Anderson 视角
为什么对抗性图像攻击不容小觑
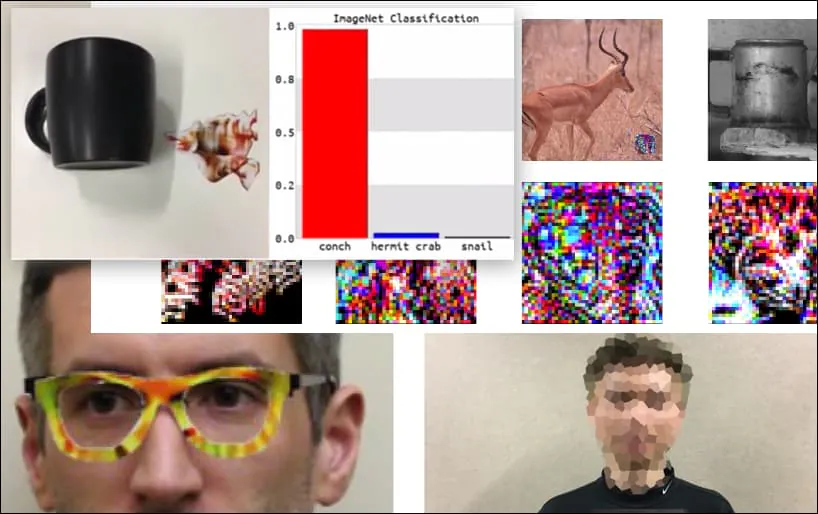
利用精心设计的对抗性图像攻击图像识别系统,过去五年来一直被认为是一个有趣但微不足道的概念验证。然而,来自澳大利亚的新研究表明,商业AI项目中广泛使用流行的图像数据集可能会产生一个新的、持久的安全问题。
这两年来,阿德莱德大学的一组学者一直试图解释关于基于AI的图像识别系统的未来的一件非常重要的事情。
这件事情现在很难(且非常昂贵)解决,而且一旦当前的图像识别研究趋势在5-10年内完全发展成为商业化和工业化的部署,那么解决它将会非常昂贵。
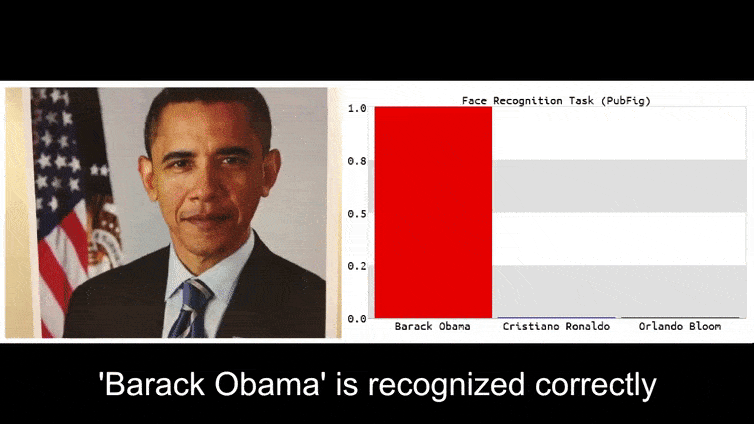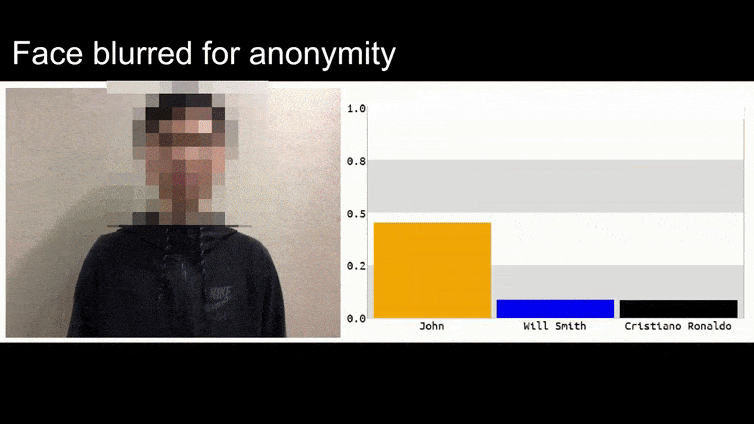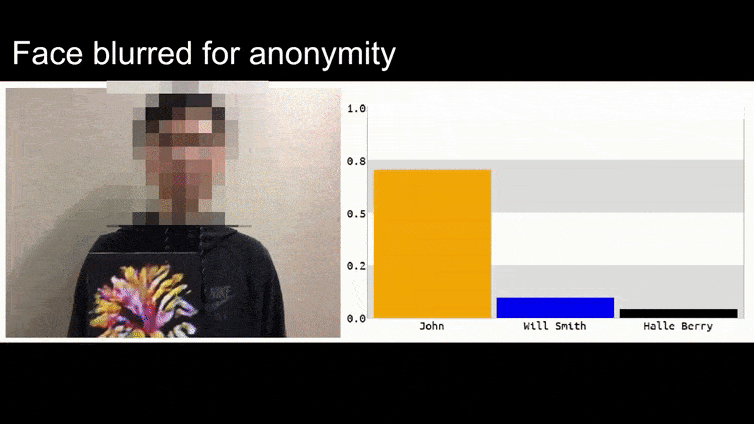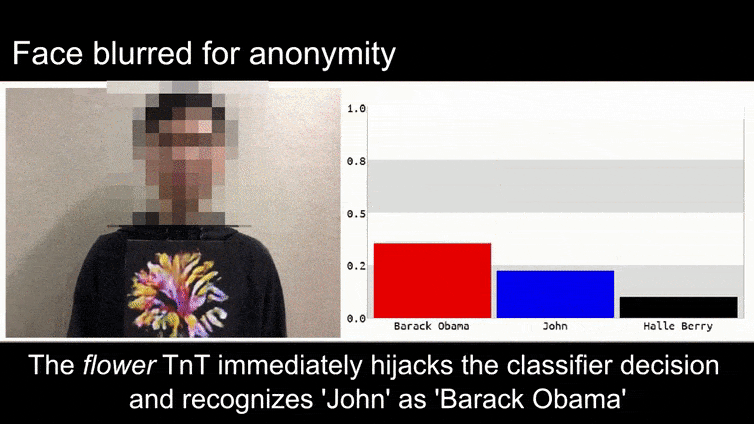
在我们深入探讨之前,让我们看一下一个被归类为巴拉克·奥巴马的花的例子,这是团队在项目页面上发布的六个视频之一:
来源:https://www.youtube.com/watch?v=Klepca1Ny3c
在上面的图像中,一个面部识别系统明显知道如何识别巴拉克·奥巴马,却被欺骗成80%的把握,认为一个匿名人士拿着一张精心制作、打印的对抗性图像的花也是巴拉克·奥巴马。该系统甚至不在乎“假面”是在主题的胸部,而不是肩膀上。
