KI 101
Was ist Overfitting?
Was ist Overfitting?
Wenn Sie ein neuronales Netzwerk trainieren, müssen Sie Overfitting vermeiden. Overfitting ist ein Problem im Bereich des maschinellen Lernens und der Statistik, bei dem ein Modell die Muster eines Trainingsdatensatzes zu gut lernt, den Trainingsdatensatz perfekt erklärt, aber seine Vorhersagekraft nicht auf andere Datensätze verallgemeinern kann.
Um es anders auszudrücken, zeigt ein Modell mit Overfitting oft eine extrem hohe Genauigkeit auf dem Trainingsdatensatz, aber eine niedrige Genauigkeit auf Daten, die in der Zukunft gesammelt und durch das Modell laufen. Das ist eine kurze Definition von Overfitting, aber lassen Sie uns den Begriff Overfitting genauer betrachten. Lassen Sie uns sehen, wie Overfitting auftritt und wie es vermieden werden kann.
Verständnis von “Fit” und Underfitting
Es ist hilfreich, den Begriff Underfitting und “Fit” im Allgemeinen zu betrachten, wenn man über Overfitting spricht. Wenn wir ein Modell trainieren, versuchen wir, ein Framework zu entwickeln, das in der Lage ist, die Natur oder Klasse von Elementen in einem Datensatz vorherzusagen, basierend auf den Merkmalen, die diese Elemente beschreiben. Ein Modell sollte in der Lage sein, eine Beziehung in einem Datensatz zu erklären und die Klassen von zukünftigen Datenpunkten basierend auf dieser Beziehung vorherzusagen. Je besser das Modell die Beziehung zwischen den Merkmalen des Trainingsdatensatzes erklärt, desto “besser passt” unser Modell.

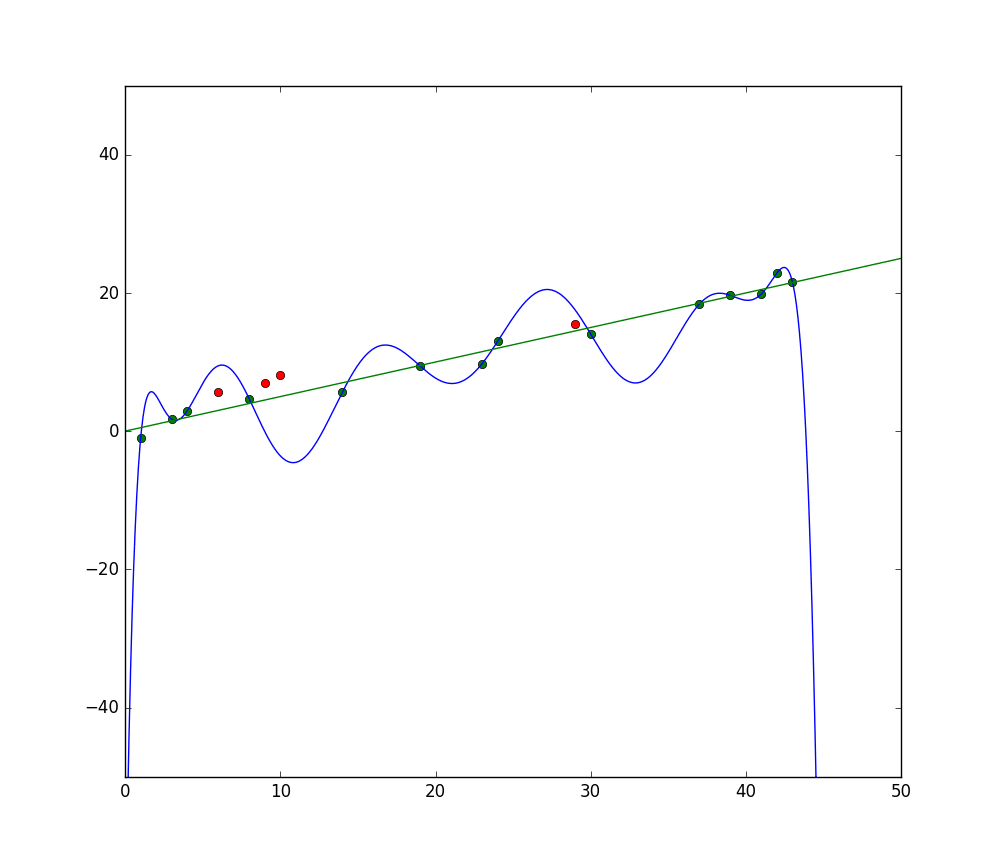
Die blaue Linie stellt die Vorhersagen eines Modells dar, das unterfitting, während die grüne Linie ein besseres Modell darstellt. Foto: Pep Roca via Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Ein Modell, das die Beziehung zwischen den Merkmalen des Trainingsdatensatzes schlecht erklärt und daher nicht in der Lage ist, zukünftige Datenbeispiele genau zu klassifizieren, unterfitting den Trainingsdatensatz. Wenn Sie die vorhergesagte Beziehung eines unterfitting-Modells gegen die tatsächliche Beziehung zwischen den Merkmalen und Labels grafisch darstellen, würden die Vorhersagen vom Ziel abweichen. Wenn wir ein Diagramm mit den tatsächlichen Werten eines Trainingsdatensatzes hätten, würde ein stark unterfitting-Modell die meisten Datenpunkte deutlich verfehlen. Ein Modell mit einem besseren Fit könnte einen Pfad durch die Mitte der Datenpunkte schneiden, wobei die einzelnen Datenpunkte nur leicht von den vorhergesagten Werten abweichen.
