration, this research represents an exciting step forward in the field of large language models. As the demand for more capable and efficient language models continues to grow, multi-token prediction could become a key component in the next generation of these powerful AI systems.
I have spent the past five years immersing myself in the fascinating world of Machine Learning and Deep Learning. My passion and expertise have led me to contribute to over 50 diverse software engineering projects, with a particular focus on AI/ML. My ongoing curiosity has also drawn me toward Natural Language Processing, a field I am eager to explore further.

You may like
-


The GPU Wall is Cracking: The Unseen Revolution in Post-Transformer Architectures
-


Google NotebookLM Introduces Deep Research Feature
-


Meta Chief AI Scientist Yann LeCun Plans Startup Exit
-


How to Sneak Absurd Scientific Papers Past AI Reviewers
-


The ‘Survey Paper DDos Attack’ That’s Overwhelming Scientific Research
-


AI Models Prefer Human Writing to AI-Generated Writing











