AI 入门 101
决策树是什么?
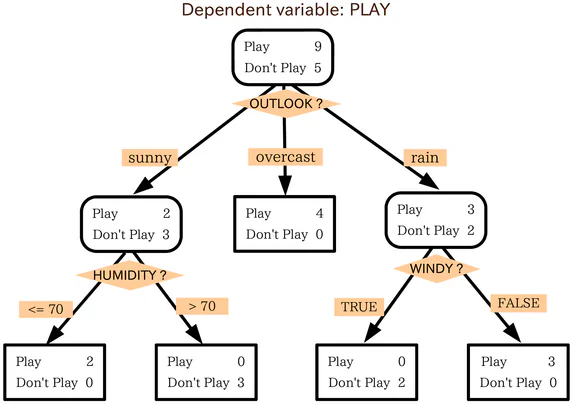
什么是决策树?
决策树是一种有用的机器学习算法,用于回归和分类任务。决策树的名称来自于算法不断将数据集划分为越来越小的部分,直到数据被划分为单个实例,然后进行分类。如果你想象算法的结果,类别的划分方式类似于一棵树和许多叶子。
这是决策树的一个快速定义,但让我们深入了解决策树的工作原理。更好地理解决策树的工作原理及其用例将帮助你在机器学习项目中知道何时使用它们。
决策树的格式
决策树与流程图类似。要使用流程图,你从图表的起始点或根开始,然后根据起始节点的过滤条件回答问题,你会移动到下一个可能的节点。这个过程会重复,直到达到结束。
决策树以类似的方式工作,每个内部节点都是某种测试或过滤条件。树外的节点,即树的终点,被称为“叶子”。从内部节点到下一个节点的分支是特征或特征的组合。用于分类数据点的规则是从根到叶子的路径。

决策树的算法
决策树基于一种算法方法,该方法根据不同的标准将数据集划分为单个数据点。这些划分是使用数据集的不同变量或特征进行的。例如,如果目标是确定输入特征是否描述了一只狗或一只猫,数据可能会根据诸如“爪子”和“吠叫”等变量进行划分。
那么,什么算法被用来实际划分数据为分支和叶子?有多种方法可以划分树,但最常见的划分方法可能是一种称为“递归二分划分”的技术”。当执行此方法时,过程从根开始,数据集中的特征数量代表可能的划分数量。使用一个函数来确定每个可能的划分的准确性损失,并使用最小化准确性损失的标准进行划分。这个过程是递归执行的,子组是使用相同的策略形成的。
为了确定划分的成本,使用了一个成本函数。回归任务和分类任务使用不同的成本函数。两个成本函数的目标都是确定哪些分支具有最相似的响应值,或最同质的分支。考虑到你想要测试数据属于某个类别,并且这条路径是有意义的。
在递归二分划分的回归成本函数中,用于计算成本的算法如下:
sum(y – prediction)^2
对于特定的一组数据点,预测是训练数据的响应值的平均值。所有数据点都通过成本函数来确定所有可能划分的成本,并选择具有最低成本的划分。
关于分类的成本函数,函数如下:
G = sum(pk * (1 – pk))
这是基尼系数,它是划分的有效性的衡量标准,基于划分后组中不同类别的实例数量。换句话说,它量化了划分后组的混合程度。最优的划分是划分后所有组只包含一个类别的输入。 如果创建了最优的划分,“pk”值将为0或1,G将为0。你可能可以猜出最坏的划分是二元分类中类别在划分中以50-50的比例表示的情况。在这种情况下,“pk”值将为0.5,G也将为0.5。
划分过程在所有数据点都被转换为叶子并被分类时终止。然而,你可能希望在树的生长早些时候停止它。大的复杂树容易过拟合,但可以使用几种不同的方法来解决这个问题。减少过拟合的一种方法是指定创建叶子的最少数据点数量。控制树的最大深度是另一种控制过拟合的方法,它控制了从根到叶子的路径的长度。
决策树创建过程中涉及的另一个过程是修剪。修剪可以通过剥去具有较小预测能力/较小重要性的特征的分支来提高决策树的性能。这样,树的复杂性减少,过拟合的可能性降低,模型的预测能力增加。
当进行修剪时,过程可以从树的顶部或底部开始。然而,修剪的最简单方法是从叶子开始,尝试删除包含最常见类的节点。如果模型的准确性在这样做时不会恶化,则保留更改。还有其他用于执行修剪的技术,但上面描述的方法 – 减少错误修剪 – 可能是最常见的决策树修剪方法。
使用决策树的考虑因素
决策树通常在分类需要执行但计算时间是一个主要约束的情况下很有用。决策树可以清楚地显示所选数据集中哪些特征具有最大的预测能力。另外,与许多机器学习算法不同,数据的分类规则可能难以解释,决策树可以提供可解释的规则。决策树还可以使用分类和连续变量,这意味着与只能处理其中一种变量类型的算法相比,需要较少的预处理。
决策树在用于确定连续属性的值时通常不能很好地执行。决策树的另一个限制是,当进行分类时,如果训练示例很少但类别很多,决策树往往不准确。