Underfitting kann oft auftreten, wenn es nicht genug Daten gibt, um ein genaues Modell zu erstellen, oder wenn man versucht, ein lineares Modell mit nicht-linearen Daten zu erstellen. Mehr Trainingsdaten oder mehr Merkmale können oft helfen, Underfitting zu reduzieren.
Warum sollten wir nicht einfach ein Modell erstellen, das jeden Punkt im Trainingsdatensatz perfekt erklärt? Sicherlich ist perfekte Genauigkeit wünschenswert? Das Erstellen eines Modells, das die Muster des Trainingsdatensatzes zu gut gelernt hat, führt zu Overfitting. Der Trainingsdatensatz und andere, zukünftige Datensätze, die durch das Modell laufen, sind nicht genau gleich. Sie sind wahrscheinlich in vielen Aspekten sehr ähnlich, aber sie unterscheiden sich auch in wichtigen Aspekten. Daher führt das Erstellen eines Modells, das den Trainingsdatensatz perfekt erklärt, dazu, dass Sie eine Theorie über die Beziehung zwischen den Merkmalen entwickeln, die sich nicht gut auf andere Datensätze verallgemeinern lässt.
Verständnis von Overfitting
Overfitting tritt auf, wenn ein Modell die Details innerhalb des Trainingsdatensatzes zu gut lernt, was dazu führt, dass das Modell bei Vorhersagen auf externen Daten leidet. Dies kann auftreten, wenn das Modell nicht nur die Merkmale des Datensatzes lernt, sondern auch zufällige Fluktuationen oder Rauschen innerhalb des Datensatzes lernt und diesen zufälligen/unwichtigen Ereignissen Bedeutung beimisst.
Overfitting ist wahrscheinlicher, wenn nicht-lineare Modelle verwendet werden, da sie flexibler sind, wenn sie Datenmerkmale lernen. Nicht-parametrische maschinelle Lernalgorithmen haben oft verschiedene Parameter und Techniken, die angewendet werden können, um die Empfindlichkeit des Modells gegenüber den Daten zu begrenzen und damit Overfitting zu reduzieren. Als Beispiel sind Entscheidungsbäume sehr anfällig für Overfitting, aber eine Technik namens Beschneiden kann verwendet werden, um zufällig einige der Details zu entfernen, die das Modell gelernt hat.
Wenn Sie die Vorhersagen des Modells auf den X- und Y-Achsen grafisch darstellen, hätten Sie eine Vorhersagelinie, die hin und her zigzagt, was darauf hinweist, dass das Modell zu sehr versucht hat, alle Punkte im Datensatz in seine Erklärung einzubeziehen.
Kontrolle von Overfitting
Wenn wir ein Modell trainieren, möchten wir idealerweise, dass das Modell keine Fehler macht. Wenn die Leistung des Modells gegenüber der Anzahl der korrekten Vorhersagen auf dem Trainingsdatensatz konvergiert, wird der Fit besser. Ein Modell mit einem guten Fit kann den Trainingsdatensatz ohne Overfitting erklären.
Wenn ein Modell trainiert wird, verbessert sich seine Leistung über die Zeit. Die Fehlerrate des Modells sinkt, während die Trainingszeit vergeht, aber sie sinkt nur bis zu einem bestimmten Punkt. Der Punkt, an dem die Leistung des Modells auf dem Testdatensatz wieder anfängt zu steigen, ist typischerweise der Punkt, an dem Overfitting auftritt. Um den besten Fit für ein Modell zu erhalten, möchten wir das Modell am Punkt stoppen, an dem der Verlust auf dem Trainingsdatensatz am niedrigsten ist, bevor der Fehler wieder anfängt zu steigen. Der optimale Stoppunkt kann durch grafische Darstellung der Leistung des Modells während der Trainingszeit und Stoppen der Trainierung, wenn der Verlust am niedrigsten ist, bestimmt werden. Es gibt jedoch ein Risiko bei dieser Methode, Overfitting zu kontrollieren, da die Festlegung des Endpunkts der Trainierung basierend auf der Testleistung bedeutet, dass die Testdaten Teil des Trainingsprozesses werden und ihre Eigenschaft als “unberührte” Daten verlieren.
Es gibt verschiedene Möglichkeiten, Overfitting zu bekämpfen. Eine Methode, um Overfitting zu reduzieren, besteht darin, eine Resampling-Taktik zu verwenden, die durch Schätzung der Genauigkeit des Modells funktioniert. Sie können auch ein Validierungsdatensatz zusätzlich zum Testdatensatz verwenden und die Trainingsgenauigkeit gegen den Validierungsdatensatz anstelle des Testdatensatzes plotten. Dies hält Ihren Testdatensatz unberührt. Eine beliebte Resampling-Methode ist die K-fache Kreuzvalidierung. Diese Technik ermöglicht es Ihnen, Ihre Daten in Untermengen zu unterteilen, auf denen das Modell trainiert wird, und dann die Leistung des Modells auf diesen Untermengen zu analysieren, um zu schätzen, wie das Modell auf externen Daten abschneiden wird.
Die Verwendung von Kreuzvalidierung ist eine der besten Möglichkeiten, die Genauigkeit eines Modells auf unberührten Daten zu schätzen, und wenn sie mit einem Validierungsdatensatz kombiniert wird, kann Overfitting oft auf ein Minimum reduziert werden.