尽管研究人员能够通过生成连贯的图像(一朵花)而不是通常的随机噪声来实现这种身份捕获,但这种愚蠢的漏洞似乎在计算机视觉的安全研究中经常出现。例如,2016年能够欺骗面部识别的奇怪图案眼镜,或者专门设计的对抗性图像,尝试重写道路标志。
如果您感兴趣,正在被攻击的卷积神经网络(CNN)模型是VGGFace(VGG-16),它是在哥伦比亚大学的PubFig数据集上训练的。研究人员开发的其他攻击样本使用了不同的资源和组合。

一个键盘被重新分类为一只海螺,在ImageNet上的WideResNet50模型中。研究人员还确保该模型没有偏向海螺。请参阅https://www.youtube.com/watch?v=dhTTjjrxIcU的完整视频,获取更多演示。
图像识别作为新兴攻击向量
研究人员概述和说明的众多攻击并不是针对特定数据集或使用它们的特定机器学习架构的批评。它们也不能通过切换数据集或模型、重新训练模型或其他“简单”的补救措施来轻松防御,这些补救措施使得机器学习从业者对这种类型的恶作剧的零星演示持轻蔑态度。
相反,阿德莱德团队的漏洞是当前图像识别AI开发架构中的一个中心弱点,这可能会使许多未来的图像识别系统容易受到攻击者的操纵,并使任何后续的防御措施处于被动地位。
想象一下,将最新的对抗性攻击图像(例如上面的花)作为“零日漏洞”添加到未来的安全系统中,就像当前的反恶意软件和防病毒框架每天更新其病毒定义一样。
新型对抗性图像攻击的可能性将是无穷的,因为系统的基础架构没有预见到下游的问题,就像互联网、千年虫和比萨斜塔一样。
那么,我们又是如何为这种情况做准备的呢?
