ШІ 101
Що таке Переобучення?
Що таке Переобучення?
Коли ви тренуєте нейронну мережу, вам потрібно уникати переобучення. Переобучення – це проблема у машинному навчанні та статистиці, коли модель вчиться шаблонам навчального набору даних занадто добре, ідеально пояснюючи навчальний набір даних, але не може узагальнити свою передбачувальну силу до інших наборів даних.
Інакше кажучи, у випадку з моделлю переобучення вона часто показує надзвичайно високу точність на навчальному наборі даних, але низьку точність на даних, зібраних і пройдених через модель у майбутньому. Це коротке визначення переобучення, але давайте розглянемо концепцію переобучення детальніше. Давайте розглянемо, як відбувається переобучення і як його можна уникнути.
Розуміння “Фіту” і недообучення
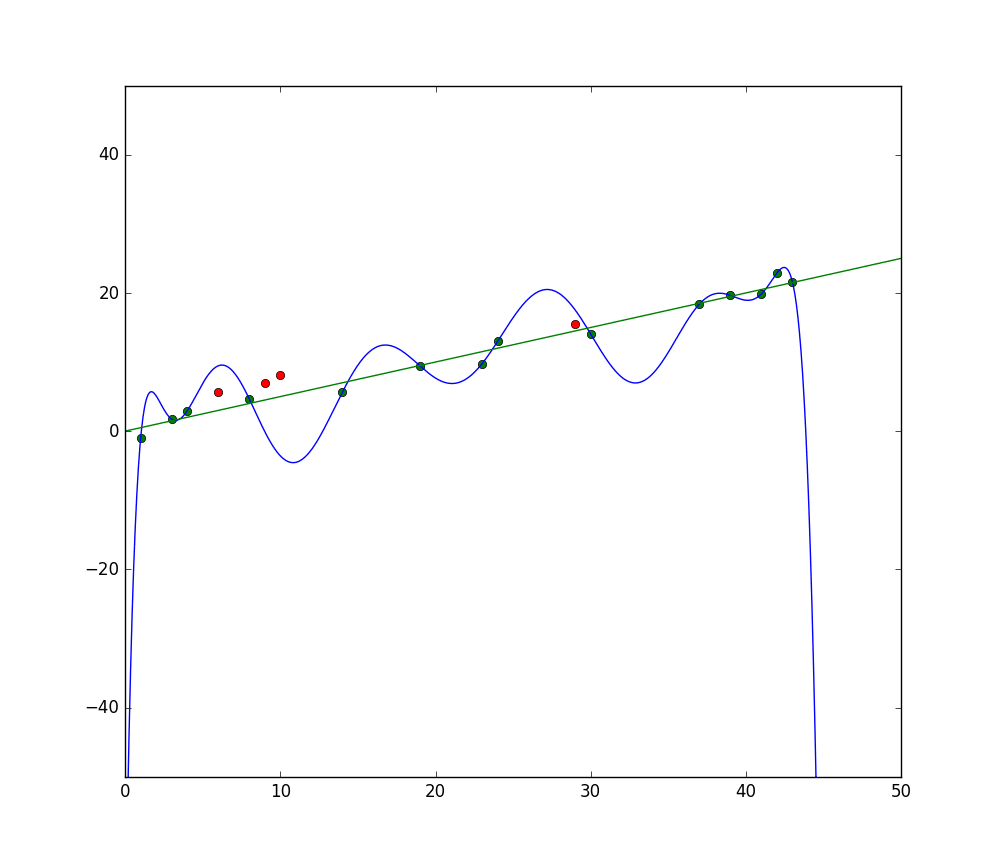
Корисно розглянути концепцію недообучення і “фіту” загалом при обговоренні переобучення. Коли ми тренуємо модель, ми намагаємося розробити框, яка能够 передбачити природу або клас предметів у наборі даних на основі ознак, які описують ці предмети. Модель повинна能够 пояснити шаблон у наборі даних і передбачити класи майбутніх даних на основі цього шаблону. Чим краще модель пояснює відносини між ознаками навчального набору, тим “краще” наш модель.

