Healthcare
Revolutionizing Healthcare: Exploring the Impact and Future of Large Language Models in Medicine

The integration and application of large language models (LLMs) in medicine and healthcare has been a topic of significant interest and development.
As noted in the Healthcare Information Management and Systems Society global conference and other notable events, companies like Google are leading the charge in exploring the potential of generative AI within healthcare. Their initiatives, such as Med-PaLM 2, highlight the evolving landscape of AI-driven healthcare solutions, particularly in areas like diagnostics, patient care, and administrative efficiency.
Google’s Med-PaLM 2, a pioneering LLM in the healthcare domain, has demonstrated impressive capabilities, notably achieving an “expert” level in U.S. Medical Licensing Examination-style questions. This model, and others like it, promise to revolutionize the way healthcare professionals access and utilize information, potentially enhancing diagnostic accuracy and patient care efficiency.
However, alongside these advancements, concerns about the practicality and safety of these technologies in clinical settings have been raised. For instance, the reliance on vast internet data sources for model training, while beneficial in some contexts, may not always be appropriate or reliable for medical purposes. As Nigam Shah, PhD, MBBS, Chief Data Scientist for Stanford Health Care, points out, the crucial questions to ask are about the performance of these models in real-world medical settings and their actual impact on patient care and healthcare efficiency.
Dr. Shah’s perspective underscores the need for a more tailored approach to utilizing LLMs in medicine. Instead of general-purpose models trained on broad internet data, he suggests a more focused strategy where models are trained on specific, relevant medical data. This approach resembles training a medical intern – providing them with specific tasks, supervising their performance, and gradually allowing for more autonomy as they demonstrate competence.
In line with this, the development of Meditron by EPFL researchers presents an interesting advancement in the field. Meditron, an open-source LLM specifically tailored for medical applications, represents a significant step forward. Trained on curated medical data from reputable sources like PubMed and clinical guidelines, Meditron offers a more focused and potentially more reliable tool for medical practitioners. Its open-source nature not only promotes transparency and collaboration but also allows for continuous improvement and stress testing by the wider research community.

MEDITRON-70B-achieves-an-accuracy-of-70.2-on-USMLE-style-questions-in-the-MedQA-4-options-dataset
The development of tools like Meditron, Med-PaLM 2, and others reflects a growing recognition of the unique requirements of the healthcare sector when it comes to AI applications. The emphasis on training these models on relevant, high-quality medical data, and ensuring their safety and reliability in clinical settings, is very crucial.
Moreover, the inclusion of diverse datasets, such as those from humanitarian contexts like the International Committee of the Red Cross, demonstrates a sensitivity to the varied needs and challenges in global healthcare. This approach aligns with the broader mission of many AI research centers, which aim to create AI tools that are not only technologically advanced but also socially responsible and beneficial.
The paper titled “Large language models encode clinical knowledge” recently published in Nature, explores how large language models (LLMs) can be effectively utilized in clinical settings. The research presents groundbreaking insights and methodologies, shedding light on the capabilities and limitations of LLMs in the medical domain.
The medical domain is characterized by its complexity, with a vast array of symptoms, diseases, and treatments that are constantly evolving. LLMs must not only understand this complexity but also keep up with the latest medical knowledge and guidelines.
The core of this research revolves around a newly curated benchmark called MultiMedQA. This benchmark amalgamates six existing medical question-answering datasets with a new dataset, HealthSearchQA, which comprises medical questions frequently searched online. This comprehensive approach aims to evaluate LLMs across various dimensions, including factuality, comprehension, reasoning, possible harm, and bias, thereby addressing the limitations of previous automated evaluations that relied on limited benchmarks.
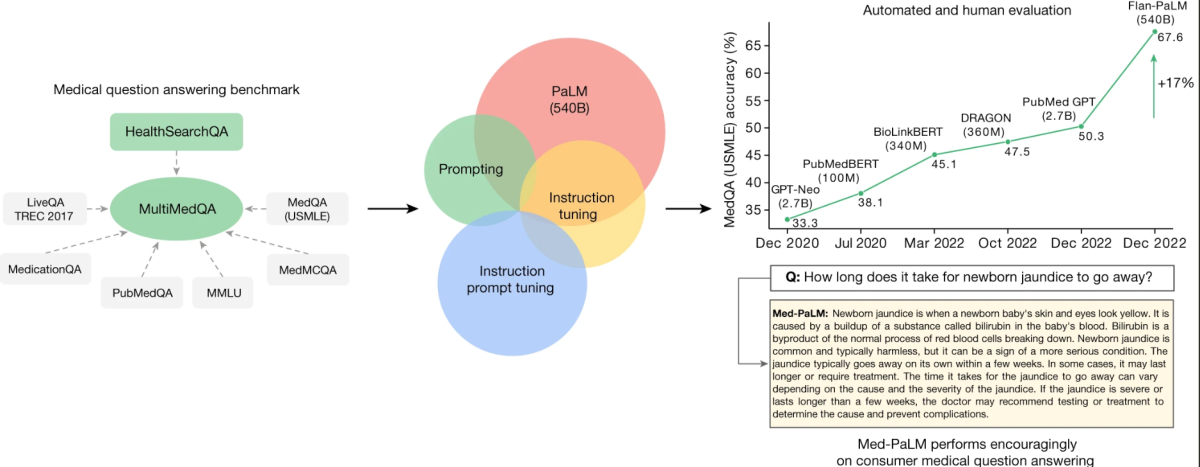
MultiMedQA, a benchmark for answering medical questions spanning medical exam
Key to the study is the evaluation of the Pathways Language Model (PaLM), a 540-billion parameter LLM, and its instruction-tuned variant, Flan-PaLM, on the MultiMedQA. Remarkably, Flan-PaLM achieves state-of-the-art accuracy on all the multiple-choice datasets within MultiMedQA, including a 67.6% accuracy on MedQA, which comprises US Medical Licensing Exam-style questions. This performance marks a significant improvement over previous models, surpassing the prior state of the art by more than 17%.