获取攻击数据
像上面“花”的例子这样的对抗性图像是通过访问训练计算机模型的图像数据集来生成的。你不需要“特权”访问训练数据(或模型架构),因为最流行的数据集(和许多训练模型)在一个强大的和不断更新的torrent场景中广泛可用。
例如,计算机视觉数据集的庞然大物ImageNet,可以通过Torrent获取,绕过其通常的限制,并提供诸如验证集等重要的次要元素。

来源:https://academictorrents.com
如果您拥有数据,您可以(如阿德莱德研究人员所观察到的那样)有效地“逆向工程”任何流行的数据集,例如CityScapes或CIFAR。
在PubFig数据集的例子中,它使得“奥巴马花”成为可能,哥伦比亚大学已经解决了图像数据集再分发的版权问题,通过指导研究人员如何通过策划的链接重现数据集,而不是直接提供编译后的数据集,观察到“这似乎是其他大型基于Web的数据库正在演变的方式”。
在大多数情况下,这是不必要的:Kaggle估计,计算机视觉中最受欢迎的十个图像数据集是:CIFAR-10和CIFAR-100(均可直接下载);CALTECH-101和256(均可用且可作为torrent);MNIST(官方可用,也可作为torrent);ImageNet(见上文);Pascal VOC(可用,也可作为torrent);MS COCO(可用,也可作为torrent);Sports-1M(可用);和YouTube-8M(可用)。
这种可用性也代表了更广泛的可用计算机视觉图像数据集,因为在“发表或灭亡”的开源开发文化中,晦涩难懂是死亡。
无论如何,新数据集的稀缺性、图像集开发的高成本、对“老爱好”的依赖以及简单地适应旧数据集的趋势都加剧了新阿德莱德论文中概述的问题。
对抗性图像攻击方法的典型批评
机器学习工程师对最新的对抗性图像攻击技术有效性的最常见批评是,该攻击是针对特定的数据集、特定的模型或两者的;它不能被“概括”到其他系统中;因此,它只代表着一个微不足道的威胁。
第二个最常见的抱怨是,攻击是“白盒”,这意味着您需要直接访问训练环境或数据。这在大多数情况下确实是一个不太可能的情景——例如,如果您想利用伦敦大都会警察的面部识别系统的训练过程,您需要用控制台或斧头进入NEC。
流行计算机视觉数据集的长期“DNA”
关于第一个批评,我们应该考虑,不仅仅是计算机视觉行业中只有一小部分数据集占据主导地位,而且这些数据集是“平台无关”和高度可转移的。
根据其能力,任何计算机视觉训练架构都将在ImageNet数据集中找到某些对象和类的特征。一些架构可能会找到比其他架构更多的特征,或比其他架构建立更多有用的连接,但所有架构都应找到至少最高级别的特征:

ImageNet数据,具有最低可行的正确识别次数 – ‘高级’特征。
正是这些“高级”特征区分和“指纹”数据集,并且是可靠的“钩子”,可以挂载长期的对抗性图像攻击方法,可以跨越不同的系统,并随着“旧”数据集在新研究和产品中被延续而增长。
更复杂的架构将产生更准确和细粒度的识别、特征和类:

然而,对抗性攻击生成器越多地依赖于这些“较低”特征(即“年轻的白人男性”而不是“面部”),它在跨越或后来的架构中就越不有效,这些架构使用“不同版本”的原始数据集——例如子集或过滤后的数据集,其中原始数据集中的许多图像不在其中:

对“零化”预训练模型的对抗性攻击
如果你下载一个预训练模型,该模型最初是在一个非常流行的数据集上训练的,然后给它完全新的数据会怎样?
