
AI 101
Что такое переоснащение?
Что такое переоснащение?
Когда вы обучаете нейронную сеть, вы должны избегать переобучения. переобучения Это проблема в машинном обучении и статистике, когда модель слишком хорошо изучает закономерности набора обучающих данных, прекрасно объясняя набор обучающих данных, но не в состоянии обобщить свою предсказательную силу на другие наборы данных.
Иными словами, в случае модели с переобучением она часто будет показывать чрезвычайно высокую точность в наборе обучающих данных, но низкую точность в отношении данных, собранных и пропущенных через модель в будущем. Это краткое определение переобучения, но давайте рассмотрим концепцию переобучения более подробно. Давайте посмотрим, как возникает переоснащение и как его можно избежать.
Понимание «подгонки» и недостаточной подгонки
Полезно взглянуть на концепцию недостаточного оснащения исоответствоватьобычно при обсуждении переобучения. Когда мы обучаем модель, мы пытаемся разработать структуру, способную прогнозировать природу или класс элементов в наборе данных на основе функций, описывающих эти элементы. Модель должна быть способна объяснить закономерность в наборе данных и предсказать классы будущих точек данных на основе этой закономерности. Чем лучше модель объясняет взаимосвязь между особенностями обучающей выборки, тем более «подходящей» является наша модель.
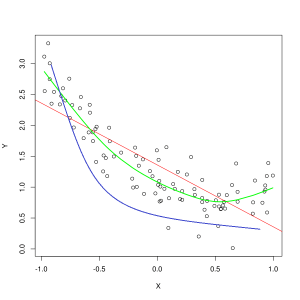
Синяя линия представляет прогнозы модели, которая не подходит, а зеленая линия представляет модель, которая лучше подходит. Фото: Пеп Рока, Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Модель, которая плохо объясняет взаимосвязь между особенностями обучающих данных и, следовательно, не может точно классифицировать будущие примеры данных, называется недостаточное оснащение обучающие данные. Если бы вы построили график прогнозируемой взаимосвязи неподходящей модели с фактическим пересечением функций и меток, прогнозы отклонились бы от истины. Если бы у нас был график с помеченными фактическими значениями тренировочного набора, сильно неподходящая модель резко пропустила бы большинство точек данных. Модель с лучшим соответствием может прорезать путь через центр точек данных, при этом отдельные точки данных лишь немного отклоняются от прогнозируемых значений.
Недообучение часто может происходить, когда для создания точной модели недостаточно данных или при попытке разработать линейную модель с нелинейными данными. Больше обучающих данных или больше функций часто помогают уменьшить недообучение.
Так почему бы нам просто не создать модель, которая прекрасно объясняет каждую точку обучающих данных? Ведь идеальная точность желательна? Создание модели, которая слишком хорошо изучила шаблоны обучающих данных, является причиной переобучения. Набор обучающих данных и другие будущие наборы данных, которые вы пропустите через модель, не будут точно такими же. Скорее всего, во многих отношениях они будут очень похожи, но в ключевых моментах они также будут различаться. Таким образом, разработка модели, которая прекрасно объясняет обучающий набор данных, означает, что вы получите теорию о взаимосвязи между функциями, которая плохо обобщается на другие наборы данных.
Понимание переобучения
Переоснащение происходит, когда модель слишком хорошо изучает детали в наборе обучающих данных, что приводит к тому, что модель страдает, когда прогнозы делаются на внешних данных. Это может произойти, когда модель не только изучает особенности набора данных, но также изучает случайные колебания или шум в наборе данных, придавая важность этим случайным/неважным событиям.
Переобучение чаще происходит при использовании нелинейных моделей, поскольку они более гибкие при изучении функций данных. Алгоритмы непараметрического машинного обучения часто имеют различные параметры и методы, которые можно применять для ограничения чувствительности модели к данным и, таким образом, уменьшения переобучения. В качестве примера, модели деревьев решений очень чувствительны к переоснащению, но для случайного удаления некоторых деталей, изученных моделью, можно использовать технику, называемую обрезкой.
Если бы вы построили прогнозы модели по осям X и Y, у вас была бы линия прогноза, которая зигзагообразно движется вперед и назад, что отражает тот факт, что модель слишком старалась уместить все точки в наборе данных. его объяснение.
Контроль переобучения
Когда мы обучаем модель, мы в идеале хотим, чтобы модель не делала ошибок. Когда производительность модели приближается к правильным прогнозам для всех точек данных в обучающем наборе данных, соответствие становится лучше. Модель с хорошей подгонкой способна объяснить почти весь обучающий набор данных без переобучения.
По мере того, как модель тренируется, ее производительность со временем улучшается. Частота ошибок модели будет уменьшаться по мере прохождения времени обучения, но она уменьшается только до определенного момента. Точка, в которой производительность модели на тестовом наборе снова начинает расти, обычно является точкой, в которой происходит переобучение. Чтобы получить наилучшее соответствие модели, мы хотим остановить обучение модели в точке с наименьшими потерями в обучающем наборе, прежде чем ошибка снова начнет увеличиваться. Оптимальную точку остановки можно определить, построив график производительности модели на протяжении всего времени обучения и остановив обучение, когда потери будут минимальными. Однако один из рисков, связанных с этим методом контроля переобучения, заключается в том, что указание конечной точки для обучения на основе производительности теста означает, что тестовые данные в некоторой степени включаются в процедуру обучения и теряют свой статус чисто «нетронутых» данных.
Есть несколько способов борьбы с переоснащением. Одним из методов уменьшения переобучения является использование тактики повторной выборки, которая работает путем оценки точности модели. Вы также можете использовать Проверка набор данных в дополнение к тестовому набору и построить график точности обучения по сравнению с проверочным набором вместо тестового набора данных. Это делает ваш тестовый набор данных невидимым. Популярным методом повторной выборки является перекрестная проверка K-fold. Этот метод позволяет разделить данные на подмножества, на которых обучается модель, а затем анализируется производительность модели на подмножествах, чтобы оценить, как модель будет работать с внешними данными.
Использование перекрестной проверки — один из лучших способов оценить точность модели на невидимых данных, а в сочетании с набором данных проверки переобучение часто можно свести к минимуму.










