KI 101
Was ist Backpropagation?
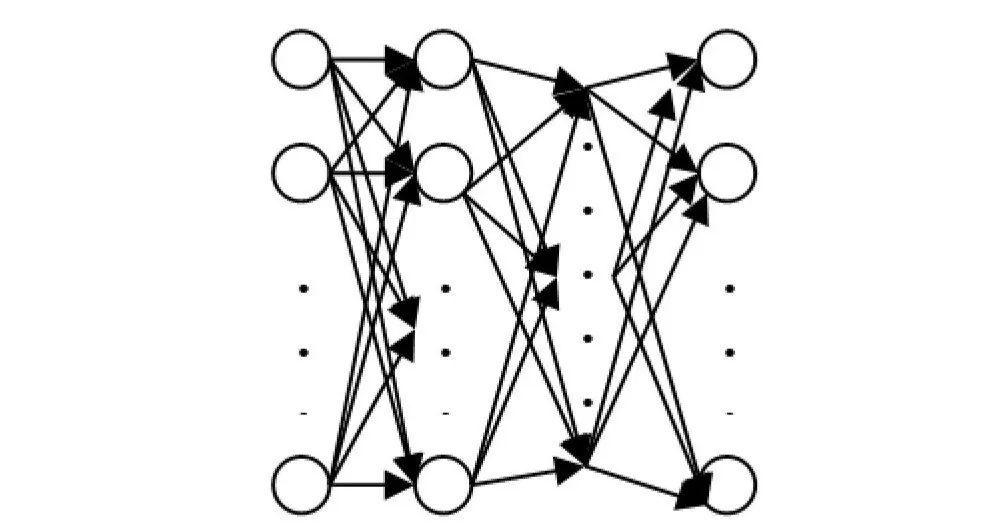
Was ist Backpropagation?
Tiefes Lernen-Systeme können extrem komplexe Muster lernen und erreichen dies, indem sie ihre Gewichte anpassen. Wie werden die Gewichte eines tiefen neuronalen Netzwerks genau angepasst? Sie werden durch einen Prozess namens Backpropagation angepasst. Ohne Backpropagation könnten tiefe neuronale Netzwerke keine Aufgaben wie Bilderkennung und Sprachinterpretation ausführen. Das Verständnis von Backpropagation ist entscheidend, um tiefe neuronale Netzwerke im Allgemeinen zu verstehen, also lassen Sie uns Backpropagation besprechen und sehen, wie der Prozess verwendet wird, um die Gewichte eines Netzwerks anzupassen.
Backpropagation kann schwierig zu verstehen sein, und die Berechnungen, die zur Durchführung von Backpropagation verwendet werden, können sehr komplex sein. Dieser Artikel wird versuchen, Ihnen ein intuitives Verständnis von Backpropagation zu vermitteln, ohne komplexe Mathematik zu verwenden. Allerdings ist eine gewisse Diskussion der Mathematik hinter Backpropagation notwendig.
Das Ziel von Backpropagation
Lassen Sie uns beginnen, indem wir das Ziel von Backpropagation definieren. Die Gewichte eines tiefen neuronalen Netzwerks sind die Stärke der Verbindungen zwischen den Einheiten eines neuronalen Netzwerks. Wenn das neuronale Netzwerk eingerichtet wird, werden Annahmen über die Verbindungen zwischen den Einheiten in einer Schicht und den Schichten, die mit ihr verbunden sind, getroffen. Wenn die Daten durch das neuronale Netzwerk fließen, werden die Gewichte berechnet und Annahmen getroffen. Wenn die Daten die letzte Schicht des Netzwerks erreichen, wird eine Vorhersage über die Beziehungen zwischen den Merkmalen und den Klassen im Datensatz getroffen. Die Differenz zwischen den vorhergesagten Werten und den tatsächlichen Werten ist der Verlust/Fehler, und das Ziel von Backpropagation ist es, den Verlust zu reduzieren. Dies wird erreicht, indem die Gewichte des Netzwerks angepasst werden, um die Annahmen den tatsächlichen Beziehungen zwischen den Eingabemerkmalen näher zu bringen.
Training eines tiefen neuronalen Netzwerks
Bevor Backpropagation auf einem neuronalen Netzwerk durchgeführt werden kann, muss der reguläre/vorwärtsgerichtete Trainingsdurchlauf eines neuronalen Netzwerks durchgeführt werden. Wenn ein neuronales Netzwerk erstellt wird, wird ein Satz von Gewichten initialisiert. Der Wert der Gewichte wird geändert, während das Netzwerk trainiert wird. Der vorwärtsgerichtete Trainingsdurchlauf eines neuronalen Netzwerks kann als drei separate Schritte aufgefasst werden: Neuronenaktivierung, Neuronenübertragung und Vorwärtspropagation.
