Künstliche Intelligenz
Andrew Ng kritisiert die Kultur des Overfitting im Machine Learning
Andrew Ng, eine der einflussreichsten Stimmen im Machine Learning der letzten Dekade, äußert derzeit Bedenken hinsichtlich des Ausmaßes, in dem die Branche Innovationen in der Modellarchitektur über Daten betont – und insbesondere, in welchem Ausmaß sie es zulässt, dass “überanpassete” Ergebnisse als verallgemeinerte Lösungen oder Fortschritte dargestellt werden.
Diese sind umfassende Kritik an der aktuellen Kultur des Machine Learning, die von einer der höchsten Autoritäten in diesem Bereich stammt und Auswirkungen auf das Vertrauen in einen Sektor hat, der von Ängsten über einen dritten Zusammenbruch des Geschäftsvertrauens in die AI-Entwicklung in einem Zeitraum von sechzig Jahren heimgesucht wird.
Ng, ein Professor an der Stanford-Universität, ist auch einer der Gründer von deeplearning.ai und veröffentlichte im März eine Mitteilung auf der Website der Organisation, die eine jüngste Rede von ihm auf ein paar Kernempfehlungen verdichtete:
Zunächst, dass die Forschungsgemeinschaft aufhören sollte, sich zu beschweren, dass die Datenreinigung 80 % der Herausforderungen im Machine Learning darstellt, und sich an die Arbeit machen sollte, robuste MLOps-Methoden und -Praktiken zu entwickeln.
Zweitens, dass sie sich von den “leichten Erfolgen” entfernen sollte, die durch Überanpassung von Daten an ein Machine-Learning-Modell erzielt werden können, damit es auf diesem Modell gut funktioniert, aber nicht verallgemeinert oder ein weit verbreiteter Modell produziert.
Akzeptanz der Herausforderung der Datenarchitektur und -kuratierung
“Meine Meinung”, schrieb Ng, “ist, dass wenn 80 Prozent unserer Arbeit die Datenpräparation ist, dann ist die Sicherstellung der Datenqualität die wichtige Arbeit eines Machine-Learning-Teams.”
Er fuhr fort:
“Anstatt darauf zu warten, dass Ingenieure zufällig auf die beste Möglichkeit stoßen, ein Dataset zu verbessern, hoffe ich, dass wir MLOps-Tools entwickeln können, die uns helfen, AI-Systeme, einschließlich der Erstellung hochwertiger Datensätze, wiederholbarer und systematischer zu machen.
“MLOps ist ein neu entstandenes Feld, und verschiedene Menschen definieren es unterschiedlich. Aber ich denke, dass das wichtigste Organisationsprinzip von MLOps-Teams und -Tools darin bestehen sollte, den konsistenten und hochwertigen Fluss von Daten während aller Phasen eines Projekts sicherzustellen. Dies wird viele Projekte reibungsloser machen.”
In einer live gestreamten Frage-und-Antwort-Sitzung auf Zoom Ende April sprach Ng über den Anwendungsfehler in Machine-Learning-Analyse-Systemen für Radiologie:
“Es stellt sich heraus, dass wenn wir Daten aus dem Stanford-Krankenhaus sammeln, dann wir trainieren und testen auf Daten aus dem gleichen Krankenhaus, tatsächlich, wir können Papier veröffentlichen, die zeigen, dass [die Algorithmen] mit menschlichen Radiologen bei der Erkennung bestimmter Zustände vergleichbar sind.
“…[Wenn] man das gleiche Modell, das gleiche AI-System, in ein älteres Krankenhaus auf der Straße, mit einer älteren Maschine, und der Techniker ein leicht unterschiedliches Bildgebungsprotokoll verwendet, dann driftet diese Daten, um die Leistung des AI-Systems erheblich zu verschlechtern. Im Gegensatz dazu kann jeder menschliche Radiologe auf die Straße zum älteren Krankenhaus gehen und gut funktionieren.”
Unterspezifikation ist keine Lösung
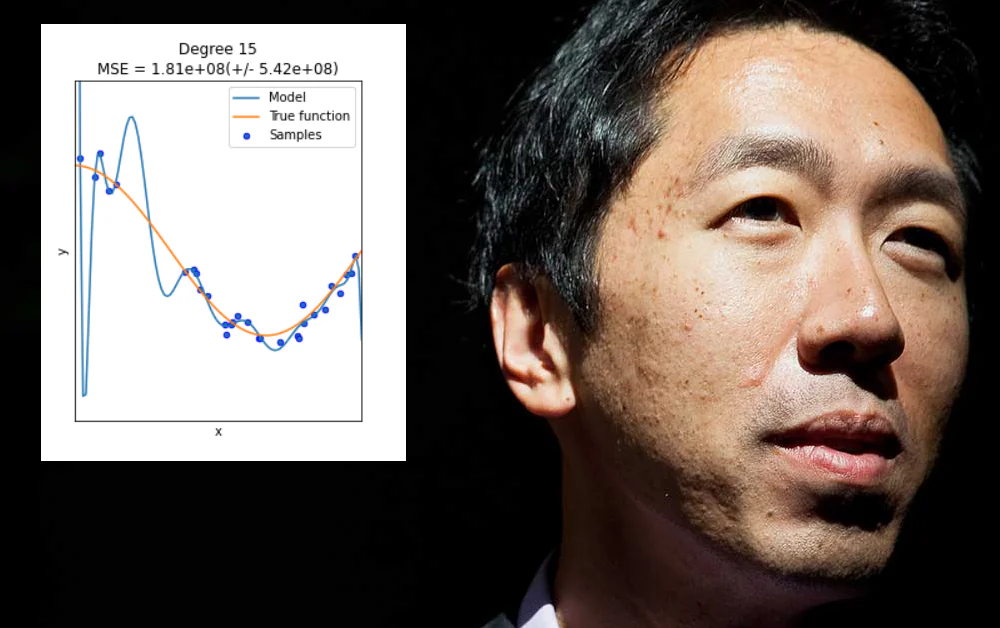
Überanpassung tritt auf, wenn ein Machine-Learning-Modell speziell dafür ausgelegt ist, die Eigenheiten eines bestimmten Datensatzes (oder der Art und Weise, wie die Daten formatiert sind) zu berücksichtigen. Dies kann beispielsweise die Festlegung von Gewichten umfassen, die gute Ergebnisse aus diesem Datensatz erzeugen, aber nicht “verallgemeinern” auf andere Daten.
