Artificial Intelligence
The 75% Ceiling: Have AI Models Reached Peak Performance With Current Methods?

Anthropic and OpenAI unveiled frontier AI models two days apart, with both achieving virtually identical 74-75% accuracy on industry coding benchmarks, signaling a potential performance ceiling for current AI architectures while taking dramatically different approaches to distribution and implementation.
The near-simultaneous releases raise fundamental questions about whether AI development has reached a plateau with current training methods, even as the companies diverge sharply on how to deliver these capabilities to users and developers worldwide.
Benchmark Convergence Points to Technical Milestone
Claude Opus 4.1, released August 5th by Anthropic, scored 74.5% on SWE-bench Verified, the industry’s standard coding benchmark. OpenAI’s GPT-5, announced August 7th, achieved 74.9% on the same test—a statistical tie that suggests both companies have pushed current architectures to similar limits despite working independently.
The 0.4% difference between models falls within the margin of statistical noise for such benchmarks.
The architectural approaches, however, diverge significantly. OpenAI built GPT-5 as a multi-model system with intelligent routing—queries get directed to fast responders for simple tasks, reasoning models for complex problems, or mini versions when compute limits are reached. Anthropic maintained a single-model approach with Opus 4.1, prioritizing consistency over specialized optimization.
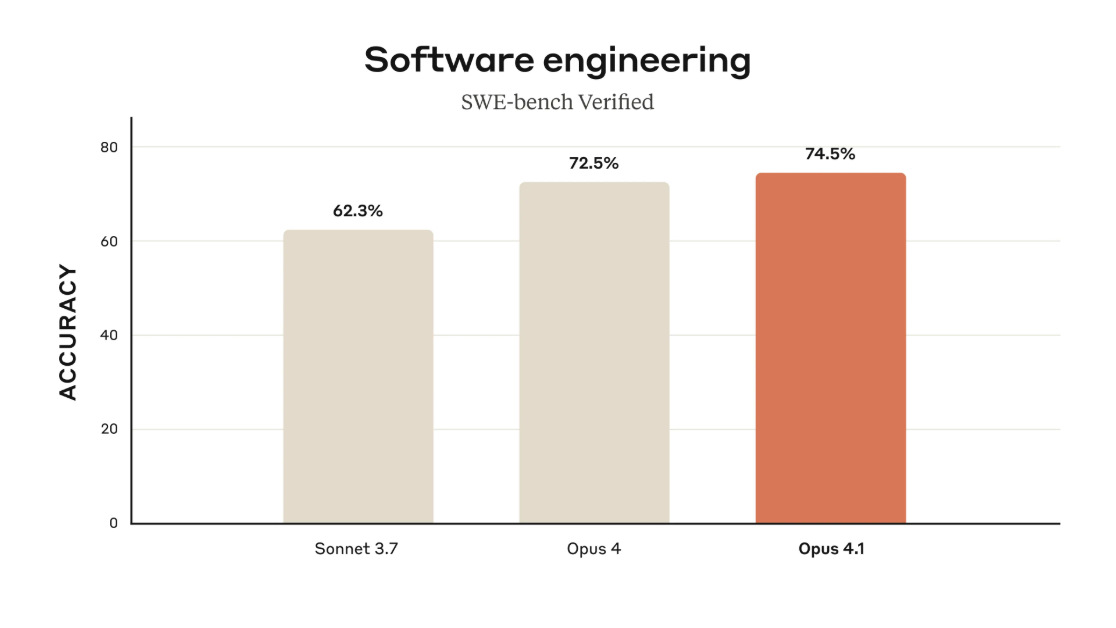
Source: Anthropic
Distribution Strategies Reveal Competing Philosophies
OpenAI made GPT-5 immediately available to all ChatGPT users, including those on the free tier—reaching approximately 700 million weekly active users at no cost. Microsoft simultaneously integrated the model across GitHub Copilot, Visual Studio Code, M365 Copilot, and Azure platforms.
Anthropic maintains more traditional access restrictions, offering Opus 4.1 to paid Claude users, through Claude Code for developers, and via API access. The company appears focused on serving developers and enterprises requiring reliable, consistent performance rather than maximizing distribution reach.
