Artificial Intelligence
Business Anomalies: Preventing Fraud with Anomaly Detection

Anomaly Detection with MIDAS
Anomaly Detection has become one of the most useful machine learning tools of the past five years. It can be used from fraud to quality control. Is it possible to isolate fraudsters in online review websites? Can fraudulent financial transactions be detected as they occur? Can live sensor data inform about power grid failures before they happen?
Anomaly detection provides answers to questions like these. Identifying anomalies in data is a vital data understanding task. By exposing large datasets to machine learning tools and statistical methods, normal patterns in data can be learned. When inconsistent events occur, anomaly detection algorithms can isolate abnormal behavior and flag any events that do not correspond to the learned patterns. Such functionality is crucial in many business use-cases. Anomaly detection enables applications in a large number of sectors, from security to finance and IoT monitoring.
Web-scale graphs are nowadays ubiquitous and are a common representation of big data structures. They power both online and offline applications. A few online examples are large social networks, product recommendation engines, and financial transaction graphs. In the offline: road networks, IoT platforms and voltage sensors in electrical power grids are all sources of large amounts of graph-like data. Having data represented as graphs brings both benefits and challenges to the owners of said datasets. On the one hand, it allows representing data points and their relationships in a multi-dimensional space. On the other hand, scalable algorithms for data analysis and interpretation are needed. This has led to an increased research focus on methods such as anomaly detection on graph data.
Let us take a closer look at a state-of-the-art algorithm developed for anomaly detection in dynamic graph data.
MIDAS
Microcluster-Based Detector of Anomalies in Edge Streams (MIDAS) is an algorithm that tackles anomaly detection on dynamic graph data. It has been developed by researchers at the National University of Singapore who claim that their method outperforms state-of-the-art approaches. Their method alleviates the most common shortcoming of previous anomaly detection implementations:
Below is the new baseline for anomaly detection developed by Siddarth Bhatia and his team at the University of Singapore
Introducing MIDAS: A New Baseline for Anomaly Detection in Graphs. Image Source: Blog
Representing the data as a static graph
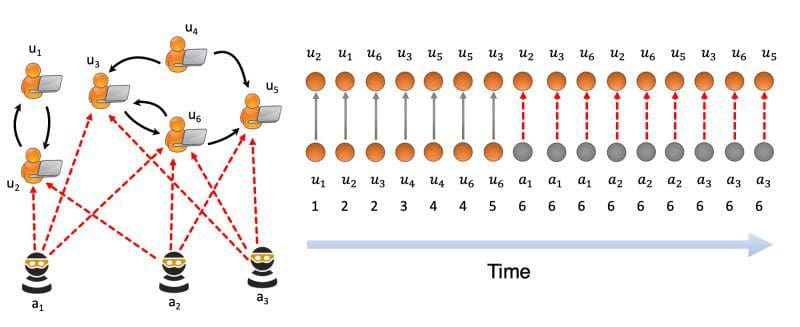
Static graphs contain only connectivity information and ignore temporal information. They are also known as graph snapshots and can only be used for spotting unusual graph entities (e.g. suspicious nodes, edges or subgraphs). However, for many practical applications, the temporal aspect is equally important: it is relevant to know when the graph structure has changed. To illustrate, in a static graph representing network traffic stream, an edge only informs that there is a connection between a source IP address and a destination IP address. But the temporal description of the edge is missing and therefore the time when the two addresses connected is unknown. Since static graphs could not model such temporal information, anomaly detection methods built on top of such graphs provide only limited support for real-world applications.
On the other hand, MIDAS handles data stored in a dynamic graph. Each of the elements in the graph has an associated timestamp, representing the time when that element was added to the graph. Following up on the example above, a dynamic network traffic graph would also inform about when a connection between two IP addresses occurred. The timestamp changes whenever an existing edge or node is updated, or when new edges are added to the graph. As such, dynamic graphs are a time-evolving structure that better fits many real-world applications, which are dynamic in nature. They make it possible to use both connectivity and time information for the detection of suspicious graph elements. Based on that capability, MIDAS can detect anomalies in real-time and thus offers support for many business use-cases.
MIDAS is optimized to work on dynamic graph data. As we’ve seen above, dynamic graphs make it possible to represent time-varying data. However, this also means that the graph structure itself also changes over time. This introduces certain challenges for the anomaly detection algorithms that aim to use this data in real-time applications. One example is the scalability of the method with regards to changing graph characteristics. Given the large data volumes corresponding to some applications, algorithms need to be linearly scalable to the size of the graph. MIDAS runs in an online fashion and processes each edge in constant time and constant memory. The authors also report that the algorithm runs “162-633 times faster than state-of-the-art approaches”. This makes the algorithm suitable for real-time applications, where the processing of high volume data streams is necessary.
Which business use-cases need MIDAS?
To gain a little insight into anomaly detection being utilized in today’s business world we interviewed Canada based cryptocurrency provider, NDAX. NDAX uses anomaly detection within three areas of their business. General business operations, the marketing department, and the compliance team. Anomaly detection helps identify bugs, which allows them to improve website performance and client onboarding process. It also allows them to provide guidance to software development and back-office operation teams on how to resolve those issues. Website traffic is another area that can leverage the power of anomaly detection. Understanding the outliers in website traffic gives insight and better understanding to the marking team, which allows them to identify if a marketing campaign is working or not. Thus giving a clearer picture of which area is the most important to concentrate their efforts. Our last example is how client sign up anomaly helps the compliance team to identify potential fraud and reduce client risk.
In our discussion with NDAX Chief Compliance Officer, Julia Baranovskaya highlights how anomaly detection’s importance has been emphasized during the current pandemic. There has been a 300% increase in fraud detected in the past few months. Desperate times combined with high online traffic invites scams of all sorts that target the unemployed and elderly. With anomaly detection, we are now able to turn these outliers into indicators of fraud or trends. The following graph shows how fraud has fluctuated during the front half of this year.
NDAX found an increase in fraud in Q2, especially scams involving the elderly and fake job postings.
What About Your Business?
Anomaly detection algorithms can help businesses identify and react to unusual data points in multiple scenarios. A bank security system may employ anomaly detection for the identification of fraudulent transactions. Likewise, manufacturing plant owners rely on anomaly detection for dealing with malfunctioning equipment and implementing predictive maintenance measures. In IoT sensor networks, anomaly detection is used as part of condition monitoring solutions and for the prevention of undesired malware deployment. The bottom point is clear: businesses that have access to large amounts of data can employ MIDAS (and other anomaly detection algorithms) in order to identify unusual patterns in real-time.
How is your data structured and how could we help you set up a modern anomaly detection solution?
Drop us a line and let us know. The Blue Orange Digital data science team is happy to make anomaly detection work for your benefit too!
main image source: Canva












