ИИ 101
Что такое RNN и LSTM в глубоком обучении?
Многие из наиболее впечатляющих достижений в области обработки естественного языка и чат-ботов основаны на рекуррентных нейронных сетях (RNN) и сетях с долгой краткосрочной памятью (LSTM). RNN и LSTM – это специальные архитектуры нейронных сетей, которые могут обрабатывать последовательные данные, где хронологический порядок имеет значение. LSTM можно считать улучшенными версиями RNN, способными интерпретировать более длинные последовательности данных. Давайте рассмотрим, как RNN и LSTM структурированы и как они позволяют создавать сложные системы обработки естественного языка.
Что такое прямые нейронные сети?
Прежде чем мы поговорим о том, как работают LSTM и свёрточные нейронные сети (CNN), мы должны обсудить общий формат нейронной сети.
Нейронная сеть предназначена для анализа данных и学习 важных закономерностей, чтобы эти закономерности можно было применить к другим данным и классифицировать новые данные. Нейронные сети разделены на три секции: входной слой, скрытый слой (или несколько скрытых слоёв) и выходной слой.
Входной слой принимает данные в нейронную сеть, а скрытые слои учатся закономерностям в данных. Скрытые слои в наборе данных связаны с входным и выходным слоями через “веса” и “смещения”, которые являются просто предположениями о том, как данные связаны между собой. Эти веса корректируются во время обучения. Когда сеть обучается, предположения модели о обучающих данных (выходные значения) сравниваются с фактическими метками обучения. В процессе обучения сеть должна (надеюсь) стать более точной в предсказании отношений между данными, чтобы она могла точно классифицировать новые данные. Глубокие нейронные сети – это сети, которые имеют больше слоёв в середине/больше скрытых слоёв. Чем больше скрытых слоёв и нейронов/узлов в модели, тем лучше модель может распознавать закономерности в данных.
Обычные прямые нейронные сети, как те, которые я описал выше, часто называются “плотными нейронными сетями”. Эти плотные нейронные сети объединяются с различными архитектурами сетей, которые специализируются на интерпретации различных типов данных.
Что такое RNN (рекуррентные нейронные сети)?

Рекуррентные нейронные сети принимают общий принцип прямых нейронных сетей и позволяют им обрабатывать последовательные данные, давая модели внутреннюю память. “Рекуррентный” phần названия RNN происходит от того, что вход и выходы петлятся. Как только выход сети произведён, выход копируется и возвращается в сеть как вход. При принятии решения не только текущий вход и выход анализируются, но также предыдущий вход. Иными словами, если первоначальный вход для сети – X, а выход – H, то и H, и X1 (следующий вход в последовательности данных) подаются в сеть для следующего раунда обучения. Таким образом, контекст данных (предыдущие входы) сохраняется, когда сеть обучается.
Результатом этой архитектуры является то, что RNN способны обрабатывать последовательные данные. Однако RNN страдают от нескольких проблем. RNN страдают от проблемы исчезающего градиента и взрывающегося градиента.
Длина последовательностей, которые RNN может интерпретировать, довольно ограничена, особенно по сравнению с LSTM.
Что такое LSTM (сети с долгой краткосрочной памятью)?
Сети с долгой краткосрочной памятью можно считать расширением RNN, ещё раз применяя концепцию сохранения контекста входов. Однако LSTM были изменены несколькими важными способами, которые позволяют им интерпретировать прошлые данные более совершенными методами. Изменения, внесённые в LSTM, касаются проблемы исчезающего градиента и позволяют LSTM учитывать гораздо более длинные входные последовательности.

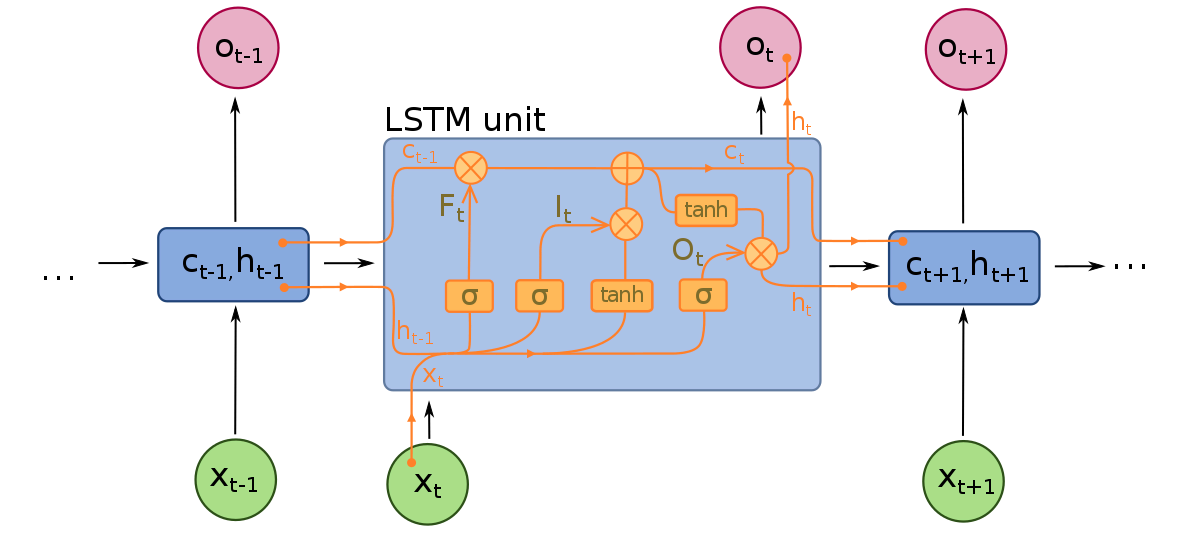
Модели LSTM состоят из трёх различных компонентов или “ворот”. Есть входная ворота, выходная ворота и забывающая ворота. Как и RNN, LSTM принимают во внимание входы из предыдущего временного шага при изменении памяти модели и весов входа. Входная ворота принимает решения о том, какие значения важны и должны быть пропущены через модель. Сигмоидальная функция используется в входной вороте, которая принимает решения о том, какие значения пропустить через рекуррентную сеть. Ноль сбрасывает значение, а 1 сохраняет его. Функция TanH также используется здесь, которая решает, насколько важны входные значения для модели, варьируясь от -1 до 1.
После того, как текущие входы и состояние памяти учтены, выходная ворота решает, какие значения передать на следующий временной шаг. В выходной вороте значения анализируются и присваивается важность, варьирующаяся от -1 до 1. Это регулирует данные, прежде чем они будут переданы на следующий шаг. Наконец, задача забывающей вороты – сбросить информацию, которую модель считает ненужной для принятия решения о характере входных значений. Забывающая ворота использует сигмоидальную функцию на значениях, выдающую числа от 0 (забыть это) до 1 (сохранить это).
Нейронная сеть LSTM состоит из специальных слоёв LSTM, которые могут интерпретировать последовательные данные, и плотных слоёв, описанных выше. Как только данные проходят через слои LSTM, они поступают в плотные слои.








