Internet-Sicherheit
Warum gegnerische Bildangriffe kein Scherz sind
Der Angriff auf Bilderkennungssysteme mit sorgfältig erstellten gegnerischen Bildern galt in den letzten fünf Jahren als amüsanter, aber trivialer Proof-of-Concept. Neue Forschungsergebnisse aus Australien deuten jedoch darauf hin, dass die gelegentliche Nutzung äußerst beliebter Bilddatensätze für kommerzielle KI-Projekte ein dauerhaftes neues Sicherheitsproblem schaffen könnte.
Seit einigen Jahren versucht eine Gruppe von Wissenschaftlern an der University of Adelaide, etwas wirklich Wichtiges über die Zukunft KI-basierter Bilderkennungssysteme zu erklären.
Es ist etwas, das schwierig (und sehr teuer) zu beheben wäre jetzt sofort, und dessen Behebung unverhältnismäßig teuer wäre, wenn die aktuellen Trends in der Bilderkennungsforschung in 5-10 Jahren vollständig zu kommerziellen und industrialisierten Anwendungen entwickelt wären.
Bevor wir näher darauf eingehen, werfen wir einen Blick auf eine Blume, die als Präsident Barack Obama klassifiziert wird, aus einem der sechs Videos, die das Team auf der Projekt-Seite:
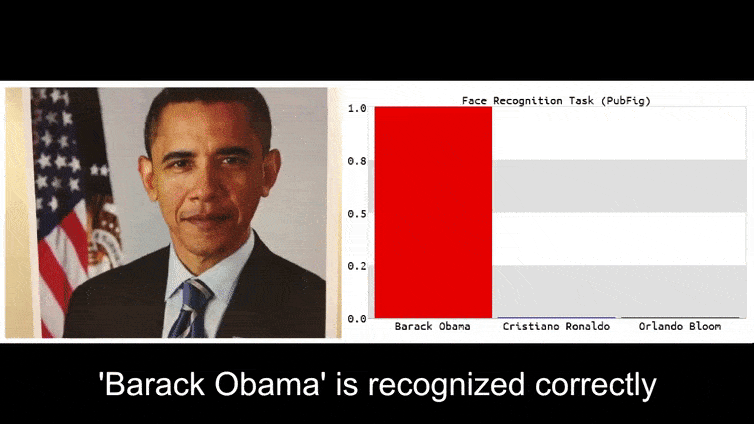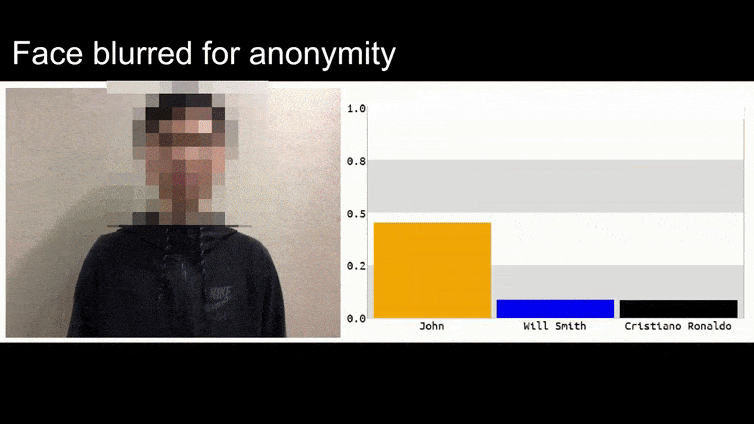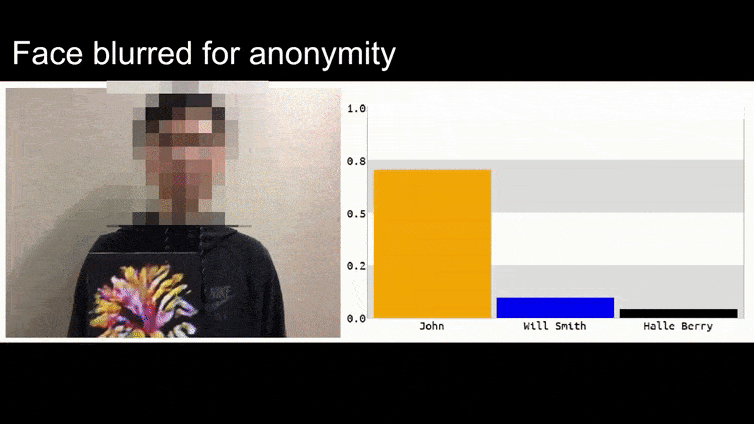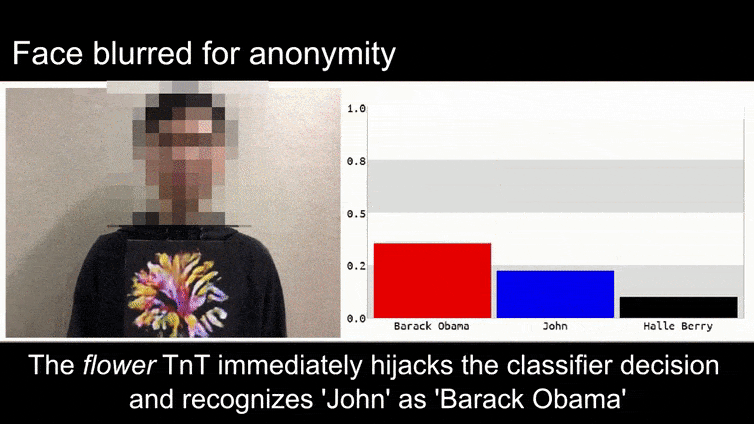
Quelle: https://www.youtube.com/watch?v=Klepca1Ny3c
Im obigen Bild wird ein Gesichtserkennungssystem, das Barack Obama eindeutig erkennen kann, mit 80-prozentiger Sicherheit getäuscht, dass ein anonymisierter Mann, der ein künstlich gedrucktes, gegnerisches Bild einer Blume hält, ebenfalls Barack Obama ist. Dem System ist es sogar egal, dass sich das „falsche Gesicht“ auf der Brust des Motivs und nicht auf seinen Schultern befindet.
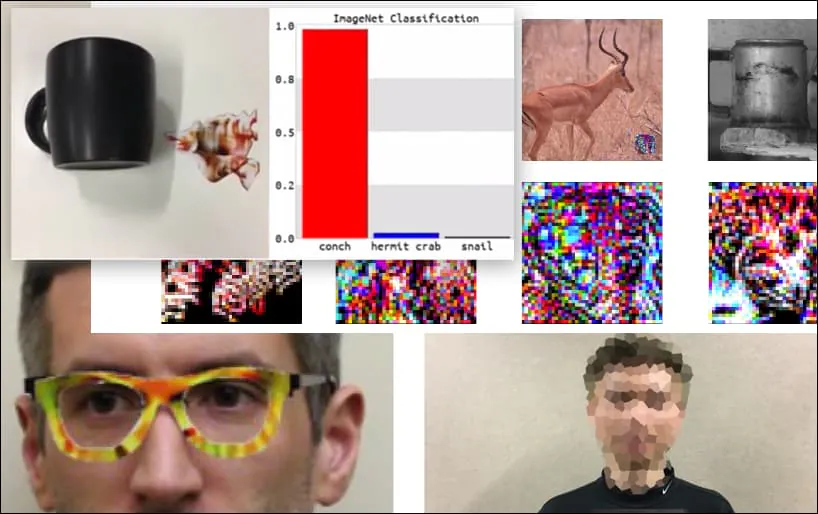
Obwohl es beeindruckend ist, dass es den Forschern gelungen ist, diese Art der Identitätserfassung durch die Erzeugung eines kohärenten Bildes (einer Blume) statt nur des üblichen zufälligen Rauschens zu erreichen, scheinen alberne Exploits wie dieser in der Sicherheitsforschung zum Thema Computer Vision ziemlich regelmäßig aufzutauchen . Zum Beispiel diese seltsam gemusterten Brillen, die die Gesichtserkennung täuschen konnten zurück in 2016oder speziell angefertigte gegnerische Bilder, die Versuchen Sie, Verkehrszeichen umzuschreiben.
