
AI 101
Что такое дерево решений?
Что такое дерево решений?
A Древо решений — это полезный алгоритм машинного обучения, используемый как для задач регрессии, так и для классификации. Название «дерево решений» происходит от того факта, что алгоритм продолжает делить набор данных на все меньшие и меньшие части, пока данные не будут разделены на отдельные экземпляры, которые затем классифицируются. Если бы вы визуализировали результаты работы алгоритма, то способ разделения категорий напоминал бы дерево со множеством листьев.
Это краткое определение дерева решений, но давайте углубимся в то, как работают деревья решений. Лучшее понимание того, как работают деревья решений, а также варианты их использования, поможет вам узнать, когда их использовать в ваших проектах машинного обучения.
Формат дерева решений
Дерево решений очень похоже на блок-схему. Чтобы использовать блок-схему, вы начинаете с начальной точки или корня диаграммы, а затем в зависимости от того, как вы отвечаете критериям фильтрации этого начального узла, вы переходите к одному из следующих возможных узлов. Этот процесс повторяется до тех пор, пока не будет достигнут конец.
Деревья решений работают по существу таким же образом, при этом каждый внутренний узел в дереве является своего рода критерием проверки/фильтрации. Узлы снаружи, конечные точки дерева, являются метками для рассматриваемой точки данных и называются «листьями». Ветви, которые ведут от внутренних узлов к следующему узлу, являются признаками или соединениями признаков. Правила, используемые для классификации точек данных, представляют собой пути, идущие от корня к листьям.
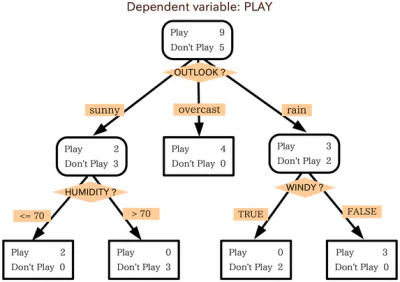
Алгоритмы для деревьев решений
Деревья решений работают на алгоритмическом подходе, который разбивает набор данных на отдельные точки данных на основе разных критериев. Эти разбиения выполняются с разными переменными или разными функциями набора данных. Например, если цель состоит в том, чтобы определить, описываются ли входные признаки собакой или кошкой, переменными, по которым разбиваются данные, могут быть такие вещи, как «когти» и «лай».
Итак, какие алгоритмы используются для фактического разделения данных на ветви и листья? Существуют различные методы, которые можно использовать для разделения дерева, но наиболее распространенным методом разделения, вероятно, является метод, называемый «рекурсивный бинарный раскол». При выполнении этого метода разделения процесс начинается с корня, и количество признаков в наборе данных представляет собой возможное количество возможных разделений. Функция используется для определения того, сколько точности будет стоить каждое возможное разделение, и разделение производится с использованием критериев, которые жертвуют наименьшей точностью. Этот процесс осуществляется рекурсивно, и подгруппы формируются с использованием одной и той же общей стратегии.
Для того, чтобы определить стоимость сплита, используется функция стоимости. Для задач регрессии и задач классификации используется другая функция стоимости. Цель обеих стоимостных функций состоит в том, чтобы определить, какие ветви имеют наиболее схожие значения отклика или самые однородные ветви. Учтите, что вы хотите, чтобы тестовые данные определенного класса следовали определенным путям, и это интуитивно понятно.
С точки зрения функции стоимости регрессии для рекурсивного двоичного разделения алгоритм, используемый для расчета стоимости, выглядит следующим образом:
сумма (y - предсказание) ^ 2
Прогноз для конкретной группы точек данных представляет собой среднее значение ответов обучающих данных для этой группы. Все точки данных проходят через функцию стоимости, чтобы определить стоимость для всех возможных разделений, и выбирается разделение с наименьшей стоимостью.
Что касается функции затрат для классификации, то она выглядит следующим образом:
G = сумма (пк * (1 – пк))
Это показатель Джини, и он является мерой эффективности разделения, основанной на том, сколько экземпляров разных классов находится в группах, полученных в результате разделения. Другими словами, он количественно определяет, насколько смешаны группы после разделения. Оптимальное разделение — это когда все группы, полученные в результате разделения, состоят только из входных данных одного класса. Если было создано оптимальное разделение, значение «pk» будет либо 0, либо 1, а G будет равно нулю. Возможно, вы сможете догадаться, что наихудший случай разделения — это тот, в котором классы в разделении представлены 50-50 в случае бинарной классификации. В этом случае значение «pk» будет равно 0.5, а G также будет равно 0.5.
Процесс разделения завершается, когда все точки данных превращены в листья и классифицированы. Тем не менее, вы можете захотеть остановить рост дерева раньше. Большие сложные деревья склонны к переоснащению, но для борьбы с этим можно использовать несколько различных методов. Один из методов уменьшения переобучения — указать минимальное количество точек данных, которые будут использоваться для создания листа. Другой метод борьбы с переоснащением — ограничение дерева определенной максимальной глубиной, которая определяет длину пути от корня до листа.
Другой процесс, связанный с созданием деревьев решений. обрезает. Сокращение может помочь повысить производительность дерева решений за счет удаления ветвей, содержащих функции, которые имеют небольшую прогностическую силу или мало важны для модели. Таким образом, сложность дерева снижается, снижается вероятность его переобучения и повышается прогностическая полезность модели.
При выполнении обрезки процесс может начинаться либо с вершины дерева, либо с нижней части дерева. Однако самый простой способ отсечения — начать с листьев и попытаться удалить узел, содержащий наиболее распространенный класс в этом листе. Если при этом точность модели не ухудшается, то изменение сохраняется. Существуют и другие методы, используемые для выполнения обрезки, но описанный выше метод — сокращение с уменьшением количества ошибок — вероятно, является наиболее распространенным методом обрезки дерева решений.
Рекомендации по использованию деревьев решений
Деревья принятия решений часто полезны когда необходимо выполнить классификацию, но время вычислений является основным ограничением. Деревья решений могут прояснить, какие функции в выбранных наборах данных обладают наибольшей прогностической силой. Кроме того, в отличие от многих алгоритмов машинного обучения, где правила, используемые для классификации данных, могут быть трудными для интерпретации, деревья решений могут отображать интерпретируемые правила. Деревья решений также могут использовать как категориальные, так и непрерывные переменные, что означает, что требуется меньше предварительной обработки по сравнению с алгоритмами, которые могут обрабатывать только один из этих типов переменных.
Деревья решений, как правило, не очень хорошо работают, когда используются для определения значений непрерывных атрибутов. Другое ограничение деревьев решений заключается в том, что при выполнении классификации, если есть несколько обучающих примеров, но много классов, дерево решений имеет тенденцию быть неточным.