该模型已经在(例如)ImageNet上训练过,现在只剩下权重,这些权重可能需要数周或数月才能训练,并且现在已经准备好帮助你识别与原始(现在缺失)数据中存在的对象类似的事物。

在训练架构中删除原始数据后,剩下的是模型的“先入之见”,即模型倾向于以它最初学习的方式对对象进行分类,这基本上会导致许多原始“签名”重新形成并再次容易受到相同的老式对抗性图像攻击方法的攻击。
这些权重很有价值。没有数据或权重,您基本上只有一个空架构,没有数据。您将不得不从头开始训练它,这将需要大量的时间和计算资源,就像原始作者一样(可能使用比您更强大的硬件和更高的预算)。
问题在于,权重已经相当成熟和稳健。虽然它们在训练中会有所适应,但它们将像在原始数据上一样在您的新数据上表现,并产生特征,这些特征可以被对抗性攻击系统所利用。
从长远来看,这也保留了12年或更老的计算机视觉数据集的“DNA”,这些数据集可能已经从开源努力到商业化部署经历了显著的演化,即使原始训练数据在项目开始时被完全丢弃。其中一些商业部署可能不会在几年内发生。
无需白盒
关于第二个常见批评,新论文的作者发现,他们用精心设计的图像欺骗识别系统的能力在多个架构中具有很高的可转移性。
虽然他们观察到他们的“通用自然主义对抗补丁”(TnT)方法是第一个使用可识别的图像(而不是随机扰动噪声)来欺骗图像识别系统的方法,但作者还指出:
“TnTs对从ImageNet数据集的大规模视觉识别任务中的WideResNet50到PubFig数据集的面部识别任务中的VGG-face模型等多个最先进的分类器都有效,包括有针对性和无针对性的攻击。”
“TnTs可以具备:i)与特洛伊木马攻击方法中使用的触发器相同的自然主义;ii)对抗性示例对其他网络的概括和可转移性。”
“这引发了人们对已经部署的DNN以及未来DNN部署的安全和安全问题,在那里攻击者可以使用不显眼的自然外观的物体补丁来误导神经网络系统,而无需篡改模型并冒着被发现的风险。”
作者建议,传统的对抗措施(例如降低网络的清晰度)可能会在理论上提供一些防御,但“TnTs仍然可以成功绕过这些最先进的可证明的防御方法,大多数防御系统都能达到0%的鲁棒性”。
可能的其他解决方案包括联邦学习,其中贡献图像的来源受到保护,以及可以直接在训练时“加密”数据的新方法,例如南京航空航天大学最近提出的方法。
即使在这些情况下,训练真正新图像数据也很重要——现在,围绕世界各地的开发周期中使用的最流行的CV数据集中的图像和相关注释已经如此根深蒂固,以至于它们更像软件,而不是数据;这是一种通常在几年内没有显著更新的软件。
结论
对抗性图像攻击不仅是由开源机器学习实践使得可能,也是由一种企业AI开发文化使得可能的,这种文化出于以下几个原因倾向于重用成熟的计算机视觉数据集:它们已经被证明是有效的;它们比“从头开始”要便宜得多;并且它们由学术界和工业界的先驱思想和组织维护和更新,在资金和人员方面很难被单个公司复制。
此外,在许多情况下,数据不是原始的(与CityScapes不同),图像是在最近的隐私和数据收集实践争议之前收集的,这使得这些较旧的数据集处于一种半合法的中间状态,这可能看起来像是一个“安全港”,从公司的角度来看。
TnT攻击!通用自然主义对抗补丁对深度神经网络系统由阿德莱德大学的Bao Gia Doan、Minhui Xue、Ehsan Abbasnejad、Damith C. Ranasinghe以及Rutgers大学计算机科学系的Shiqing Ma共同撰写。
更新于2021年12月1日,7:06 GMT+2 – 更正了一个拼写错误。