GPT-5’s pricing is aggressive, with developers noting favorable cost-to-capability ratios that could pressure competitors to adjust their pricing strategies.
Infrastructure Demands Reshape Industry Economics
The computational requirements reveal the massive scale of frontier AI development. OpenAI reportedly maintains a $30 billion annual contract with Oracle for capacity, having trained GPT-5 on Microsoft Azure using NVIDIA H200 GPUs. Meta announced plans to spend $72 billion on AI infrastructure in 2025 alone.
Both companies report significant improvements in practical applications beyond raw benchmarks. OpenAI states GPT-5 demonstrates “approximately 45% fewer errors than GPT-4o” when web search is enabled, with thinking mode achieving similar results to their o3 model while using 50-80% fewer tokens—a substantial efficiency gain.
GitHub reports Opus 4.1 shows “notable performance gains in multi-file code refactoring,” while Cursor, a popular AI coding assistant, describes GPT-5 as “remarkably intelligent, easy to steer,” according to OpenAI’s developer documentation.
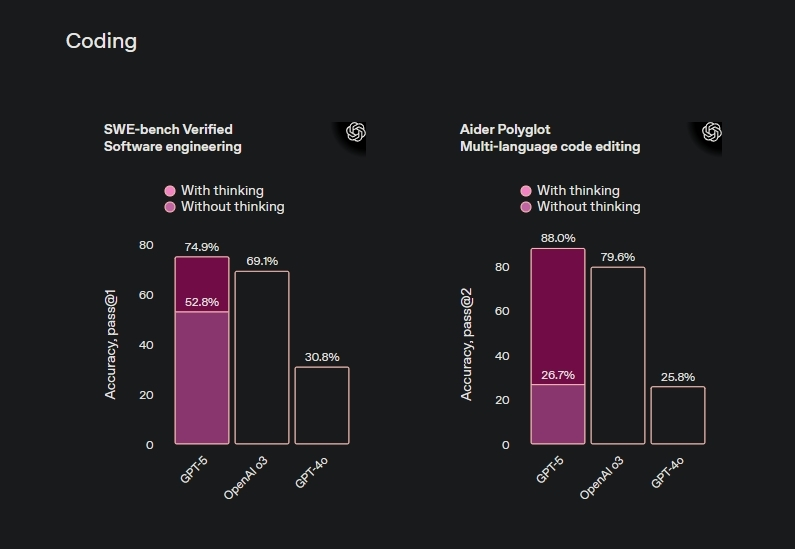
Source: OpenAI
Technical Ceiling Suggests Paradigm Shift Ahead
The convergence on similar performance metrics across companies suggests current training paradigms may be approaching their limits. Multiple models clustering around 74-75% accuracy on coding benchmarks indicates the next major improvements might require fundamental innovations rather than incremental scaling.
The architectural trade-offs between OpenAI’s complex routing system and Anthropic’s unified approach reflect different philosophies without a clear winner. GPT-5’s multi-model system offers flexibility but introduces potential failure points, while Claude’s consistency might sacrifice specialized performance for reliability.
The democratization of frontier AI capabilities—with features that cost thousands annually two years ago now available free—accelerates adoption across industries. This transition from AI as premium service to utility infrastructure could enable entirely new categories of applications.
Market Implications and Next Steps
Industry observers expect Anthropic to respond to OpenAI’s pricing strategy, though likely not through direct price matching. Google’s DeepMind and Meta, relatively quiet during these announcements, are anticipated to make moves in coming months.
The 48-hour window between releases revealed AI’s transition from experimental technology to reliable infrastructure. When multiple companies achieve near-identical benchmark scores with fractional percentage differences, competition shifts toward deployment efficiency, integration quality, and service reliability.
The practical improvements matter more than benchmark supremacy. SWE-bench Verified measures an AI’s ability to identify and fix real bugs in open-source software, and both models’ scores represent significant advances in autonomous coding capabilities.
As AI models become increasingly sophisticated in their reasoning and coding abilities, the competition is shifting from raw performance metrics to practical implementation and reliability in production environments. The surprising truth? This stability might enable more transformative change than another breakthrough would.












