Artificial Intelligence
Direct Preference Optimization: A Complete Guide

Aligning large language models (LLMs) with human values and preferences is challenging. Traditional methods, such as Reinforcement Learning from Human Feedback (RLHF), have paved the way by integrating human inputs to refine model outputs. However, RLHF can be complex and resource-intensive, requiring substantial computational power and data processing. Direct Preference Optimization (DPO) emerges as a novel and more streamlined approach, offering an efficient alternative to these traditional methods. By simplifying the optimization process, DPO not only reduces the computational burden but also enhances the model’s ability to adapt quickly to human preferences
In this guide we’ll dive deep into DPO, exploring its foundations, implementation, and practical applications.
The Need for Preference Alignment
To understand DPO, it’s crucial to understand why aligning LLMs with human preferences is so important. Despite their impressive capabilities, LLMs trained on vast datasets can sometimes produce outputs that are inconsistent, biased, or misaligned with human values. This misalignment can manifest in various ways:
- Generating unsafe or harmful content
- Providing inaccurate or misleading information
- Exhibiting biases present in the training data
To address these issues, researchers have developed techniques to fine-tune LLMs using human feedback. The most prominent of these approaches has been RLHF.
Understanding RLHF: The Precursor to DPO
Reinforcement Learning from Human Feedback (RLHF) has been the go-to method for aligning LLMs with human preferences. Let’s break down the RLHF process to understand its complexities:
a) Supervised Fine-Tuning (SFT): The process begins by fine-tuning a pre-trained LLM on a dataset of high-quality responses. This step helps the model generate more relevant and coherent outputs for the target task.
b) Reward Modeling: A separate reward model is trained to predict human preferences. This involves:
- Generating response pairs for given prompts
- Having humans rate which response they prefer
- Training a model to predict these preferences
c) Reinforcement Learning: The fine-tuned LLM is then further optimized using reinforcement learning. The reward model provides feedback, guiding the LLM to generate responses that align with human preferences.
Here’s a simplified Python pseudocode to illustrate the RLHF process:
While effective, RLHF has several drawbacks:
- It requires training and maintaining multiple models (SFT, reward model, and RL-optimized model)
- The RL process can be unstable and sensitive to hyperparameters
- It’s computationally expensive, requiring many forward and backward passes through the models
These limitations have motivated the search for simpler, more efficient alternatives, leading to the development of DPO.
Direct Preference Optimization: Core Concepts

Direct Preference Optimization https://arxiv.org/abs/2305.18290
This image contrasts two distinct approaches to aligning LLM outputs with human preferences: Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO). RLHF relies on a reward model to guide the language model’s policy through iterative feedback loops, while DPO directly optimizes model outputs to match human-preferred responses using preference data. This comparison highlights the strengths and potential applications of each method, providing insights into how future LLMs might be trained to better align with human expectations.
Key ideas behind DPO:
a) Implicit Reward Modeling: DPO eliminates the need for a separate reward model by treating the language model itself as an implicit reward function.
b) Policy-Based Formulation: Instead of optimizing a reward function, DPO directly optimizes the policy (language model) to maximize the probability of preferred responses.
c) Closed-Form Solution: DPO leverages a mathematical insight that allows for a closed-form solution to the optimal policy, avoiding the need for iterative RL updates.
Implementing DPO: A Practical Code Walkthrough
The below image showcases a code snippet implementing the DPO loss function using PyTorch. This function plays a crucial role in refining how language models prioritize outputs based on human preferences. Here’s a breakdown of the key components:
- Function Signature: The
dpo_lossfunction takes in several parameters including policy log probabilities (pi_logps), reference model log probabilities (ref_logps), and indices representing preferred and dispreferred completions (yw_idxs,yl_idxs). Additionally, abetaparameter controls the strength of the KL penalty. - Log Probability Extraction: The code extracts the log probabilities for preferred and dispreferred completions from both the policy and reference models.
- Log Ratio Calculation: The difference between log probabilities for preferred and dispreferred completions is computed for both the policy and reference models. This ratio is critical in determining the direction and magnitude of optimization.
- Loss and Reward Calculation: The loss is calculated using the
logsigmoidfunction, while rewards are determined by scaling the difference between policy and reference log probabilities bybeta.