Falls es Sie interessiert: Das im obigen Beispiel angegriffene Convolutional Neural Network (CNN)-Modell ist VGGFace (VGG-16), trainiert mit dem PubFig-Datensatz der Columbia University. Andere von den Forschern entwickelte Angriffsbeispiele verwendeten unterschiedliche Ressourcen in unterschiedlichen Kombinationen.

Eine Tastatur wird in einem WideResNet50-Modell auf ImageNet als Muschel neu klassifiziert. Die Forscher haben außerdem sichergestellt, dass das Modell keine Tendenz zu Muscheln aufweist. Das vollständige Video für erweiterte und zusätzliche Demonstrationen finden Sie unter https://www.youtube.com/watch?v=dhTTjjrxIcU
Bilderkennung als neuer Angriffsvektor
Die vielen eindrucksvollen Angriffe, die die Forscher skizzieren und veranschaulichen, sind keine Kritik an einzelnen Datensätzen oder spezifischen Machine-Learning-Architekturen, die diese verwenden. Auch lässt sich gegen sie nicht einfach durch den Wechsel von Datensätzen oder Modellen, das Umschulen von Modellen oder andere „einfache“ Mittel vorgehen, die ML-Praktiker dazu verleiten, über sporadische Demonstrationen dieser Art von Tricksereien zu spotten.
Vielmehr sind die Leistungen des Adelaide-Teams beispielhaft für zentrale Schwäche in der gesamten aktuellen Architektur der Bilderkennungs-KI-Entwicklung; Eine Schwachstelle, die dazu führen könnte, dass viele zukünftige Bilderkennungssysteme einer einfachen Manipulation durch Angreifer ausgesetzt werden und alle nachfolgenden Abwehrmaßnahmen ins Hintertreffen geraten.
Stellen Sie sich vor, die neuesten Bilder feindlicher Angriffe (wie die Blume oben) würden als „Zero-Day-Exploits“ zu den Sicherheitssystemen der Zukunft hinzugefügt, so wie aktuelle Anti-Malware- und Antiviren-Frameworks ihre Virendefinitionen täglich aktualisieren.
Das Potenzial für neuartige Angriffe auf Bilder wäre unerschöpflich, da die grundlegende Architektur des Systems spätere Probleme nicht vorhersah, wie sie auftraten mit dem Internet, hat das Millennium-Käfer und der der Schiefe Turm von Pisa.
Auf welche Weise bereiten wir dies vor?
Die Daten für einen Angriff abrufen
Adversarial-Bilder wie das obige „Blumen“-Beispiel werden durch Zugriff auf die Bilddatensätze generiert, mit denen die Computermodelle trainiert wurden. Sie benötigen keinen „privilegierten“ Zugriff auf Trainingsdaten (oder Modellarchitekturen), da die gängigsten Datensätze (und viele trainierte Modelle) in einer robusten und ständig aktualisierten Torrent-Szene weithin verfügbar sind.
Zum Beispiel ist ImageNet der ehrwürdige Goliath der Computer-Vision-Datensätze für Torrent verfügbar in all seinen vielen Iterationen unter Umgehung seines Üblichen Einschränkungenund Bereitstellung entscheidender sekundärer Elemente, wie z Validierungssätze.

Quelle: https://academictorrents.com
Wenn Sie über die Daten verfügen, können Sie (wie die Forscher in Adelaide feststellen) jeden gängigen Datensatz effektiv „rückwärts entwickeln“, wie zum Beispiel: Stadtlandschaftenden CIFAR.