In vielen Fällen werden solche Parameter auf “nicht-Daten”-Aspekte des Trainingsatzes definiert, wie die spezifische Auflösung der gesammelten Informationen oder andere Eigenheiten, die nicht garantiert in anderen nachfolgenden Datensätzen wiederkehren.
Obwohl es schön wäre, ist Überanpassung kein Problem, das durch blindes Erweitern des Umfangs oder der Flexibilität der Datenarchitektur oder des Modellentwurfs gelöst werden kann, wenn tatsächlich weit anwendbare und hoch saliente Merkmale benötigt werden, die in einer Vielzahl von Datenumgebungen gut funktionieren – eine schwierigere Herausforderung.
Im Allgemeinen führt diese Art von “Unterspezifikation” nur zu den Problemen, die Ng kürzlich dargelegt hat, bei denen ein Machine-Learning-Modell bei nicht gesehenen Daten fehlschlägt. Der Unterschied in diesem Fall besteht darin, dass das Modell nicht deshalb fehlschlägt, weil die Daten oder die Datenformatierung sich von dem überanpassenden ursprünglichen Trainingsatz unterscheiden, sondern weil das Modell zu flexibel anstelle von zu spröde ist.
Ende 2020 veröffentlichte die Studie Unterspezifikation stellt Herausforderungen für die Glaubwürdigkeit im modernen Machine Learning dar heftige Kritik an dieser Praxis und trug die Namen von nicht weniger als vierzig Machine-Learning-Forschern und Wissenschaftlern von Google und MIT, unter anderem.
Die Studie kritisiert “Abkürzungen beim Lernen” und beobachtet, wie unterspezifizierte Modelle auf wilde Abwege geraten können, basierend auf dem zufälligen Startpunkt, an dem die Modelltraining beginnt. Die Mitwirkenden bemerken:
‘Wir haben gesehen, dass Unterspezifikation in praktischen Machine-Learning-Pipelines in vielen Bereichen allgegenwärtig ist. Tatsächlich, dank Unterspezifikation, werden substantiell wichtige Aspekte der Entscheidungen durch willkürliche Entscheidungen wie den zufälligen Seed-Punkt bestimmt, der für die Parameterinitialisierung verwendet wird.’
Wirtschaftliche Auswirkungen des Kulturwandels
Trotz seiner akademischen Qualifikationen ist Ng kein luftiger Akademiker, sondern hat tiefgreifende und hochrangige Branchenerfahrung als Mitgründer von Google Brain und Coursera, als ehemaliger Chief Scientist für Big Data und AI bei Baidu und als Gründer von Landing AI, das 175 Millionen USD für neue Start-ups in der Branche verwaltet.
Wenn er sagt “Alle AI, nicht nur Gesundheitswesen, haben eine Lücke zwischen Proof-of-Concept und Produktion”, ist es als Weckruf für einen Sektor gedacht, dessen aktuelles Niveau an Hype und gesprenkelter Geschichte es zunehmend als unsichere langfristige Geschäftsinvestition charakterisiert, geplagt von Problemen der Definition und des Umfangs.
Trotzdem können proprietäre Machine-Learning-Systeme, die in situ gut funktionieren und in anderen Umgebungen fehlschlagen, die Art von Markteroberung darstellen, die Industrieinvestitionen belohnen könnte. Die Darstellung des “Overfitting-Problems” im Kontext eines beruflichen Risikos bietet eine unaufrichtige Möglichkeit, Unternehmensinvestitionen in Open-Source-Forschung zu monetarisieren und (effektiv) proprietäre Systeme zu produzieren, bei denen eine Reproduktion durch Wettbewerber möglich, aber problematisch ist.
Ob dieser Ansatz langfristig funktionieren wird, hängt davon ab, in welchem Ausmaß echte Durchbrüche im Machine Learning weiterhin immer größere Investitionen erfordern und ob alle produktiven Initiativen unweigerlich zu FAANG migrieren werden, wegen der kolossalen Ressourcen, die für Hosting und Betrieb erforderlich sind.












