人工智能
在随机噪声而非真实图像上训练计算机视觉模型

来自 MIT 计算机科学与人工智能实验室(CSAIL)的研究人员已经尝试使用随机噪声图像在计算机视觉数据集中训练计算机视觉模型,并发现这种方法出乎意料地有效:

实验中生成的模型,按性能排序。 来源:https://openreview.net/pdf?id=RQUl8gZnN7O
将明显的“视觉垃圾”输入到流行的计算机视觉架构中不应该产生这样的性能。在上面的图像的最右边,黑色柱代表四个“真实”数据集(在 Imagenet-100 上)的准确率分数。虽然前面的“随机噪声”数据集(以各种颜色表示,见左上角的索引)无法达到这种准确率,但它们几乎都在可接受的上下限范围内(红色虚线)。
在这种意义上,“准确率”并不意味着结果一定看起来像一个 面部,一个 教堂,一个 披萨,或任何其他特定的领域,您可能有兴趣创建一个 图像合成 系统,例如生成对抗网络或编码器/解码器框架。
相反,它意味着 CSAIL 模型从图像数据中推导出广泛适用的中心“真理”,这些数据看起来如此不结构化,以至于不应该能够提供它。
多样性与自然主义
这些结果也不能归因于 过拟合:Open Review 上作者和审稿人之间的讨论表明,将来自视觉多样数据集(例如“枯叶”、“分形”和“程序噪声”——见下图)的不同内容混合到训练数据集中 实际上提高了准确率。
这表明(这有点革命性的概念)一种新的“欠拟合”类型,其中“多样性”优于“自然主义”。
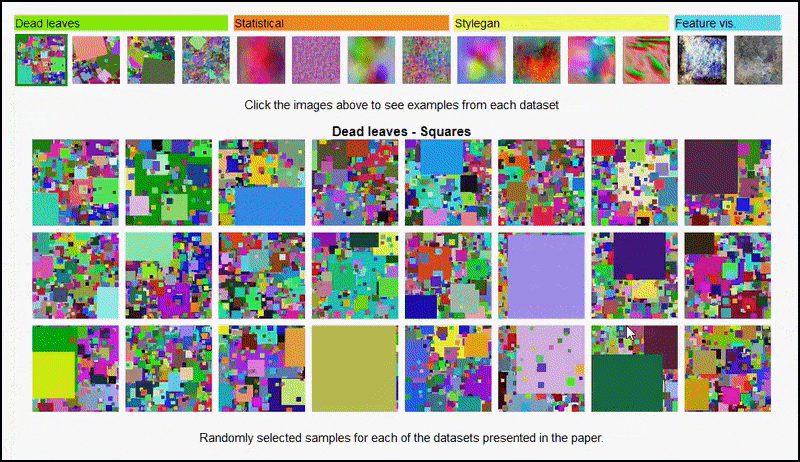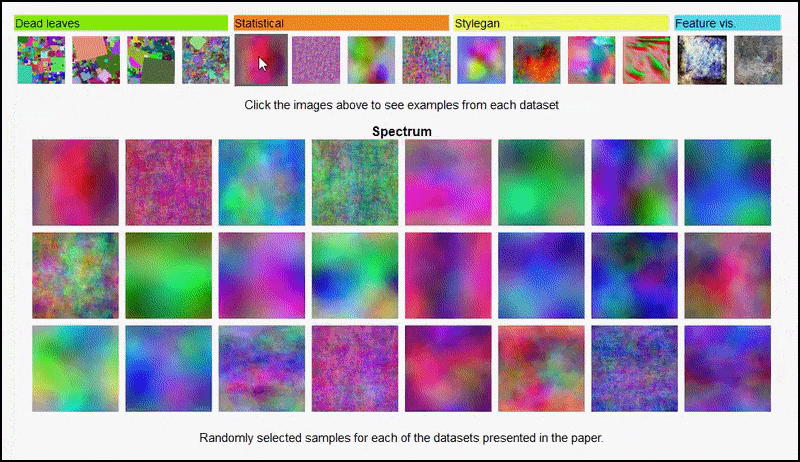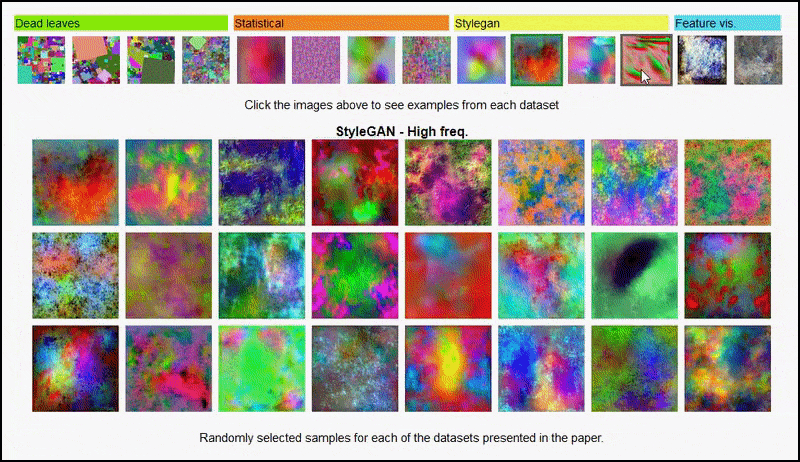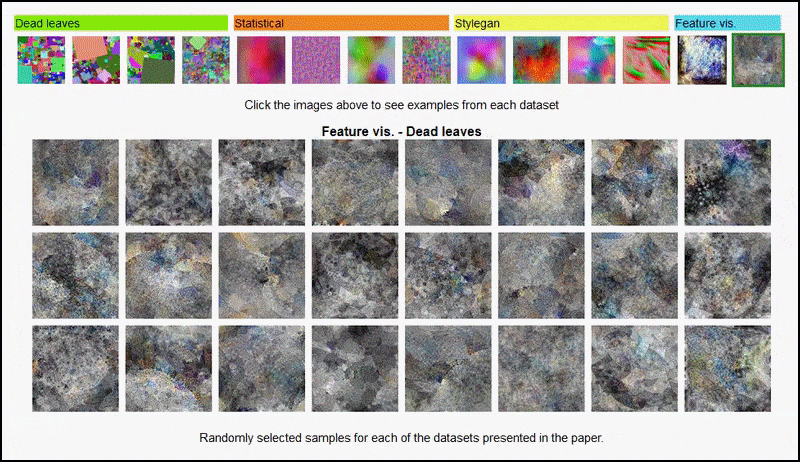
实验中使用的不同类型的随机图像数据集的交互式查看。 来源:https://mbaradad.github.io/learning_with_noise/
研究人员获得的结果质疑了图像基于神经网络和每年以惊人的速度抛给它们的“真实世界”图像之间的基本关系,并意味着获得、策划和处理 超大规模图像数据集 的需求最终可能变得不再必要。作者指出:
