Artificial Intelligence
Engineers Develop Energy-Efficient “Early Bird” Method to Train Deep Neural Networks
Engineers at Rice University have developed a new method for training deep neural networks (DNNs) with a fraction of the energy normally required. DNNs are the form of artificial intelligence (AI) that plays a key role in the development of technologies such as self-driving cars, intelligent assistants, facial recognition, and other applications.
Early Bird was detailed in a paper on April 29 by researchers from Rice and Texas A&M University. It took place at the International Conference on Learning Representations, or ICLR 2020.
The study’s lead authors were Haoran You and Chaojian Li from Rice’s Efficient and Intelligent Computing (EIC) Lab. In one study, they demonstrated how the method could train a DNN at the same level and accuracy as today’s methods, but using 10.7 times less energy.
The research was led by EIC Lab director Yingyan Lin, Rice’s Richard Baraniuk, and Texas A&M’s Zhangyang Wang. Other co-authors include Pengfei Xu, Yonggan Fu, Yue Wang, and Xiaohan Chen.
“A major driving force in recent AI breakthroughs is the introduction of bigger, more expensive DNNs,” Lin said. “But training these DNNs demands considerable energy. For more innovations to be unveiled, it is imperative to find ‘greener’ training methods that both address environmental concerns and reduce financial barriers of AI research.”
Expensive to Train DNNs
It can be very expensive to train the world’s best DNNs, and the price-tag continues to increase. In 2019, a study led by the Allen Institute for AI in Seattle found that in order to train a top-flight deep neural network, 300,000 times more computations are needed compared to 2012-2018. Another 2019 study, this time led by researchers at the University of Massachusetts Amherst, found that by training a single, elite DNN, about the same amount of carbon dioxide emissions are released as five U.S. automobiles.
In order for DNNs to perform their highly specialized tasks, they consist of at least millions of artificial neurons. They are capable of learning how to make decisions, sometimes outperforming humans, by observing large numbers of examples. They can do this without needing explicit programming.
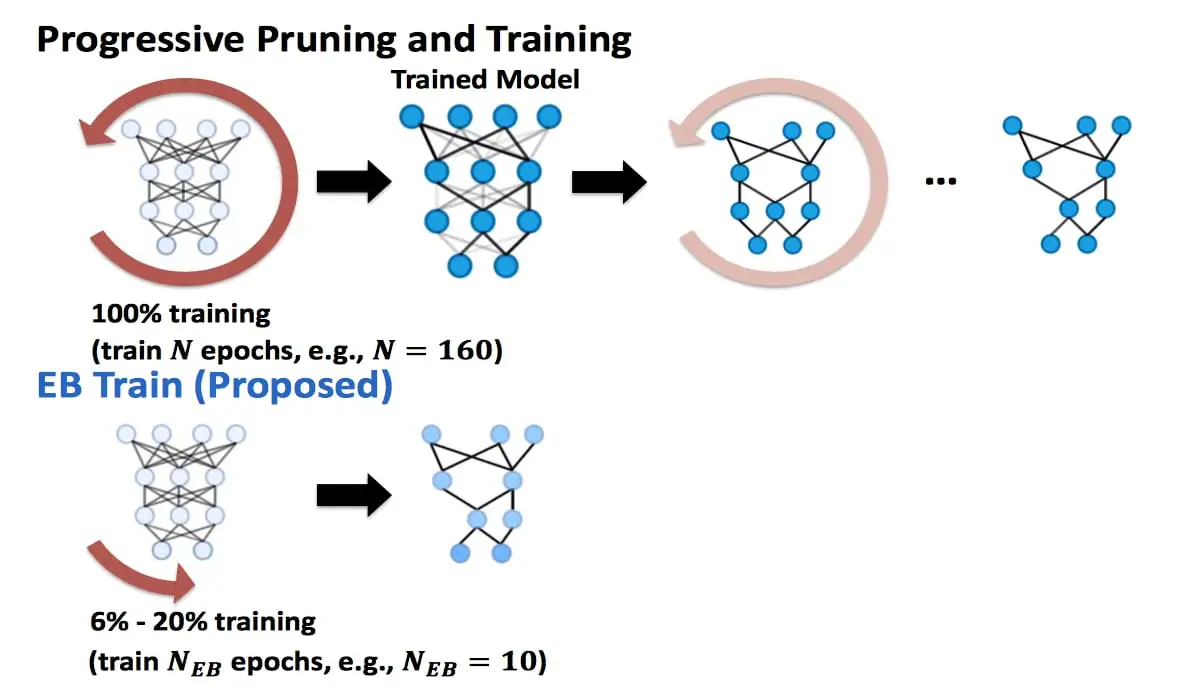
Prune and Train
Lin is an assistant professor of electrical and computer engineering in Rice’s Brown School of Engineering.
“The state-of-art way to perform DNN training is called progressive prune and train,” Lin said. “First, you train a dense, giant network, then remove parts that don’t look important — like pruning a tree. Then you retrain the pruned network to restore performance because performance degrades after pruning. And in practice you need to prune and retrain many times to get good performance.”
This method is used since not all of the artificial neurons are needed to complete the specialized task. The connections between neurons are fortified due to the training, and others can be discarded. This pruning method cuts computational costs and reduces model size, which makes fully trained DNNs more affordable.
“The first step, training the dense, giant network, is the most expensive,” Lin said. “Our idea in this work is to identify the final, fully functional pruned network, which we call the ‘early-bird ticket,’ in the beginning stage of this costly first step.”
The researchers do this by looking for key network connectivity patterns, and they were able to discover these early-bird tickets. This allowed them to quicken the DNN training.
Early Bird in the Beginning Phase of Training
Lin and the other researchers found that Early Bird could appear one-tenth or less of the way through the beginning phase of training.
“Our method can automatically identify early-bird tickets within the first 10% or less of the training of the dense, giant networks,” Lin said. “This means you can train a DNN to achieve the same or even better accuracy for a given task in about 10% or less of the time needed for traditional training, which can lead to more than one order savings in both computation and energy.”
Besides being faster and more energy-efficient, the researchers have a strong focus on environmental impact.
“Our goal is to make AI both more environmentally friendly and more inclusive,” she said. “The sheer size of complex AI problems has kept out smaller players. Green AI can open the door enabling researchers with a laptop or limited computational resources to explore AI innovations.”
The research received support from the National Science Foundation.












