AI 入门 101
什么是过拟合?
什么是过拟合?
当你训练一个神经网络时,你必须避免过拟合。 过拟合 是机器学习和统计学中一个问题,即模型学习训练数据集的模式太好,完美地解释了训练数据集,但无法将其预测能力推广到其他数据集。
换句话说,在过拟合模型的情况下,它通常在训练数据集上显示极高的准确率,但在未来收集和运行模型的数据上显示低准确率。这是对过拟合的快速定义,但让我们更详细地了解过拟合的概念。让我们看看过拟合是如何发生的以及如何避免它。
理解“拟合”和欠拟合
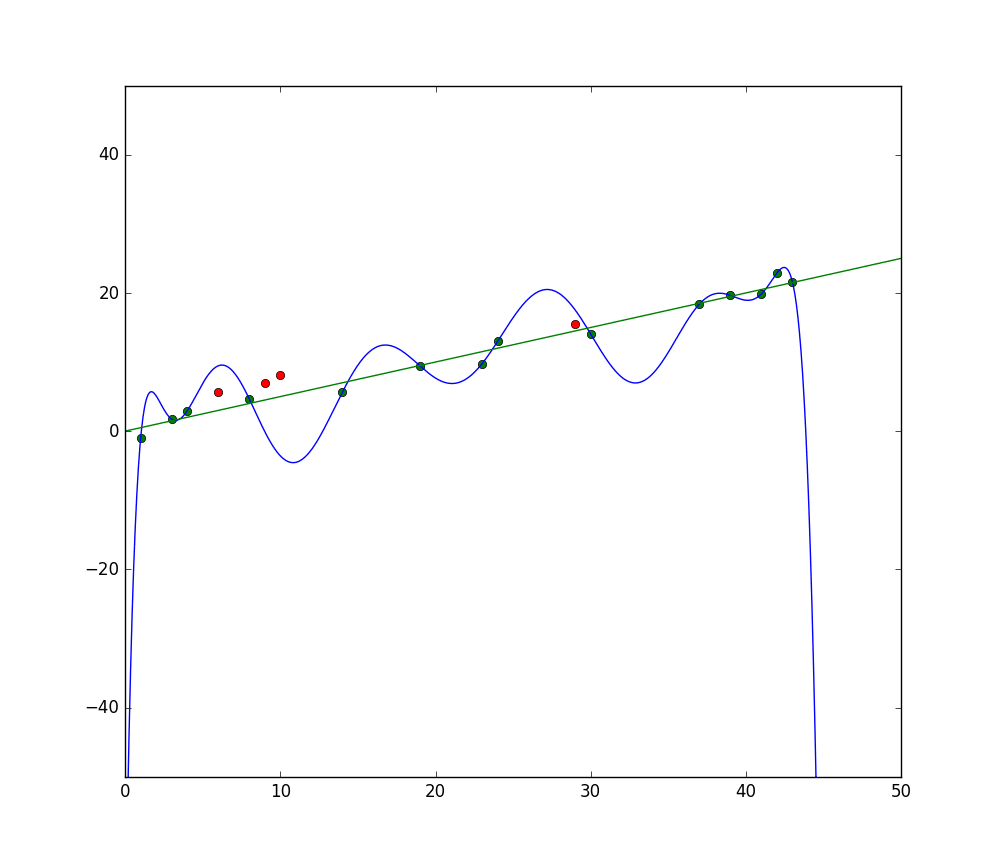
讨论过拟合时,了解欠拟合和“拟合”的概念是有帮助的。当我们训练一个模型时,我们试图开发一个能够根据描述这些项的特征预测数据集中项的性质或类别的框架。一个模型应该能够解释数据集中的模式并根据该模式预测未来数据点的类别。我们的模型越好地解释训练集特征之间的关系,我们的模型就越“拟合”。

蓝线代表了欠拟合模型的预测,而绿线代表了更好地拟合的模型。图片来源:Pep Roca via Wikimedia Commons,CC BY SA 3.0,(https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
一个模型如果不能很好地解释训练数据和标签之间的关系,并且因此无法准确地分类未来数据例,则该模型欠拟合训练数据。如果你将欠拟合模型的预测关系图与实际值图对比,预测将会明显偏离实际值。如果我们有一个图表显示训练集的实际值,一个严重欠拟合的模型将会明显地偏离大多数数据点。一个拟合更好的模型可能会穿过数据点的中心,个别数据点仅略微偏离预测值。
欠拟合通常发生在数据不足以创建一个准确的模型时,或者尝试使用线性模型来拟合非线性数据时。更多的训练数据或更多的特征通常可以帮助减少欠拟合。
那么,为什么我们不创建一个能够完美地解释训练数据集的每个点的模型呢?难道完美的准确率不是理想的吗?创建一个过于擅长学习训练数据模式的模型正是导致过拟合的原因。训练数据集和将来运行模型的其他数据集不会完全相同。它们可能在很多方面非常相似,但也会在某些关键方面有所不同。因此,设计一个能够完美地解释训练数据集的模型意味着你最终会得到一个关于特征之间关系的理论,这个理论不能很好地推广到其他数据集。
理解过拟合
过拟合发生在模型过于擅长学习训练数据集的细节时,导致模型在预测外部数据时表现不佳。这可能发生在模型不仅学习数据集的特征,还学习数据集中的随机波动或噪声时,并将这些随机/不重要的事件作为重要因素。
过拟合更容易发生在非线性模型中,因为它们在学习数据特征时更具灵活性。非参数机器学习算法通常具有各种参数和技术,可以应用于限制模型对数据的敏感性,从而减少过拟合。例如,决策树模型 对过拟合非常敏感,但可以使用一种称为剪枝的技术来随机删除模型学习的一些细节。
如果你将模型在X和Y轴上的预测图出来,你将会看到一条来回折线的预测线,这反映了模型过度拟合训练数据集的每个点。
控制过拟合
当我们训练一个模型时,我们理想地希望模型不犯任何错误。当模型的性能趋近于在训练数据集的所有数据点上做出正确的预测时,模型的拟合度变得更好。一个拟合良好的模型能够解释几乎所有训练数据集而不发生过拟合。
随着模型的训练,其性能会随着时间的推移而改善。模型的错误率会随着训练时间的推移而降低,但它只会降低到一定程度。模型在测试集上的性能开始再次提高的点通常是过拟合发生的点。为了获得模型的最佳拟合度,我们希望在训练集上的损失最低的点停止训练模型,在错误开始再次增加之前。最佳停止点可以通过绘制模型在训练时间上的性能图来确定,并在损失最低时停止训练。然而,使用此方法控制过拟合的一个风险是,根据测试性能指定训练的终点意味着测试数据在某种程度上被包含在训练过程中,并失去了其作为“未接触”数据的状态。
有几种方法可以减少过拟合。减少过拟合的一种方法是使用重采样策略,该策略通过估计模型的准确率来运行。你也可以使用 验证 数据集,除了测试集,并将训练准确率与验证集进行比较,而不是与测试数据集进行比较。这可以保持测试数据集的“未见”状态。一个流行的重采样方法是 K 折交叉验证。这种技术可以让你将数据分成子集,模型在这些子集上进行训练,然后分析模型在这些子集上的性能,以估计其在外部数据上的性能。
使用交叉验证是估计模型在未见数据上的准确率的最佳方法之一,并且当与验证数据集结合使用时,过拟合通常可以最小化。