Синя лінія представляє передбачення моделі, яка недообучена, тоді як зелена лінія представляє модель з кращим фітом. Фото: Pep Roca via Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Модель, яка погано пояснює відносини між ознаками навчального набору даних і тому не може точно класифікувати майбутні дані, недообучується навчальний набір даних. Якщо б ви графікували передбачувану відносини моделі недообучення проти фактичних значень навчального набору, передбачення були б далеко від мети. Якщо б у нас був граф з фактичними значеннями навчального набору, модель з поганим фітом сильно промахалася б щодо більшості даних. Модель з кращим фітом могла б пройти через центр даних, з окремими даними, які були б лише трохи відрізними від передбачуваних значень.
Недообучення часто відбувається, коли даних недостатньо для створення точної моделі, або коли намагаються розробити лінійну модель з нелінійними даними. Більше даних або більше ознак часто допомагають зменшити недообучення.
Чому б нам не створити модель, яка пояснює кожну точку навчального набору даних ідеально? Чому б нам не хотіти ідеальної точності? Створення моделі, яка вчиться шаблонам навчального набору даних занадто добре, призводить до переобучення. Навчальний набір даних і майбутні набори даних, які ви проходите через модель, не будуть точно однаковими. Вони, ймовірно, будуть дуже схожими у багатьох аспектах, але вони також будуть відрізнятися у ключових аспектах. Тому розробка моделі, яка пояснює навчальний набір даних ідеально, означає, що ви отримуєте теорію про відносини між ознаками, яка не узагальнюється добре до інших наборів даних.
Розуміння Переобучення
Переобучення відбувається, коли модель вчиться деталям у навчальному наборі даних занадто добре, що призводить до того, що модель страждає, коли робляться передбачення на зовнішніх даних. Це може відбуватися, коли модель не тільки вчиться ознакам набору даних, але також вчиться випадковим коливанням або шумом у наборі даних, надавши їм значення цих випадкових/незначимих подій.
Переобучення більш ймовірно відбувається, коли використовуються нелінійні моделі, оскільки вони більш гнучкі при навчанні ознак даних. Непараметричні алгоритми машинного навчання часто мають різні параметри та техніки, які можна застосовувати для обмеження чутливості моделі до даних і тим самим зменшення переобучення. Наприклад, моделі рішень дуже чутливі до переобучення, але техніку підстрижки можна використовувати для випадкового видалення деяких деталей, які модель вивчила.
Якщо б ви графікували передбачення моделі на осі X і Y, у вас була б лінія передбачення, яка зигзагоподібно рухається туди й назад, що відображає той факт, що модель намагалася занадто добре пояснити всі точки у навчальному наборі даних.
Контроль Переобучення
Коли ми тренуємо модель, ми ідеально хочемо, щоб модель не робила жодних помилок. Коли продуктивність моделі збігається до правильних передбачень на всіх даних у навчальному наборі, фіт стає кращим. Модель з добрим фітом能够 пояснити майже весь навчальний набір даних без переобучення.
Під час тренування продуктивність моделі покращується з часом. Темп помилок моделі зменшується з часом тренування, але тільки до певної точки. Точка, в якій продуктивність моделі на тестовому наборі починає зростати знову, зазвичай є точкою, в якій відбувається переобучення. Щоб отримати найкращий фіт для моделі, ми хочемо зупинити тренування моделі в точці мінімальної втрати на навчальному наборі, до того, як помилка знову починає зростати. Оптимальна точка зупинки можна визначити, графікуючи продуктивність моделі протягом часу тренування і зупиняючи тренування, коли втрата мінімальна. Однак одним із ризиків цього методу контролю переобучення є те, що визначення кінцевої точки тренування на основі тестової продуктивності означає, що тестові дані стають частково включеними до процедури тренування і втрачають свій статус чисто “неторканих” даних.
Є кілька різних способів боротьби з переобученням. Одним із методів зменшення переобучення є використання тактики ресемплінгу, яка працює шляхом оцінки точності моделі. Ви також можете використовувати валідацийний набір даних разом з тестовим набором і графікувати точність тренування проти валідацийного набору замість тестового набору. Це зберігає ваш тестовий набір невидимим. Популярним методом ресемплінгу є крос-валідация з K-складами. Ця техніка дозволяє вам розділити дані на підмножини, на яких модель тренується, а потім аналізує продуктивність моделі на цих підмножинах, щоб оцінити, як модель буде працювати на зовнішніх даних.
Використання крос-валідації – один із найкращих способів оцінити точність моделі на невидимих даних, і коли його поєднують з валідацийним набором даних, переобучення можна часто giữвати на мінімумі.








