
AI 101
Что такое линейная регрессия?
Что такое линейная регрессия?
Линейная регрессия — это алгоритм, используемый для прогнозирования или визуализации связь между двумя разными функциями/переменными. В задачах линейной регрессии исследуются два типа переменных: зависимая переменная и независимая переменная. Независимая переменная — это переменная, которая существует сама по себе и не зависит от другой переменной. По мере корректировки независимой переменной уровни зависимой переменной будут колебаться. Зависимая переменная - это изучаемая переменная, и это то, что модель регрессии решает / пытается предсказать. В задачах линейной регрессии каждое наблюдение/экземпляр состоит как из значения зависимой переменной, так и из значения независимой переменной.
Это было краткое объяснение линейной регрессии, но давайте удостоверимся, что лучше понимаем линейную регрессию, взглянув на ее пример и изучив формулу, которую она использует.
Понимание линейной регрессии
Предположим, что у нас есть набор данных, охватывающий размеры жестких дисков и стоимость этих жестких дисков.
Предположим, что набор данных, который у нас есть, состоит из двух разных характеристик: объема памяти и стоимости. Чем больше памяти мы приобретаем для компьютера, тем выше стоимость покупки. Если бы мы нанесли отдельные точки данных на точечный график, мы могли бы получить график, который выглядит примерно так:

Точное соотношение памяти и стоимости может варьироваться в зависимости от производителя и модели жесткого диска, но в целом тенденция данных такова, что она начинается в левом нижнем углу (где жесткие диски дешевле и имеют меньшую емкость) и перемещаются к вверху справа (где диски дороже и имеют большую емкость).
Если бы у нас был объем памяти по оси X и стоимость по оси Y, линия, отражающая взаимосвязь между переменными X и Y, начиналась бы в левом нижнем углу и тянулась бы в правый верхний угол.
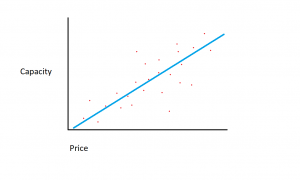
Функция регрессионной модели заключается в определении линейной функции между переменными X и Y, которая лучше всего описывает взаимосвязь между двумя переменными. В линейной регрессии предполагается, что Y можно рассчитать из некоторой комбинации входных переменных. Связь между входными переменными (X) и целевыми переменными (Y) можно изобразить, проведя линию через точки на графике. Линия представляет собой функцию, которая лучше всего описывает отношение между X и Y (например, при каждом увеличении X на 3 Y увеличивается на 2). Цель состоит в том, чтобы найти оптимальную «линию регрессии» или линию/функцию, которая лучше всего соответствует данным.
Линии обычно представляются уравнением: Y = m*X + b. X относится к зависимой переменной, а Y — к независимой переменной. Между тем, m — это наклон линии, определяемый «подъемом» над «пробегом». Специалисты по машинному обучению представляют знаменитое уравнение наклонной линии немного по-другому, используя вместо этого следующее уравнение:
у(х) = w0 + w1 * х
В приведенном выше уравнении y — это целевая переменная, тогда как «w» — это параметры модели, а вход — «x». Итак, уравнение читается так: «Функция, дающая Y, в зависимости от X равна параметрам модели, умноженным на признаки». Параметры модели корректируются во время обучения, чтобы получить наиболее подходящую линию регрессии.
Множественная линейная регрессия

Фото: Cbaf через Wikimedia Commons, Public Domain (https://commons.wikimedia.org/wiki/File:2d_multiple_linear_regression.gif)
Описанный выше процесс применяется к простой линейной регрессии или регрессии к наборам данных, где имеется только один признак/независимая переменная. Однако регрессия также может быть выполнена с несколькими функциями. В случае "множественная линейная регрессия», уравнение расширяется на количество переменных, найденных в наборе данных. Другими словами, в то время как уравнение для обычной линейной регрессии y(x) = w0 + w1 * x, уравнение для множественной линейной регрессии будет y(x) = w0 + w1x1 плюс веса и входные данные для различных признаков. Если мы представим общее количество весов и признаков как w(n)x(n), то мы могли бы представить формулу следующим образом:
y(x) = w0 + w1x1 + w2x2 + … + w(n)x(n)
После создания формулы линейной регрессии модель машинного обучения будет использовать разные значения весов, рисуя разные линии соответствия. Помните, что цель состоит в том, чтобы найти линию, которая лучше всего соответствует данным, чтобы определить, какая из возможных комбинаций весов (и, следовательно, какая возможная линия) лучше всего соответствует данным и объясняет взаимосвязь между переменными.
Функция стоимости используется для измерения того, насколько предполагаемые значения Y близки к фактическим значениям Y при заданном конкретном значении веса. Функция стоимости для линейной регрессии — это среднеквадратическая ошибка, которая просто берет среднюю (квадратичную) ошибку между прогнозируемым значением и истинным значением для всех различных точек данных в наборе данных. Функция стоимости используется для расчета стоимости, которая фиксирует разницу между прогнозируемым целевым значением и истинным целевым значением. Если линия соответствия находится далеко от точек данных, стоимость будет выше, в то время как стоимость будет становиться меньше, чем ближе линия подходит к захвату истинных отношений между переменными. Затем веса модели корректируются до тех пор, пока не будет найдена конфигурация веса, дающая наименьшую ошибку.










