AI Models & Platforms
No, They Weren’t Throttling Claude – It Was Actually Worse

All right, let’s talk about what’s been happening with Claude, because if you’ve been using it over the past month, you probably noticed something was off.
For the past six weeks, Claude users have been losing their minds. Starting in early August, complaints started flooding Reddit, X, and developer forums. The issues were all over the place:
- Code that used to work perfectly was suddenly broken
- Claude would claim it made changes to files when it didn’t
- Random Thai or Chinese characters appearing in English responses
- Instructions being completely ignored
- The same prompt giving wildly different quality responses
- Claude Code users saying it felt “lobotomized” compared to before
The complaints got so bad that by late August, people were convinced Anthropic was secretly throttling Claude to save money. Conspiracy theories were everywhere – maybe they were reducing quality during peak hours, maybe they’d quietly swapped in a cheaper model, maybe this was intentional degradation to manage server costs.
Users were paying for Claude Pro and getting what felt like Claude Lite. Developers who’d built workflows around Claude were suddenly watching their productivity tank. With that said, some users weren’t experiencing any issues at all, which made everything more confusing.
Anthropic Finally Admits: Yeah, We Had Problems
After weeks of user complaints and growing frustration, Anthropic just dropped a massive technical post-mortem that basically says: “You were right. Claude was broken. Here’s what happened.”
And the answer is interesting.
Turns out it wasn’t one problem. It was three completely separate infrastructure bugs, all hitting at the same time, creating a perfect storm of AI degradation. They weren’t throttling. They weren’t cutting corners. They just had three different things break simultaneously in ways that took them six weeks to fully understand and fix.
Let me break down exactly what went wrong, because this is actually a helpful look at how these AI systems can fail in ways nobody anticipates.
The Triple-Bug Meltdown: A Timeline of Chaos
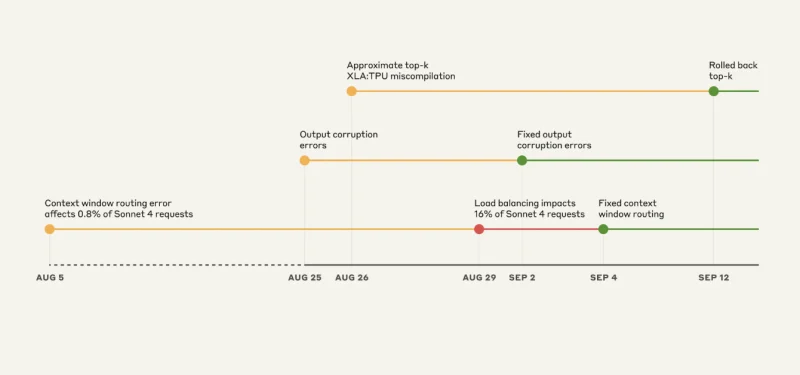
Source: Anthropic
Bug #1: The Wrong Server Problem
This is almost funny if you weren’t the one experiencing it. Claude Sonnet 4 was designed to handle 200,000 token contexts. But starting August 5th, some requests were getting routed to servers configured for 1 million token contexts.
Initially, only 0.8% of requests were affected. No big deal, right? Wrong.
On August 29th, a routine load balancer update turned this minor issue into a major problem. Suddenly, at peak, 16% of Sonnet 4 requests were going to the wrong servers. And the routing was “sticky.” Once you got misrouted, you kept getting misrouted.
The impact:
- About 30% of Claude Code users who were active during the window had at least one request misrouted
- Response times tanked for affected users
- The same user would experience the issue repeatedly while others had zero problems
Bug #2: The Random Character Generator
On August 25th, Anthropic deployed a misconfiguration to their TPU servers. The result was that Claude started randomly inserting Thai and Chinese characters into English responses.