Im Fall von PubFig, dem Datensatz, der die „Obama-Blume“ im vorherigen Beispiel ermöglichte, hat die Columbia University einen wachsenden Trend zu Urheberrechtsproblemen bei der Weiterverteilung von Bilddatensätzen berücksichtigt, indem sie Forscher anwies, wie sie reproduzieren den Datensatz über kuratierte Links, anstatt die Zusammenstellung direkt verfügbar zu machen, „Dies scheint die Entwicklung anderer großer webbasierter Datenbanken zu sein.“.
In den meisten Fällen ist das nicht nötig: Kaggle Schätzungen dass die zehn beliebtesten Bilddatensätze in der Computer Vision sind: CIFAR-10 und CIFAR-100 (beide). direkt herunterladbar); CALTECH-101 und 256 (beide verfügbar und beide derzeit als Torrents verfügbar); MNIST (offiziell verfügbar, auch auf Torrents); ImageNet (siehe oben); Pascal VOC (verfügbar, auch auf Torrents); MS COCO (verfügbar, und auf Torrents); Sport-1M (verfügbar); und YouTube-8M (verfügbar).
Diese Verfügbarkeit ist auch repräsentativ für die größere Bandbreite verfügbarer Bilddatensätze für Computer Vision, da Unklarheit in einer Open-Source-Entwicklungskultur nach dem Motto „Veröffentlichen oder Untergehen“ tödlich ist.
Auf jeden Fall ist die Knappheit von handhabbar neue Datensätze, die hohen Kosten der Bilddatensatzentwicklung, die Abhängigkeit von „alten Favoriten“ und die Tendenz, Passen Sie einfach ältere Datensätze an Sie alle verschärfen das im neuen Adelaide-Papier dargelegte Problem.
Typische Kritikpunkte an gegnerischen Bildangriffsmethoden
Der häufigste und hartnäckigste Kritikpunkt von Ingenieuren des maschinellen Lernens an der Wirksamkeit der neuesten kontradiktorischen Bildangriffstechnik ist, dass es sich um einen Angriff handelt spezifisch für einen bestimmten Datensatz, ein bestimmtes Modell oder beides; dass es nicht auf andere Systeme „generalisierbar“ ist und folglich nur eine triviale Bedrohung darstellt.
Die zweithäufigste Beschwerde ist, dass es sich um einen gegnerischen Bildangriff handelt „weiße Box“Dies bedeutet, dass Sie direkten Zugriff auf die Trainingsumgebung oder die Daten benötigen. Dies ist in den meisten Fällen tatsächlich ein unwahrscheinliches Szenario – beispielsweise, wenn man den Trainingsprozess für die Gesichtserkennungssysteme nutzen möchte der Londoner Metropolitan Police, müssten Sie sich in NEC, entweder mit einer Konsole oder einer Axt.
Die langfristige „DNA“ beliebter Computer Vision-Datensätze
Was die erste Kritik betrifft, sollten wir nicht nur bedenken, dass Jahr für Jahr eine Handvoll Computer-Vision-Datensätze die Branche nach Sektoren dominieren (z. B. ImageNet für mehrere Objekttypen, CityScapes für Fahrszenen usw.). FFHQ zur Gesichtserkennung); aber auch, dass sie als einfache annotierte Bilddaten „plattformunabhängig“ und in hohem Maße übertragbar sind.
Abhängig von seinen Fähigkeiten wird jede Computer-Vision-Trainingsarchitektur etwas finden einige Merkmale von Objekten und Klassen im ImageNet-Datensatz. Einige Architekturen bieten möglicherweise mehr Funktionen als andere oder stellen nützlichere Verbindungen her als andere alle sollte mindestens die Funktionen der höchsten Ebene finden:

ImageNet-Daten mit der minimal möglichen Anzahl korrekter Identifizierungen – „High-Level“-Funktionen.
Es sind diese „hochrangigen“ Merkmale, die einen Datensatz auszeichnen und ihm seinen „Fingerabdruck“ verleihen. Sie sind die zuverlässigen „Haken“, an denen sich eine langfristige Methode für gegnerische Bildangriffe aufhängen lässt, die sich über verschiedene Systeme erstrecken und parallel zum „alten“ Datensatz wachsen kann, während dieser in neuen Forschungsarbeiten und Produkten fortgeführt wird.