MedQA
Format: question and answer (Q + A), multiple choice, open domain.
Example question: A 65-year-old man with hypertension comes to the physician for a routine health maintenance examination. Current medications include atenolol, lisinopril, and atorvastatin. His pulse is 86 min−1, respirations are 18 min−1, and blood pressure is 145/95 mmHg. Cardiac examination reveals end diastolic murmur. Which of the following is the most likely cause of this physical examination?
Answers (correct answer in bold): (A) Decreased compliance of the left ventricle, (B) Myxomatous degeneration of the mitral valve (C) Inflammation of the pericardium (D) Dilation of the aortic root (E) Thickening of the mitral valve leaflets.
The study also identifies critical gaps in the model’s performance, especially in answering consumer medical questions. To address these issues, the researchers introduce a method known as instruction prompt tuning. This technique efficiently aligns LLMs to new domains using a few exemplars, resulting in the creation of Med-PaLM. The Med-PaLM model, though it performs encouragingly and shows improvement in comprehension, knowledge recall, and reasoning, still falls short compared to clinicians.
A notable aspect of this research is the detailed human evaluation framework. This framework assesses the models’ answers for agreement with scientific consensus and potential harmful outcomes. For instance, while only 61.9% of Flan-PaLM’s long-form answers aligned with scientific consensus, this figure rose to 92.6% for Med-PaLM, comparable to clinician-generated answers. Similarly, the potential for harmful outcomes was significantly reduced in Med-PaLM’s responses compared to Flan-PaLM.
The human evaluation of Med-PaLM’s responses highlighted its proficiency in several areas, aligning closely with clinician-generated answers. This underscores Med-PaLM’s potential as a supportive tool in clinical settings.
The research discussed above delves into the intricacies of enhancing Large Language Models (LLMs) for medical applications. The techniques and observations from this study can be generalized to improve LLM capabilities across various domains. Let’s explore these key aspects:
Instruction Tuning Improves Performance
- Generalized Application: Instruction tuning, which involves fine-tuning LLMs with specific instructions or guidelines, has shown to significantly improve performance across various domains. This technique could be applied to other fields such as legal, financial, or educational domains to enhance the accuracy and relevance of LLM outputs.
Scaling Model Size
- Broader Implications: The observation that scaling the model size improves performance is not limited to medical question answering. Larger models, with more parameters, have the capacity to process and generate more nuanced and complex responses. This scaling can be beneficial in domains like customer service, creative writing, and technical support, where nuanced understanding and response generation are crucial.
Chain of Thought (COT) Prompting
- Diverse Domains Utilization: The use of COT prompting, although not always improving performance in medical datasets, can be valuable in other domains where complex problem-solving is required. For instance, in technical troubleshooting or complex decision-making scenarios, COT prompting can guide LLMs to process information step-by-step, leading to more accurate and reasoned outputs.
Self-Consistency for Enhanced Accuracy
- Wider Applications: The technique of self-consistency, where multiple outputs are generated and the most consistent answer is selected, can significantly enhance performance in various fields. In domains like finance or legal where accuracy is paramount, this method can be used to cross-verify the generated outputs for higher reliability.
Uncertainty and Selective Prediction
- Cross-Domain Relevance: Communicating uncertainty estimates is crucial in fields where misinformation can have serious consequences, like healthcare and law. Using LLMs’ ability to express uncertainty and selectively defer predictions when confidence is low can be a crucial tool in these domains to prevent the dissemination of inaccurate information.
The real-world application of these models extends beyond answering questions. They can be used for patient education, assisting in diagnostic processes, and even in training medical students. However, their deployment must be carefully managed to avoid reliance on AI without proper human oversight.
As medical knowledge evolves, LLMs must also adapt and learn. This requires mechanisms for continuous learning and updating, ensuring that the models remain relevant and accurate over time.












