Artificial Intelligence
How Text-to-3D AI Generation Works: Meta 3D Gen, OpenAI Shap-E and more
By
Aayush Mittal Mittal
The ability to generate 3D digital assets from text prompts represents one of the most exciting recent developments in AI and computer graphics. As the 3D digital asset market is projected to grow from $28.3 billion in 2024 to $51.8 billion by 2029, text-to-3D AI models are poised to play a major role in revolutionizing content creation across industries like gaming, film, e-commerce, and more. But how exactly do these AI systems work? In this article, we’ll take a deep dive into the technical details behind text-to-3D generation.

The Challenge of 3D Generation
Generating 3D assets from text is a significantly more complex task than 2D image generation. While 2D images are essentially grids of pixels, 3D assets require representing geometry, textures, materials, and often animations in three-dimensional space. This added dimensionality and complexity makes the generation task much more challenging.
Some key challenges in text-to-3D generation include:
- Representing 3D geometry and structure
- Generating consistent textures and materials across the 3D surface
- Ensuring physical plausibility and coherence from multiple viewpoints
- Capturing fine details and global structure simultaneously
- Generating assets that can be easily rendered or 3D printed
To tackle these challenges, text-to-3D models leverage several key technologies and techniques.
Key Components of Text-to-3D Systems
Most state-of-the-art text-to-3D generation systems share a few core components:
- Text encoding: Converting the input text prompt into a numerical representation
- 3D representation: A method for representing 3D geometry and appearance
- Generative model: The core AI model for generating the 3D asset
- Rendering: Converting the 3D representation to 2D images for visualization
Let’s explore each of these in more detail.
Text Encoding
The first step is to convert the input text prompt into a numerical representation that the AI model can work with. This is typically done using large language models like BERT or GPT.
3D Representation
There are several common ways to represent 3D geometry in AI models:
- Voxel grids: 3D arrays of values representing occupancy or features
- Point clouds: Sets of 3D points
- Meshes: Vertices and faces defining a surface
- Implicit functions: Continuous functions defining a surface (e.g. signed distance functions)
- Neural radiance fields (NeRFs): Neural networks representing density and color in 3D space
Each has trade-offs in terms of resolution, memory usage, and ease of generation. Many recent models use implicit functions or NeRFs as they allow for high-quality results with reasonable computational requirements.
For example, we can represent a simple sphere as a signed distance function:
import numpy as np
def sphere_sdf(x, y, z, radius=1.0):
return np.sqrt(x**2 + y**2 + z**2) - radius
# Evaluate SDF at a 3D point
point = [0.5, 0.5, 0.5]
distance = sphere_sdf(*point)
print(f"Distance to sphere surface: {distance}")
Generative Model
The core of a text-to-3D system is the generative model that produces the 3D representation from the text embedding. Most state-of-the-art models use some variation of a diffusion model, similar to those used in 2D image generation.
Diffusion models work by gradually adding noise to data, then learning to reverse this process. For 3D generation, this process happens in the space of the chosen 3D representation.
A simplified pseudocode for a diffusion model training step might look like:
def diffusion_training_step(model, x_0, text_embedding): # Sample a random timestep t = torch.randint(0, num_timesteps, (1,)) # Add noise to the input noise = torch.randn_like(x_0) x_t = add_noise(x_0, noise, t) # Predict the noise predicted_noise = model(x_t, t, text_embedding) # Compute loss loss = F.mse_loss(noise, predicted_noise) return loss # Training loop for batch in dataloader: x_0, text = batch text_embedding = encode_text(text) loss = diffusion_training_step(model, x_0, text_embedding) loss.backward() optimizer.step()
