Artificial Intelligence
Towards Real-Time AI Humans With Neural Lumigraph Rendering

Despite the current wave of interest in Neural Radiance Fields (NeRF), a technology capable of creating AI-generated 3D environments and objects, this new approach to image synthesis technology still requires a great deal of training-time, and lacks an implementation that enables real-time, highly responsive interfaces.
However, a collaboration between some impressive names in industry and academia offers a new take on this challenge (generically known as Novel View Synthesis, or NVS).
The research paper, entitled Neural Lumigraph Rendering, claims an improvement on the state-of-the-art of about two orders of magnitude, representing several steps towards real-time CG rendering via machine learning pipelines.

Neural Lumigraph Rendering (right) offers better resolution of blending artifacts, and improved handling of occlusion over previous methods. Source.
Though credits for the paper only cite Stanford University and holographic display technology company Raxium (currently operating in stealth mode), the contributors include a principal machine learning architect at Google, a computer scientist at Adobe, and the CTO at StoryFile (which made headlines recently with an AI version of William Shatner).
In regard to the recent Shatner publicity blitz, StoryFile seems to be employing NLR in its new process for the creation of interactive, AI-generated entities based on the characteristics and narratives of individual people.
StoryFile envisages use of this technology in museum displays, online interactive narratives, holographic displays, augmented reality (AR), and heritage documentation – and also appears to be eyeing potential new applications of NLR in recruitment interviews and virtual dating applications:

Proposed uses from an online video by StoryFile. Source: https://www.youtube.com/watch?v=2K9J6q5DqRc
Volumetric Capture For Novel View Synthesis Interfaces And Video
The principle of volumetric capture, across the range of papers that are accumulating on the subject, is the idea of taking still images or videos of a subject, and using machine learning to ‘in-fill’ the viewpoints that were not covered by the original array of cameras.
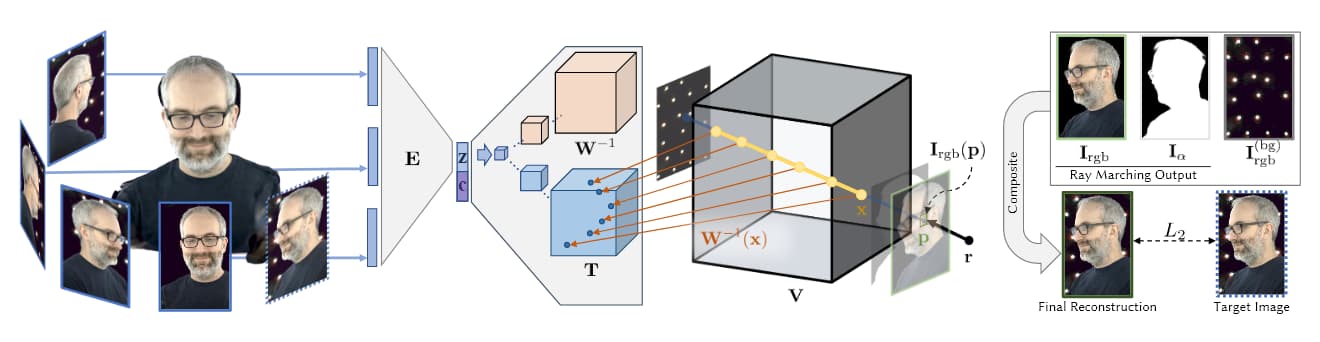
Source: https://research.fb.com/wp-content/uploads/2019/06/Neural-Volumes-Learning-Dynamic-Renderable-Volumes-from-Images.pdf
In the image above, taken from Facebook’s AI 2019 AI research (see below), we see the four stages of volumetric capture: multiple cameras obtain images/footage; encoder/decoder architecture (or other architectures) calculate and concatenate the relativity of views; ray-marching algorithms calculate the voxels (or other XYZ spatial geometric units) of each point in the volumetric space; and (in most recent papers) training occurs to synthesize a complete entity that can be manipulated in real-time.
It is this often extensive and data-heavy training phase that has, to date, kept novel view synthesis out of the realm of real-time or highly responsive capture.
The fact that Novel View Synthesis makes a complete 3D map of a volumetric space means that it is relatively trivial to stitch these points together into a traditional computer generated mesh, effectively capturing and articulating a CGI human (or any other relatively bounded object) on-the-fly.
Approaches that use NeRF rely on points clouds and depth maps to generate the interpolations between the sparse points-of-view of the capture devices:

NeRF can generate volumetric depth through calculation of depth maps, rather than generation of CG meshes. Source: https://www.youtube.com/watch?v=JuH79E8rdKc
Though NeRF is capable of calculating meshes, most implementations do not use this in order to generate volumetric scenes.
By contrast, the Implicit Differentiable Renderer (IDR) approach, published by the Weizmann Institute of Science in October 2020, hinges on exploiting 3D mesh information automatically generated from capture arrays:

Examples of IDR captures turned into interactive CGI meshes. Source: https://www.youtube.com/watch?v=C55y7RhJ1fE
While NeRF lacks IDR’s capability for shape estimation, IDR cannot match NeRF’s image quality, and both require extensive resources to train and collate (though recent innovations in NeRF are beginning to address this).

NLR’s Custom camera rig featuring 16 GoPro HERO7 and 6 central Back-Bone H7PRO cameras. For ‘real time’ rendering, these operate at a minimum of 60fps. Source: https://arxiv.org/pdf/2103.11571.pdf
Instead, Neural Lumigraph Rendering utilizes SIREN (Sinusoidal Representation Networks) to incorporate the strengths of each approach into its own framework, which is intended to generate output that’s directly usable in extant real-time graphics pipelines.
SIREN has been utilized for similar implementations over the past year, and now represents a popular API call for hobbyist Colabs in image synthesis communities; however, NLR’s innovation is to apply SIRENs to two-dimensional multi-view image supervision, which is problematic due to the extent to which SIREN produces over-fitted rather than generalized output.
After the CG mesh is extracted from the array images, the mesh is rasterized via OpenGL, and the vertex positions of the mesh mapped to the appropriate pixels, after which blending of the various contributing maps is calculated.
The resultant mesh is more generalized and representative than NeRF’s (see image below), requires less calculation, and does not apply excessive detail to areas (such as smooth facial skin) that cannot benefit from it:

Source: https://arxiv.org/pdf/2103.11571.pdf
On the negative side, NLR does not yet have any capacity for dynamic lighting or relighting, and output is restricted to shadow maps and other lighting considerations obtained at the time of capture. The researchers intend to address this in future work.
Additionally, the paper concedes that the shapes generated by NLR are not as accurate as some alternative approaches, such as Pixelwise View Selection for Unstructured Multi-View Stereo, or the Weizmann Institute research mentioned earlier.
The Rise Of Volumetric Image Synthesis
The idea of creating 3D entities from a limited series of photos with neural networks predates NeRF, with visionary papers going back to 2007 or earlier. In 2019 Facebook’s AI research department produced a seminal research paper, Neural Volumes: Learning Dynamic Renderable Volumes from Images, which first enabled responsive interfaces for synthetic humans generated by machine learning-based volumetric capture.

Facebook’s 2019 research enabled the creation of a responsive user interface for a volumetric person. Source: https://research.fb.com/publications/neural-volumes-learning-dynamic-renderable-volumes-from-images/












