Anderson's Angle
Assessing Carbon Capture in Trees With Machine Learning

New research from IBM aims to quantify the extent to which trees capture carbon and improve the environment, using just aerial imagery and available LiDAR data. The method is intended to evaluate how far tree-planting initiatives offset carbon emissions, and to provide a workable matrix for quantifying the value of the tree-planting schemes that are increasingly being used by companies and municipal authorities as a counterbalance to the negative effects of existing and proposed infrastructure, development, and other carbon-producing activities.
To demonstrate the new methodology, the paper – by IBM researchers Levente Klein, Conrad Albrecht and Wang Zhou – evaluates remote imagery for New York’s Manhattan district, and calculates that the trees that inhabit this area represent 52,000 tons of sequestered carbon.

Estimated carbon capture for the West Side of New York’s Manhattan area. Source: https://arxiv.org/pdf/2106.00182.pdf
The emerging carbon trading market is currently served by a variety of methods to estimate carbon off-set. The diverse models used are difficult to compare, since they don’t share common metrics or methods. Additionally, many of the models extrapolate principles from small study areas to what may be an overly-broad application to other areas, which may not share the same characteristics, or yield the same estimate of carbon benefits.
Furthermore, many of the more granular and less generic methodologies require notable investment in monitoring technologies and schedules, which exacerbates the temptation to base widespread statistical models on very small-scale analysis areas, risking imprecise or deceptive results.
Ground And Air Tree Monitoring
Instead, the IBM paper proposes a two-fold approach to identifying the species and biomass of trees: firstly, computer vision analysis techniques that can derive the species of a tree from aerial photos; and secondly, the correlation of this information with LiDAR data, capable of adding height, width and volume estimates to the ‘flat’ imagery extracted from the aerial imagery.
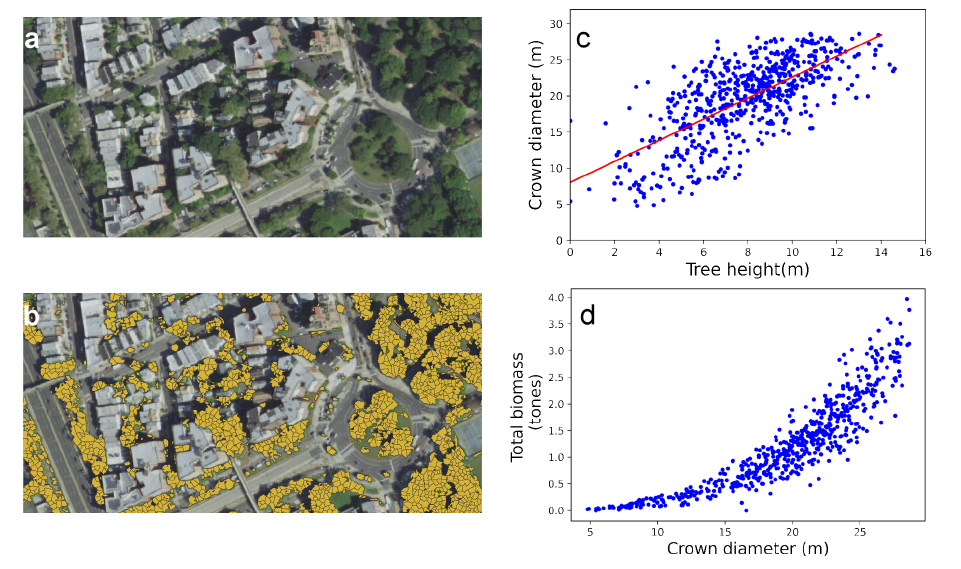
In the top-left of the image above, we see multispectral photos provided by the US National Agriculture Imagery Program (NAIP); Top right, segmentation data for the trees identified in the images; bottom left, the allometric relationship between tree crown diameter and tree height as established by prior LiDAR data; and bottom right, estimated total biomass for the area covered in the image.
The use of LiDAR to map tree height is widespread, and is even implementable via recent native functionality in Apple’s iOS.

Using iOS native LiDAR in an app to measure arboreal height. Source: https://www.youtube.com/watch?v=k5DNlvq2hdE

LiDAR mapping of trees. Source: https://towardsdatascience.com/applications-of-lidar-in-forestry-13686e1b15a7
However, mapping trees with LiDAR is expensive, so the IBM project used LiDAR data acquired for Staten Borough during the 2017 New York City LiDAR Capture initiative, together with tree species data acquired for all five boroughs for a 2015 data project, which identified 689,227 trees in the area surveyed, covering 234 tree species.
Evaluating Carbon Load Of NYC Trees
The estimated carbon capacity of a typical tree is around 50% of its total biomass, and for the exemplary analysis, the IBM project considered only the top four species identified from the NAIP multispectral images.

Storage capacity of the predominant tree species in NYC.
Linear regression was used to generate a training data set, based on the estimated tree height canopy (LiDAR) and the tree diameter (NAIP). The carbon capacity of different tree species was taken into account in the final calculations, which find that the trees in the urban forest of Manhattan borough account for 52,000 of stored carbon.
Creating A Consistent Arboreal Carbon Capture Model For The Future
The generation of consistent year-on-year statistics remains a problem, considering the current lack of a general standard for evaluating carbon capacity in trees. The researchers propose this methodology as a possible future standard, and the method could be applied and refined by further studies that either make use of existing LiDAR data in other municipalities or else gather data specifically for that end.
Initiatives such as Glasgow’s project to offset carbon emissions by planting 18 million urban trees would be of greater benefit to similar national and international research and statistical analysis efforts if such a standard could be established. Arguably, it would be better to have an affordable and easily implementable standard with wide applicability and acceptable accuracy, than the current Babel of diverse measurement protocols, or the use of protocols that may provide higher levels of accuracy, but would also require greater levels of funding.












