Штучний інтелект
Ендрю Нг критикує культуру надмірної адаптації в машинному навчанні
Ендрю Нг, один з найвпливовіших голосів у машинному навчанні за останні десять років, зараз висловлює занепокоєння щодо ступеня, в якому сектор надмірно акцентує інновації в архітектурі моделей над даними – і зокрема, щодо ступеня, в якому він дозволяє “надмірно адаптовані” результати зображувати як узагальнені рішення або досягнення.
Ці є широкі критики поточної культури машинного навчання, що походять від одного з його найвищих авторитетів, і мають наслідки для довіри в секторі, який охоплений страхами щодо третього колапсу бізнес-довіри в розвитку штучного інтелекту в просторі шістдесяти років.
Нг, професор Стенфордського університету, також є одним з засновників deeplearning.ai, і у березні опублікував послання на сайті організації, яке відфільтрувало його недавню промову до кількох основних рекомендацій:
По-перше, що дослідницька спільнота повинна停止 скаржитися на те, що очищення даних становить 80% викликів у машинному навчанні, і приступити до роботи з розробки надійних методологій і практик MLOps.
По-друге, що вона повинна відійти від “легких перемог”, які можна отримати шляхом надмірної адаптації даних до моделі машинного навчання, так що вона працює добре на цій моделі, але не узагальнюється або не дає широко застосовуваної моделі.
Прийняття виклику архітектури даних та кураторства
“Моя точка зору”, написав Нг, “полягає в тому, що якщо 80 відсотків нашої роботи – це підготовка даних, то забезпечення якості даних є важливою роботою команди машинного навчання.”
Він продовжив:
“Натомість ніж розраховувати на те, що інженери випадково знайдуть найкращий спосіб покращення набору даних, я сподіваюсь, що ми можемо розробити інструменти MLOps, які допоможуть зробити будівництво систем штучного інтелекту, включаючи будівництво високоякісних наборів даних, більш повторюваним і систематичним.
“MLOps – це новий напрямок, і різні люди визначають його по-різному. Але я думаю, що найважливішим організуючим принципом команд і інструментів MLOps повинен бути забезпечення постійного і високоякісного потоку даних на всіх етапах проекту. Це допоможе багатьом проектам проходити більш гладко.”
Під час промови на Zoom на живій сесії Q&A наприкінці квітня Нг звернувся до питання про застосування системи аналізу радіології:
“Виявляється, що коли ми збираємо дані зі Стенфордської лікарні, потім тренуємо і тестируємо дані з тієї ж лікарні, ми можемо публікувати статті, які показують, що алгоритми порівнянні з людськими радіологами у виявленні певних станів.
“…[Коли] ви берете ту саму модель, ту саму систему штучного інтелекту, до старої лікарні вниз по вулиці, з старою машиною, і технік використовує трохи інший протокол зображення, дані починають дрейфувати, що призводить до значного погіршення продуктивності системи штучного інтелекту. Натомість будь-який людський радіолог може пройти вниз по вулиці до старої лікарні і впоратися.”
Недооцінка не є рішенням
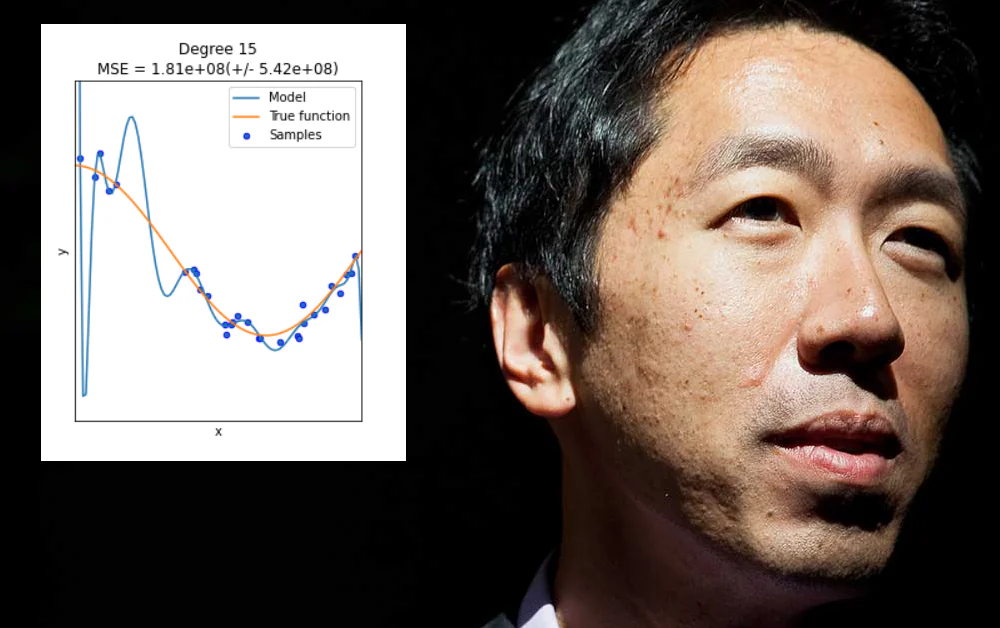
Надмірна адаптація відбувається, коли модель машинного навчання спеціально розробляється для задоволення ексцентричних особливостей певного набору даних (або того, як дані форматуються). Це може включати, наприклад, визначення ваг, які дадуть добрі результати з цього набору даних, але не “узагальнюватимуться” на інших даних.
