人工智能
AudioSep:使用自然语言描述分离任何声音
LASS 或语言查询音频源分离是 CASA 或计算听觉场景分析的新范式,旨在使用自然语言查询从给定的音频混合中分离目标声音。虽然 LASS 框架在过去的几年中在特定音频源(如乐器)方面取得了显著进步,但它们无法在开放域中分离目标音频。
AudioSep 是一个基础模型,旨在通过使用自然语言查询来分离目标音频,解决 LASS 框架的当前限制。AudioSep 框架的开发者在大规模多模态数据集上进行了广泛的训练,并评估了该框架在各种音频任务(包括乐器分离、音频事件分离和语音增强)上的性能。AudioSep 的初始性能满足了基准测试,因为它展示了令人印象深刻的零样本学习能力和强大的音频分离性能。
在本文中,我们将更深入地探讨 AudioSep 框架的工作原理,评估模型的架构、用于训练和评估的数据集以及 AudioSep 模型工作中的基本概念。让我们从 CASA 框架的基本介绍开始。
CASA、USS、QSS、LASS 框架:AudioSep 的基础
CASA 或计算听觉场景分析框架是开发人员设计机器听觉系统的框架,使其能够像人类使用听觉系统一样感知复杂的音频环境。声音分离,特别是目标声音分离,是 CASA 框架内的一个基本研究领域,旨在解决“鸡尾酒会问题”或从单个音频源录音或文件中分离真实世界的音频录音。声音分离的重要性主要归因于其广泛的应用,包括音乐源分离、音频源分离、语音增强、目标声音识别等。
过去大部分的声音分离工作主要围绕着分离一个或多个音频源,如音乐分离或语音分离。一个名为 USS 或通用声音分离的新模型旨在分离真实世界音频录音中的任意声音。然而,分离音频混合中的每个声音源是一个具有挑战性和限制性的任务,主要是由于世界上存在大量不同的声音源,这也是 USS 方法不适用于实时运行的实用应用的主要原因。
USS 方法的一个可行替代方案是 QSS 或基于查询的音频分离方法,旨在根据特定的查询从音频混合中分离单个或目标声音源。由于 QSS 框架允许开发人员和用户根据需要从混合中提取所需的音频源,因此 QSS 方法对于数字实用应用(如多媒体内容编辑或音频编辑)是一个更实用的解决方案。
此外,开发人员最近提出了 QSS 框架的扩展,即 LASS 框架或语言查询音频源分离框架,旨在使用目标音频源的自然语言描述从音频混合中分离任意声音源。由于 LASS 框架允许用户使用一组自然语言指令提取目标音频源,因此它可能成为数字音频应用中的一个强大的工具。与传统的音频查询或视觉查询方法相比,使用自然语言指令进行音频分离具有更大的优势,因为它增加了灵活性,并使查询信息的获取更加容易和方便。此外,与使用预定义查询集的标签查询音频分离框架相比,LASS 框架不限制输入查询的数量,并且可以无缝地推广到开放域。
最初,LASS 框架依赖于监督学习,其中模型在一组标记的音频-文本对数据上进行训练。然而,这种方法的主要问题是标记的音频-文本数据的可用性有限。为了减少 LASS 框架对标记音频-文本数据的依赖,模型使用多模态监督学习方法进行训练。使用多模态监督方法的主要目标是使用多模态对比预训练模型(如 CLIP 或对比语言图像预训练模型)作为框架的查询编码器。由于 CLIP 框架能够将文本嵌入与其他模态(如音频或视觉)对齐,因此它允许开发人员使用数据丰富的模态训练 LASS 模型,并在零样本设置中与文本数据进行干预。
为了解决 LASS 框架的当前限制,开发人员引入了 AudioSep,一种基础模型,旨在使用自然语言描述从音频混合中分离声音。AudioSep 的当前重点是开发一个预训练的音频分离模型,利用现有的大规模多模态数据集,使 LASS 模型能够在开放域应用中泛化。总之,AudioSep 模型是:“一个使用自然语言查询或描述在开放域中进行通用声音分离的基础模型,训练于大规模音频和多模态数据集”。
AudioSep:关键组件和架构
AudioSep 框架的架构由两个关键组件组成:文本编码器和分离模型。
文本编码器
AudioSep 框架使用 CLIP 或对比语言图像预训练模型的文本编码器或 CLAP 或对比语言音频预训练模型来提取自然语言查询中的文本嵌入。输入文本查询由一系列“N”令牌组成,然后由文本编码器处理以提取给定输入语言查询的文本嵌入。文本编码器使用一堆变换器块来编码输入文本令牌,并且输出表示在通过变换器层后聚合,结果是具有固定长度的 D 维向量表示,其中 D 对应于 CLAP 或 CLIP 模型的维度,而文本编码器在训练期间被冻结。
CLIP 模型是在大规模图像-文本对数据集上使用对比学习预训练的,这也是其文本编码器学习将文本描述映射到语义空间的原因,该空间也由视觉表示共享。AudioSep 通过使用 CLIP 的文本编码器获得的优势在于,它现在可以使用视觉嵌入作为替代品来扩大或训练 LASS 模型,从而在不需要标记音频-文本数据的情况下训练 LASS 模型。
CLAP 模型的工作方式与 CLIP 模型类似,使用对比学习目标,将音频和语言连接起来,将文本和音频描述放在音频-文本潜在空间中联合起来。
分离模型
AudioSep 框架使用频域 ResUNet 模型作为分离骨干,该模型输入音频片段的混合。框架首先将短时傅里叶变换应用于波形信号以提取复杂的语谱图、幅度语谱图和 X 的相位。然后,模型遵循相同的设置,并构建编码器-解码器网络来处理幅度语谱图。
ResUNet 编码器-解码器网络由 6 个残差块、6 个解码器块和 4 个瓶颈块组成。每个编码器块使用 4 个残差卷积块将语谱图下采样到瓶颈特征,而解码器块使用 4 个残差反卷积块通过上采样特征来获得分离组件。然后,建立每个编码器块和其对应的解码器块之间的跳过连接,操作在相同的上采样或下采样率下进行。框架的残差块由 2 个泄漏 ReLU 激活层、2 个批量归一化层和 2 个卷积层组成。此外,框架还引入了一个额外的残差快捷方式,连接每个单独残差块的输入和输出。ResUNet 模型以复杂的语谱图 X 为输入,并产生幅度掩码 M 为输出,相位残差由文本嵌入条件化,控制语谱图的幅度缩放和旋转角度。然后,可以通过将预测的幅度掩码和相位残差乘以混合的短时傅里叶变换来提取分离的复杂语谱图。