Imagine asking Claude to debug your Python code and getting this:
def calculate_total(items):
total = 0
for item in items:
總計 += item.price # <- What?
return ผลรวม
This affected:
- Opus 4.1 and Opus 4: August 25-28
- Sonnet 4: August 25 – September 2nd
The technical cause was a token generation error that assigned high probability to characters that had no business being there. It literally broke the fundamental mechanism of how Claude selects the next word to say.
Bug #3: The Invisible Compiler Bug
This is the scary one from an engineering perspective. There was a latent bug in Google’s XLA compiler that had been sitting dormant. When Anthropic deployed code to improve token selection on August 25th, they accidentally triggered it.
What this bug did was genuinely bizarre – it would cause Claude to unintentionally exclude the most probable token when generating text. Claude knew the right answer but was physically prevented from saying it.
The really messed up part? They’d actually worked around this bug in December 2024 without realizing it. When they “fixed” what they thought was the root cause in August, they removed the workaround and unleashed the real problem.
Why It Took Six Weeks to Fix
You might be wondering: how does a company like Anthropic, with world-class engineers, take six weeks to figure this out?
The answer reveals just how complex these systems really are:
1. Privacy Controls Blocked Debugging
“Our internal privacy and security controls limit how and when engineers can access user interactions with Claude, in particular when those interactions are not reported to us as feedback.”
They literally couldn’t see what was breaking unless users explicitly reported it with feedback. Good for privacy, terrible for debugging.
2. The Bugs Hid Themselves
Claude would often recover from individual mistakes, making the degradation look like normal variance rather than systematic failure. Their benchmarks and evaluations weren’t catching it because the model would self-correct just enough to pass tests.
3. Multi-Platform Chaos
Claude runs on AWS Trainium, NVIDIA GPUs, and Google TPUs – three completely different hardware platforms. Each bug manifested differently on each platform:
- AWS Bedrock: 0.18% of Sonnet 4 requests affected at peak
- Google Vertex AI: Below 0.0004% affected
- Direct API: Up to 16% affected
This made it look like multiple unrelated issues rather than three specific bugs.
4. Overlapping Symptoms
With three bugs active simultaneously, symptoms were all over the map. One user might get Thai characters, another might get degraded responses, a third might see perfect performance. There was no clear pattern to follow.
What This Actually Means for AI Reliability
This whole saga reveals something crucial about the current state of AI systems: they’re way more fragile than they appear.
We’re not just talking about the AI model itself. We’re talking about:
- Routing infrastructure that can send requests to the wrong place
- Hardware-specific implementations that behave differently
- Compiler bugs that can lie dormant for months
- Load balancers that can amplify minor issues into major outages
One misconfiguration, one compiler bug, one routing error – and suddenly your AI assistant forgets how to code or starts speaking languages it shouldn’t.
Is It Actually Fixed?
Anthropic says they’ve resolved all three issues as of September 16th. They’ve:
- Fixed the routing logic
- Rolled back the problematic configurations
- Switched from approximate to exact top-k operations (taking a performance hit for accuracy)
- Added continuous production monitoring
But users are still reporting issues. Some developers claim Claude Code still feels degraded compared to its earlier performance. Whether that’s:
- Lingering effects from the bugs
- New issues that haven’t been identified
- Psychological bias after weeks of problems
- Or actual continued degradation
…we don’t know yet.
The Bottom Line
This situation is a perfect case study in how complex AI systems can fail in completely unexpected ways. Three separate bugs, all triggering within weeks of each other, created a perception of massive quality degradation that took six weeks to diagnose and fix.
We can give some credit to Anthropic for the transparency. Publishing a detailed technical post-mortem is more than most companies would do. But it also shows just how much can go wrong under the hood of these systems we’re increasingly relying on.
For anyone building on top of Claude or any LLM: you need redundancy, validation, and backup plans. Because as we’ve just seen, even the best AI systems can have three different problems simultaneously, and it might take weeks before anyone figures out what’s actually happening.
The infrastructure supporting these AI models is just as important as the models themselves. And right now, that infrastructure is showing some serious growing pains.