‘当前的视觉系统是在大型数据集上训练的,而这些数据集带来了成本:策划很昂贵,它们继承了人类的偏见,并且存在隐私和使用权的担忧。为了应对这些成本,人们对从更便宜的数据源(如未标记的图像)学习的兴趣大幅增加。 ‘
‘在本文中,我们更进一步,问是否可以完全放弃真实图像数据集,只通过程序噪声过程来学习。’
研究人员建议,当前的机器学习架构可能从图像中推断出比以前认为的更为基本(或至少是意外)的东西,并且“无意义”的图像可能会以更低的成本传达大量的知识,即使使用 ad hoc 合成数据,通过在训练时间生成随机图像的数据集架构:
‘我们确定了两个使合成数据适合训练视觉系统的关键属性:1)自然主义,2)多样性。有趣的是,最自然的数据并不总是最好的,因为自然主义可能会以多样性的代价为代价。 ‘
‘事实上,自然主义数据有帮助可能并不令人惊讶,这表明确实,大规模的真实数据是有价值的。然而,我们发现,重要的是数据不一定是 真实的,而是 自然的,即它必须捕获真实数据的某些结构属性。 ‘
‘这些属性中的很多可以在简单的噪声模型中捕获。 ‘

使用实验中各种“随机图像”数据集的 AlexNet派生编码器的特征可视化,涵盖第3和第5(最终)卷积层。使用的方法遵循 2017年Google AI研究的方法。
该 论文 由六位 CSAIL 研究人员撰写,均为共同贡献,题为 通过查看噪声来学习视觉,并在悉尼举行的第 35 届神经信息处理系统会议(NeurIPS 2021)上发表。
这项工作被 推荐 为 NeurIPS 2021 的聚光灯选择,同行评论者将这篇论文描述为“科学突破”,开辟了“伟大的研究领域”,即使它提出了更多的问题而不是答案。
在论文中,作者总结道:
‘我们已经证明,当使用过去关于自然图像统计的研究结果设计时,这些数据集可以成功地训练视觉表示。我们希望这篇论文能够激发研究能够产生结构化噪声的新生成模型的兴趣,即使在使用多样化的视觉任务时也能实现更高的性能。 ‘
‘是否有可能达到与 ImageNet 预训练相同的性能?也许在没有大型特定任务训练集的情况下,预训练的最佳方法可能不是使用标准的真实数据集,例如 ImageNet。’