During generation, we start from pure noise and iteratively denoise, conditioned on the text embedding.
Rendering
To visualize results and compute losses during training, we need to render our 3D representation to 2D images. This is typically done using differentiable rendering techniques that allow gradients to flow back through the rendering process.
For mesh-based representations, we might use a rasterization-based renderer:
import torch
import torch.nn.functional as F
import pytorch3d.renderer as pr
def render_mesh(vertices, faces, image_size=256):
# Create a renderer
renderer = pr.MeshRenderer(
rasterizer=pr.MeshRasterizer(),
shader=pr.SoftPhongShader()
)
# Set up camera
cameras = pr.FoVPerspectiveCameras()
# Render
images = renderer(vertices, faces, cameras=cameras)
return images
# Example usage
vertices = torch.rand(1, 100, 3) # Random vertices
faces = torch.randint(0, 100, (1, 200, 3)) # Random faces
rendered_images = render_mesh(vertices, faces)
For implicit representations like NeRFs, we typically use ray marching techniques to render views.
Putting it All Together: The Text-to-3D Pipeline
Now that we’ve covered the key components, let’s walk through how they come together in a typical text-to-3D generation pipeline:
- Text encoding: The input prompt is encoded into a dense vector representation using a language model.
- Initial generation: A diffusion model, conditioned on the text embedding, generates an initial 3D representation (e.g. a NeRF or implicit function).
- Multi-view consistency: The model renders multiple views of the generated 3D asset and ensures consistency across viewpoints.
- Refinement: Additional networks may refine geometry, add textures, or enhance details.
- Final output: The 3D representation is converted to a desired format (e.g. textured mesh) for use in downstream applications.
Here’s a simplified example of how this might look in code:
class TextTo3D(nn.Module):
def __init__(self):
super().__init__()
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.diffusion_model = DiffusionModel()
self.refiner = RefinerNetwork()
self.renderer = DifferentiableRenderer()
def forward(self, text_prompt):
# Encode text
text_embedding = self.text_encoder(text_prompt).last_hidden_state.mean(dim=1)
# Generate initial 3D representation
initial_3d = self.diffusion_model(text_embedding)
# Render multiple views
views = self.renderer(initial_3d, num_views=4)
# Refine based on multi-view consistency
refined_3d = self.refiner(initial_3d, views)
return refined_3d
# Usage
model = TextTo3D()
text_prompt = "A red sports car"
generated_3d = model(text_prompt)
Top Text to 3d Asset Models Avaliable
3DGen – Meta
3DGen is designed to tackle the problem of generating 3D content—such as characters, props, and scenes—from textual descriptions.
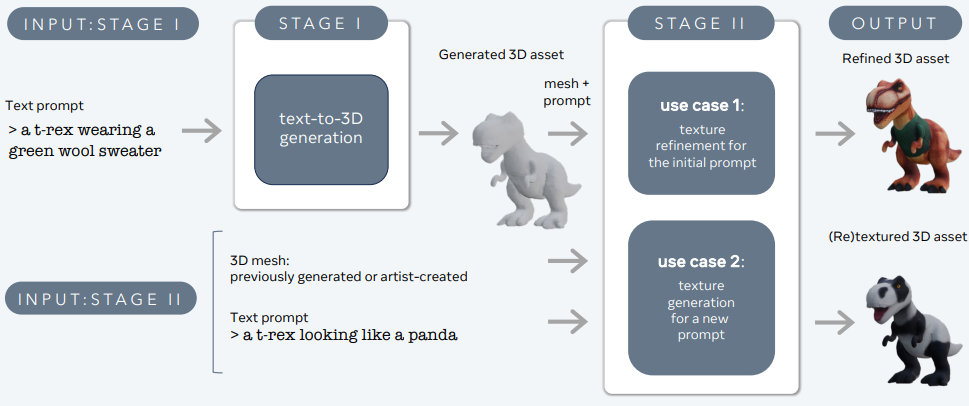
Large Language and Text-to-3D Models – 3d-gen
3DGen supports physically-based rendering (PBR), essential for realistic 3D asset relighting in real-world applications. It also enables generative retexturing of previously generated or artist-created 3D shapes using new textual inputs. The pipeline integrates two core components: Meta 3D AssetGen and Meta 3D TextureGen, which handle text-to-3D and text-to-texture generation, respectively.
Meta 3D AssetGen
Meta 3D AssetGen (Siddiqui et al., 2024) is responsible for the initial generation of 3D assets from text prompts. This component produces a 3D mesh with textures and PBR material maps in about 30 seconds.
Meta 3D TextureGen
Meta 3D TextureGen (Bensadoun et al., 2024) refines the textures generated by AssetGen. It can also be used to generate new textures for existing 3D meshes based on additional textual descriptions. This stage takes approximately 20 seconds.