DPO loss function using PyTorch
Let’s dive into the mathematics behind DPO to understand how it achieves these goals.
The Mathematics of DPO
DPO is a clever reformulation of the preference learning problem. Here’s a step-by-step breakdown:
a) Starting Point: KL-Constrained Reward Maximization
The original RLHF objective can be expressed as:
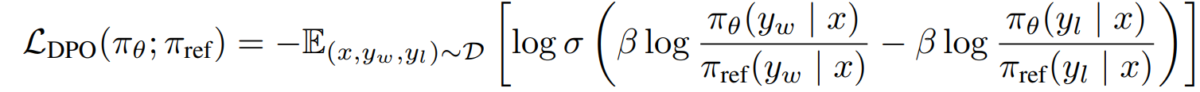
- πθ is the policy (language model) we’re optimizing
- r(x,y) is the reward function
- πref is a reference policy (usually the initial SFT model)
- β controls the strength of the KL divergence constraint
b) Optimal Policy Form: It can be shown that the optimal policy for this objective takes the form:
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))Where Z(x) is a normalization constant.
c) Reward-Policy Duality: DPO’s key insight is to express the reward function in terms of the optimal policy:
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))d) Preference Model Assuming preferences follow the Bradley-Terry model, we can express the probability of preferring y1 over y2 as:
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))Where σ is the logistic function.
e) DPO Objective Substituting our reward-policy duality into the preference model, we arrive at the DPO objective:
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]This objective can be optimized using standard gradient descent techniques, without the need for RL algorithms.
Implementing DPO
Now that we understand the theory behind DPO, let’s look at how to implement it in practice. We’ll use Python and PyTorch for this example:
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair.
"""
# Extract log probabilities for the preferred and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log probabilities for the model and the reference model
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
Challenges and Future Directions
While DPO offers significant advantages over traditional RLHF approaches, there are still challenges and areas for further research:
a) Scalability to Larger Models:
As language models continue to grow in size, efficiently applying DPO to models with hundreds of billions of parameters remains an open challenge. Researchers are exploring techniques like:
- Efficient fine-tuning methods (e.g., LoRA, prefix tuning)
- Distributed training optimizations
- Gradient checkpointing and mixed-precision training
Example of using LoRA with DPO:
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
b) Multi-Task and Few-Shot Adaptation:
Developing DPO techniques that can efficiently adapt to new tasks or domains with limited preference data is an active area of research. Approaches being explored include:
- Meta-learning frameworks for rapid adaptation
- Prompt-based fine-tuning for DPO
- Transfer learning from general preference models to specific domains
c) Handling Ambiguous or Conflicting Preferences:
Real-world preference data often contains ambiguities or conflicts. Improving DPO’s robustness to such data is crucial. Potential solutions include:
- Probabilistic preference modeling
- Active learning to resolve ambiguities
- Multi-agent preference aggregation
Example of probabilistic preference modeling:
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
d) Combining DPO with Other Alignment Techniques:
Integrating DPO with other alignment approaches could lead to more robust and capable systems:
- Constitutional AI principles for explicit constraint satisfaction
- Debate and recursive reward modeling for complex preference elicitation
- Inverse reinforcement learning for inferring underlying reward functions
Example of combining DPO with constitutional AI:
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):
super().__init__(model, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Usage
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement safety checking logic
unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5
constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Practical Considerations and Best Practices
When implementing DPO for real-world applications, consider the following tips:
a) Data Quality: The quality of your preference data is crucial. Ensure that your dataset:
- Covers a diverse range of inputs and desired behaviors
- Has consistent and reliable preference annotations
- Balances different types of preferences (e.g., factuality, safety, style)
b) Hyperparameter Tuning: While DPO has fewer hyperparameters than RLHF, tuning is still important:
- β (beta): Controls the trade-off between preference satisfaction and divergence from the reference model. Start with values around 0.1-0.5.
- Learning rate: Use a lower learning rate than standard fine-tuning, typically in the range of 1e-6 to 1e-5.
- Batch size: Larger batch sizes (32-128) often work well for preference learning.
c) Iterative Refinement: DPO can be applied iteratively:
- Train an initial model using DPO
- Generate new responses using the trained model
- Collect new preference data on these responses
- Retrain using the expanded dataset

Direct Preference Optimization Performance
This image shows the performance of LLMs like GPT-4 in comparison to human judgments across various training techniques, including Direct Preference Optimization (DPO), Supervised Fine-Tuning (SFT), and Proximal Policy Optimization (PPO). The table reveals that GPT-4’s outputs are increasingly aligned with human preferences, especially in summarization tasks. The level of agreement between GPT-4 and human reviewers demonstrates the model’s ability to generate content that resonates with human evaluators, almost as closely as human-generated content does.
Case Studies and Applications
To illustrate the effectiveness of DPO, let’s look at some real-world applications and some of its variants:
- Iterative DPO: Developed by Snorkel (2023), this variant combines rejection sampling with DPO, enabling a more refined selection process for training data. By iterating over multiple rounds of preference sampling, the model is better able to generalize and avoid overfitting to noisy or biased preferences.
- IPO (Iterative Preference Optimization): Introduced by Azar et al. (2023), IPO adds a regularization term to prevent overfitting, which is a common issue in preference-based optimization. This extension allows models to maintain a balance between adhering to preferences and preserving generalization capabilities.
- KTO (Knowledge Transfer Optimization): A more recent variant from Ethayarajh et al. (2023), KTO dispenses with binary preferences altogether. Instead, it focuses on transferring knowledge from a reference model to the policy model, optimizing for a smoother and more consistent alignment with human values.
- Multi-Modal DPO for Cross-Domain Learning by Xu et al. (2024): An approach where DPO is applied across different modalities—text, image, and audio—demonstrating its versatility in aligning models with human preferences across diverse data types. This research highlights the potential of DPO in creating more comprehensive AI systems capable of handling complex, multi-modal tasks.