Eine ausgefeiltere Architektur führt zu genaueren und detaillierteren Identifikationen, Merkmalen und Klassen:

Allerdings ist ein gegnerischer Angriffsgenerator umso mehr auf diese angewiesen senken Merkmale (z. B. „Junger kaukasischer Mann“ anstelle von „Gesicht“), desto weniger effektiv wird es in Crossover- oder späteren Architekturen sein, die verschiedene Versionen des Originaldatensatzes – beispielsweise ein Teilsatz oder ein gefilterter Satz, bei dem viele der Originalbilder aus dem vollständigen Datensatz nicht vorhanden sind:

Gegnerische Angriffe auf „genullte“, vortrainierte Modelle
Was ist mit Fällen, in denen Sie einfach ein vorab trainiertes Modell herunterladen, das ursprünglich auf einem sehr beliebten Datensatz trainiert wurde, und ihm völlig neue Daten geben?
Das Modell wurde bereits auf (zum Beispiel) ImageNet trainiert, und alles, was übrig bleibt, sind die Gewichte, deren Training möglicherweise Wochen oder Monate gedauert hat, und die nun bereit sind, Ihnen bei der Identifizierung ähnlicher Objekte wie denen zu helfen, die in den ursprünglichen (jetzt fehlenden) Daten vorhanden waren.

Wenn die ursprünglichen Daten aus der Trainingsarchitektur entfernt werden, bleibt die „Veranlagung“ des Modells übrig, Objekte auf die Art und Weise zu klassifizieren, die es ursprünglich gelernt hat. Dies führt im Wesentlichen dazu, dass sich viele der ursprünglichen „Signaturen“ neu bilden und erneut anfällig für dieselben alten Methoden des Adversarial Image Attack werden.
Diese Gewichte sind wertvoll. Ohne die Daten or Wenn Sie die Gewichte ändern, haben Sie im Wesentlichen eine leere Architektur ohne Daten. Sie müssen sie von Grund auf neu trainieren, was einen großen Zeit- und Rechenaufwand erfordert, genau wie die ursprünglichen Autoren (wahrscheinlich auf leistungsstärkerer Hardware und mit einem höheren Budget als Ihnen zur Verfügung steht).
Das Problem ist, dass die Gewichte bereits recht gut geformt und widerstandsfähig sind. Obwohl sie sich im Training etwas anpassen, verhalten sie sich bei Ihren neuen Daten ähnlich wie bei den Originaldaten und erzeugen charakteristische Merkmale, auf die sich ein feindliches Angriffssystem zurückgreifen kann.
Auch dies bewahrt langfristig die „DNA“ von Computer Vision-Datensätzen, die zwölf oder mehr Jahre alt, und hat möglicherweise eine bemerkenswerte Entwicklung von Open-Source-Bemühungen bis hin zu kommerzialisierten Bereitstellungen durchlaufen – selbst wenn die ursprünglichen Trainingsdaten zu Beginn des Projekts vollständig über Bord geworfen wurden. Einige dieser kommerziellen Einsätze werden möglicherweise erst in einigen Jahren erfolgen.
Keine Whitebox erforderlich
In Bezug auf die zweite häufige Kritik an gegnerischen Bildangriffssystemen haben die Autoren des neuen Papiers herausgefunden, dass ihre Fähigkeit, Erkennungssysteme mit manipulierten Bildern von Blumen zu täuschen, sich gut auf eine Reihe von Architekturen übertragen lässt.