У багатьох випадках такі параметри визначаються на “не-даних” аспектах навчального набору, таких як конкретна роздільна здатність зібраних даних, або інші особливості, які не гарантовано повторюватимуться в інших наступних наборах даних.
Хоча було б добре, надмірна адаптація не є проблемою, яку можна вирішити, розширюючи сферу або гнучкість архітектури даних або дизайну моделі, коли насправді потрібні широко застосовувані і високо значимі особливості, які працюватимуть добре в різних середовищах даних – більш складна задача.
Загалом, такий тип “недооцінки” призводить лише до тих проблем, які Нг недавно описав, коли модель машинного навчання не працює на невидимих даних. Відмінність у цьому випадку полягає в тому, що модель не працює не через те, що дані або форматування даних відрізняються від надмірно адаптованого оригінального навчального набору, а через те, що модель надто гнучка, а не надто крихка.
У кінці 2020 року стаття стаття Недооцінка представляє виклики для достовірності в сучасному машинному навчанні піддала інтенсивній критиці цю практику, і мала імена не менше сорока дослідників і вчених з машинного навчання з Google і MIT, серед інших інститутів.
Стаття критикує “шорткат-навчання” і спостерігає, як недооцінені моделі можуть відхилятися в дикі боки на основі випадкового стартового пункту, з якого починається навчання моделі. Автори спостерігають:
‘Ми бачимо, що недооцінка є універсальною в практичних трубопроводах машинного навчання через багато доменів. Дійсно, завдяки недооцінці, суттєво важливі аспекти рішень визначаються довільними виборами, такими як випадковий початок параметрів.’
Економічні наслідки зміни культури
Незважаючи на свою академічну кваліфікацію, Нг не є повітряним академіком, а має глибокий і високий промисловий досвід як співзасновник Google Brain і Coursera, колишній головний науковець з великих даних і штучного інтелекту в Baidu, і як засновник Landing AI, який адмініструє 175 мільйонів доларів США для нових стартапів у секторі.
Коли він говорить “Все штучного інтелекту, не тільки охорони здоров’я, має розрив між доведенням концепції і виробництвом”, це призначено як сигнал тривоги для сектору, чий поточний рівень гіпу і плямистої історії все більше характеризується як нестійка довгострокова бізнес-інвестиція, охоплена проблемами визначення і сфери дії.
Незважаючи на це, пропріетарні системи машинного навчання, які працюють добре в місці і не працюють в інших середовищах, представляють собою такий вид захоплення ринку, який міг би винагородити промислову інвестицію. Представлення “проблеми надмірної адаптації” в контексті професійної загрози пропонує нечесний спосіб монетизації корпоративної інвестиції в відкритий джерельний код дослідження, і виробляти (фактично) пропріетарні системи, де реплікація конкурентами є можливою, але проблематичною.
Чи це підхід буде працювати в довгостроковій перспективі, залежить від ступеня, в якому реальні прориви в машинному навчанні продовжують потребувати дедалі більших рівнів інвестицій, і чи не всі продуктивні ініціативи врешті-решт міграють до FAANG до певної міри через колосальні ресурси, необхідні для хостингу і операцій.