在其框架中,AudioSep 使用 FiLm 或特征级线性调制层来连接分离模型和文本编码器,部署在 ResUNet 中的卷积块之后。
训练和损失
在 AudioSep 模型的训练期间,开发人员使用响亮度增强方法,并通过使用预测波形和真实波形之间的 L1 损失函数来端到端地训练 AudioSep 框架。
数据集和基准
如前面所提到的,AudioSep 是一个基础模型,旨在解决 LASS 模型对标记音频-文本对数据集的当前依赖。AudioSep 模型在多个数据集上进行训练,以使其具备多模态学习能力,以下是开发人员用于训练 AudioSep 框架的数据集和基准的详细描述。
AudioSet
AudioSet 是一个大规模的弱标记音频数据集,包含超过 200 万个 10 秒的音频片段,直接从 YouTube 中提取。AudioSet 数据集中的每个音频片段根据声音类别的存在或不存在进行分类,没有声音事件的具体时间细节。AudioSet 数据集包含超过 500 个不同的音频类别,包括自然声音、人类声音、车辆声音等。
VGGSound
VGGSound 数据集是一个大规模的视觉-音频数据集,也是从 YouTube 中提取的,包含超过 20 万个视频片段,每个视频片段的长度为 10 秒。VGGSound 数据集根据声音类别进行分类,包括人类声音、自然声音、鸟类声音等。使用 VGGSound 数据集可以确保产生目标声音的对象也可以在对应的视觉片段中描述。
AudioCaps
AudioCaps 是目前最大的公开音频字幕数据集,包含超过 5 万个 10 秒的音频片段,来自 AudioSet 数据集。AudioCaps 数据集分为三个类别:训练数据、测试数据和验证数据,音频片段使用 Amazon Mechanical Turk 平台进行人工注释,使用自然语言描述。值得注意的是,训练数据集中的每个音频片段都有一个字幕,而测试和验证数据集中的每个音频片段都有 5 个真实字幕。
ClothoV2
ClothoV2 是一个音频字幕数据集,包含来自 FreeSound 平台的音频片段,每个音频片段使用 Amazon Mechanical Turk 平台进行人工注释,使用自然语言描述。
WavCaps
与 AudioSet 类似,WavCaps 是一个大规模的弱标记音频数据集,包含超过 40 万个音频片段,带有字幕,总运行时间约为 7568 小时的训练数据。WavCaps 数据集中的音频片段来自多个音频源,包括 BBC Sound Effects、AudioSet、FreeSound、SoundBible 等。