Die Autoren stellen fest, dass ihre Methode „Universal NaTuralistic adversarial paTches“ (TnT) die erste ist, die erkennbare Bilder (und nicht zufälliges Störrauschen) verwendet, um Bilderkennungssysteme zu täuschen. Gleichzeitig erklären sie:
„[TnTs] sind gegen mehrere hochmoderne Klassifikatoren wirksam, die von weit verbreiteten reichen.“ WideResNet50 in der groß angelegten visuellen Erkennungsaufgabe von IMAGEnet Datensatz zu VGG-Gesichtsmodellen in der Gesichtserkennungsaufgabe von PubFig Datensatz in beiden gezielt und ungezielt Anschläge.
„TnTs können Folgendes besitzen: i) den Naturalismus, der [mit] Auslösern erreichbar ist, die in Trojaner-Angriffsmethoden verwendet werden; und ii) die Verallgemeinerung und Übertragbarkeit von gegnerische Beispiele zu anderen Netzen.
„Dies wirft Sicherheitsbedenken hinsichtlich bereits eingesetzter DNNs sowie zukünftiger DNN-Implementierungen auf, bei denen Angreifer unauffällige, natürlich aussehende Objektpatches verwenden können, um neuronale Netzwerksysteme in die Irre zu führen, ohne das Modell zu manipulieren und eine Entdeckung zu riskieren.“
Die Autoren schlagen vor, dass konventionelle Gegenmaßnahmen wie die Verschlechterung des Clean Acc. eines Netzwerks könnte theoretisch einen gewissen Schutz gegen TnT-Patches bieten, aber das „TnTs können diese SOTA-nachweisbaren Verteidigungsmethoden immer noch erfolgreich umgehen, wobei die meisten Verteidigungssysteme eine Robustheit von 0 % erreichen.“
Zu den möglichen anderen Lösungen gehören: föderiertes Lernen, bei dem die Herkunft der bereitgestellten Bilder geschützt ist, und neue Ansätze, die Daten während des Trainings direkt „verschlüsseln“ könnten, wie zum Beispiel einer kürzlich vorgeschlagen von der Nanjing University of Aeronautics and Astronautics.
Auch in diesen Fällen wäre es wichtig, ernsthaft weiterzubilden neu Bilddaten – mittlerweile sind die Bilder und die zugehörigen Anmerkungen in der kleinen Anzahl der beliebtesten Lebenslauf-Datensätze so tief in die Entwicklungszyklen auf der ganzen Welt eingebettet, dass sie eher Software als Daten ähneln; Software, die oft seit Jahren nicht mehr nennenswert aktualisiert wurde.
Fazit
Adversarial Image Attacks werden nicht nur durch Open-Source-Methoden des maschinellen Lernens ermöglicht, sondern auch durch eine Unternehmenskultur der KI-Entwicklung, die aus mehreren Gründen dazu motiviert ist, bewährte Computer-Vision-Datensätze wiederzuverwenden: Sie haben sich bereits als wirksam erwiesen; sie sind weitaus günstiger, als „bei Null anzufangen“; und sie werden von führenden Köpfen und Organisationen aus Wissenschaft und Industrie gepflegt und aktualisiert, und zwar mit einem Finanzierungs- und Personalumfang, den ein einzelnes Unternehmen nur schwer nachbilden könnte.
Darüber hinaus kommt es in vielen Fällen vor, dass die Daten nicht original sind (im Gegensatz zu CityScapes) wurden die Bilder vor den jüngsten Kontroversen über Datenschutz und Datenerfassungspraktiken gesammelt, so dass diese älteren Datensätze in gewisser Weise zurückblieben halblegales Fegefeuer Aus der Sicht eines Unternehmens mag dies beruhigend wie ein „sicherer Hafen“ aussehen.
TnT-Angriffe! Universelle naturalistische gegnerische Patches gegen tiefe neuronale Netzwerksysteme ist Co-Autor von Bao Gia Doan, Minhui Xue, Ehsan Abbasnejad, Damith C. Ranasinghe von der University of Adelaide und Shiqing Ma vom Department of Computer Science der Rutgers University.
Aktualisiert am 1. Dezember 2021, 7:06 Uhr GMT+2 – Tippfehler korrigiert.