Point-E (OpenAI)
Point-E, developed by OpenAI, is another notable text-to-3D generation model. Unlike DreamFusion, which produces NeRF representations, Point-E generates 3D point clouds.
Key features of Point-E:
a) Two-stage pipeline: Point-E first generates a synthetic 2D view using a text-to-image diffusion model, then uses this image to condition a second diffusion model that produces the 3D point cloud.
b) Efficiency: Point-E is designed to be computationally efficient, capable of generating 3D point clouds in seconds on a single GPU.
c) Color information: The model can generate colored point clouds, preserving both geometric and appearance information.
Limitations:
- Lower fidelity compared to mesh-based or NeRF-based approaches
- Point clouds require additional processing for many downstream applications
Shap-E (OpenAI):
Building upon Point-E, OpenAI introduced Shap-E, which generates 3D meshes instead of point clouds. This addresses some of the limitations of Point-E while maintaining computational efficiency.
Key features of Shap-E:
a) Implicit representation: Shap-E learns to generate implicit representations (signed distance functions) of 3D objects.
b) Mesh extraction: The model uses a differentiable implementation of the marching cubes algorithm to convert the implicit representation into a polygonal mesh.
c) Texture generation: Shap-E can also generate textures for the 3D meshes, resulting in more visually appealing outputs.
Advantages:
- Fast generation times (seconds to minutes)
- Direct mesh output suitable for rendering and downstream applications
- Ability to generate both geometry and texture
GET3D (NVIDIA):
GET3D, developed by NVIDIA researchers, is another powerful text-to-3D generation model that focuses on producing high-quality textured 3D meshes.
Key features of GET3D:
a) Explicit surface representation: Unlike DreamFusion or Shap-E, GET3D directly generates explicit surface representations (meshes) without intermediate implicit representations.
b) Texture generation: The model includes a differentiable rendering technique to learn and generate high-quality textures for the 3D meshes.
c) GAN-based architecture: GET3D uses a generative adversarial network (GAN) approach, which allows for fast generation once the model is trained.
Advantages:
- High-quality geometry and textures
- Fast inference times
- Direct integration with 3D rendering engines
Limitations:
- Requires 3D training data, which can be scarce for some object categories
Conclusion
Text-to-3D AI generation represents a fundamental shift in how we create and interact with 3D content. By leveraging advanced deep learning techniques, these models can produce complex, high-quality 3D assets from simple text descriptions. As the technology continues to evolve, we can expect to see increasingly sophisticated and capable text-to-3D systems that will revolutionize industries from gaming and film to product design and architecture.
I have spent the past five years immersing myself in the fascinating world of Machine Learning and Deep Learning. My passion and expertise have led me to contribute to over 50 diverse software engineering projects, with a particular focus on AI/ML. My ongoing curiosity has also drawn me toward Natural Language Processing, a field I am eager to explore further.

You may like


The AI Arms Race Intensifies: AMD’s Strategic Partnership with OpenAI


OpenAI Secures Seven-Year, $38 Billion AWS Cloud Partnership


Optimizing Neural Radiance Fields (NeRF) for Real-Time 3D Rendering in E-Commerce Platforms


Claude’s Model Context Protocol (MCP): A Developer’s Guide


Design Patterns in Python for AI and LLM Engineers: A Practical Guide


Microsoft AutoGen: Multi-Agent AI Workflows with Advanced Automation