Wenn wir ein tiefes neuronales Netzwerk trainieren, müssen wir mehrere mathematische Funktionen verwenden. Neuronen in einem tiefen neuronalen Netzwerk bestehen aus den eingehenden Daten und einer Aktivierungsfunktion, die den Wert bestimmt, der notwendig ist, um den Knoten zu aktivieren. Der Aktivierungswert eines Neurons wird mit mehreren Komponenten berechnet, nämlich einer gewichteten Summe der Eingaben. Die Gewichte und Eingabewerte hängen vom Index der Knoten ab, die zur Berechnung des Aktivierungswerts verwendet werden. Ein weiterer Wert muss berücksichtigt werden, wenn der Aktivierungswert berechnet wird, nämlich ein Bias-Wert. Bias-Werte ändern sich nicht, daher werden sie nicht mit dem Gewicht und den Eingaben multipliziert, sondern einfach addiert. All dies bedeutet, dass die folgende Gleichung verwendet werden kann, um den Aktivierungswert zu berechnen:
Aktivierung = Summe(Gewicht * Eingabe) + Bias
Nachdem das Neuron aktiviert wurde, wird eine Aktivierungsfunktion verwendet, um den Ausgang des tatsächlichen Ausgangs des Neurons zu bestimmen. Verschiedene Aktivierungsfunktionen sind für verschiedene Lernaufgaben optimal, aber häufig verwendete Aktivierungsfunktionen sind die Sigmoid-Funktion, die Tanh-Funktion und die ReLU-Funktion.
Sobald die Ausgänge des Neurons durch die gewünschte Aktivierungsfunktion berechnet wurden, ist die Vorwärtspropagation abgeschlossen. Die Vorwärtspropagation ist einfach die Übernahme der Ausgänge einer Schicht und deren Verwendung als Eingaben für die nächste Schicht. Die neuen Eingaben werden dann verwendet, um die neuen Aktivierungsfunktionen zu berechnen, und der Ausgang dieses Vorgangs wird an die nächste Schicht weitergegeben. Dieser Prozess wird bis zum Ende des neuronalen Netzwerks fortgesetzt.
Backpropagation im Netzwerk
Der Prozess der Backpropagation nimmt die endgültigen Entscheidungen eines Modells während des Trainingsdurchlaufs und bestimmt dann die Fehler in diesen Entscheidungen. Die Fehler werden berechnet, indem die Ausgänge/Entscheidungen des Netzwerks und die erwarteten/erwünschten Ausgänge des Netzwerks verglichen werden.
Sobald die Fehler in den Entscheidungen des Netzwerks berechnet wurden, werden diese Informationen rückwärts durch das Netzwerk propagiert und die Parameter des Netzwerks werden auf dem Weg geändert. Die Methode, die zur Anpassung der Gewichte des Netzwerks verwendet wird, basiert auf der Infinitesimalrechnung, insbesondere auf der Kettenregel. Allerdings ist ein Verständnis der Infinitesimalrechnung nicht notwendig, um das Konzept von Backpropagation zu verstehen. Es genügt zu wissen, dass, wenn ein Ausgangswert von einem Neuron bereitgestellt wird, die Steigung des Ausgangswerts mit einer Übertragungsfunktion berechnet wird, die einen abgeleiteten Ausgangswert erzeugt. Wenn Backpropagation durchgeführt wird, wird der Fehler für ein bestimmtes Neuron gemäß der folgenden Formel berechnet:
Fehler = (erwarteter_Ausgang – tatsächlicher_Ausgang) * Steigung des Ausgangswerts des Neurons
Wenn auf den Neuronen in der Ausgabeschicht operiert wird, wird der Klassenwert als erwarteter Wert verwendet. Nachdem der Fehler berechnet wurde, wird der Fehler als Eingabe für die Neuronen in der versteckten Schicht verwendet, was bedeutet, dass der Fehler für diese versteckte Schicht der gewichtete Fehler der Neuronen in der Ausgabeschicht ist. Die Fehlerberechnungen reisen rückwärts durch das Netzwerk entlang der Gewichte des Netzwerks.
Nachdem die Fehler für das Netzwerk berechnet wurden, müssen die Gewichte im Netzwerk aktualisiert werden. Wie bereits erwähnt, beinhaltet die Fehlerberechnung die Bestimmung der Steigung des Ausgangswerts. Nachdem die Steigung berechnet wurde, kann ein Prozess namens Gradientenabstieg verwendet werden, um die Gewichte im Netzwerk anzupassen. Ein Gradient ist eine Steigung, deren Steilheit gemessen werden kann. Die Steilheit wird berechnet, indem “y” über “x” oder der “Anstieg” über den “Lauf” geplottet wird. Im Falle des neuronalen Netzwerks und der Fehlerrate ist “y” der berechnete Fehler, während “x” die Parameter des Netzwerks sind. Die Parameter des Netzwerks haben eine Beziehung zu den berechneten Fehlerraten, und wenn die Gewichte des Netzwerks angepasst werden, erhöht oder verringert sich der Fehler.
“Gradientenabstieg” ist der Prozess der Anpassung der Gewichte, um den Fehlerrate zu verringern. Backpropagation wird verwendet, um die Beziehung zwischen den Parametern des neuronalen Netzwerks und der Fehlerrate vorherzusagen, was das Netzwerk für den Gradientenabstieg vorbereitet. Das Training eines Netzwerks mit Gradientenabstieg beinhaltet die Berechnung der Gewichte durch Vorwärtspropagation, das Rückwärtspropagieren des Fehlers und dann die Aktualisierung der Gewichte des Netzwerks.