训练细节
在训练阶段,AudioSep 模型从训练数据集中随机采样两个来自不同音频片段的音频段,然后将它们混合在一起,创建一个训练混合音, 每个音频段的长度约为 5 秒。然后,模型从波形信号中提取复杂的语谱图,使用大小为 1024 的 Hann 窗口和 320 的 hop 大小。
然后,模型使用 CLIP/CLAP 模型的文本编码器以默认配置进行文本监督来提取文本嵌入。对于分离模型,AudioSep 框架使用一个具有 30 层、6 个编码器块和 6 个解码器块的 ResUNet 层,类似于通用声音分离框架中使用的架构。此外,每个编码器块都有两个具有 3×3 内核大小的卷积层,编码器块的输出特征映射的数量分别为 32、64、128、256、512 和 1024。解码器块与编码器块对称,开发人员使用 Adam 优化器来训练 AudioSep 模型,批量大小为 96。
评估结果
在已见数据集上
以下图表比较了 AudioSep 框架在训练阶段的性能,包括训练数据集。以下图表显示了 AudioSep 框架在与基准系统(包括语音增强模型、LASS 和 CLIP)相比时的基准评估结果。使用 CLIP 文本编码器的 AudioSep 模型表示为 AudioSep-CLIP,而使用 CLAP 文本编码器的 AudioSep 模型表示为 AudioSep-CLAP。

如图所示,AudioSep 框架在使用音频字幕或文本标签作为输入查询时表现良好,结果表明 AudioSep 框架在与以前的基准 LASS 和音频查询声音分离模型相比时具有更好的性能。
在未见数据集上
为了评估 AudioSep 在零样本设置中的性能,开发人员继续评估其在未见数据集上的性能,AudioSep 框架在零样本设置中表现出令人印象深刻的分离性能,结果如下图所示。

此外,以下图像显示了 AudioSep 模型在 Voicebank-Demand 语音增强上的评估结果。

AudioSep 框架的评估结果表明,在零样本设置中,未见数据集上的性能强劲且令人满意,这为在新数据分布上执行声音操作任务铺平了道路。
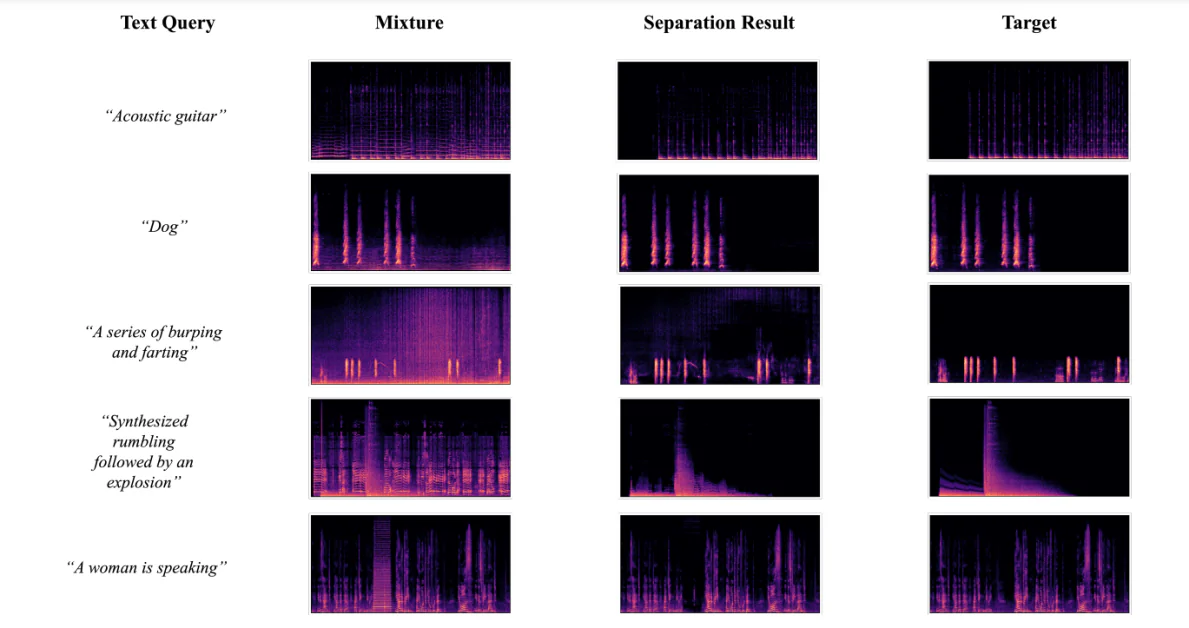
分离结果的可视化
以下图表显示了当开发人员使用 AudioSep-CLAP 框架对不同音频或声音的文本查询进行分离时的分离结果的可视化。结果允许开发人员观察到分离源的语谱图模式接近真实源,这进一步支持了实验中获得的目标结果。
文本查询的比较
开发人员评估了 AudioSep-CLAP 和 AudioSep-CLIP 在 AudioCaps Mini 上的性能,并使用 AudioSet 事件标签、AudioCaps 标题和重新注释的自然语言描述来检查不同查询的影响,以下图表显示了 AudioCaps Mini 的一个示例。

结论
AudioSep 是一个基础模型,旨在成为一个开放域的通用声音分离框架,使用自然语言描述进行音频分离。如评估所见,AudioSep 框架能够使用音频字幕或文本标签作为查询进行零样本和无监督学习,并且其性能优于当前的最先进的音频分离框架,如 LASS,并且可能能够解决流行的音频分离框架的当前限制。












