KI 101
Was ist Lineare Regression?
Was ist Lineare Regression?
Lineare Regression ist ein Algorithmus, der verwendet wird, um eine Beziehung zwischen zwei verschiedenen Merkmalen/Variablen vorherzusagen oder zu visualisieren. Bei linearen Regressionsaufgaben gibt es zwei Arten von Variablen, die untersucht werden: die abhängige Variable und die unabhängige Variable. Die unabhängige Variable ist die Variable, die unabhängig ist und nicht von der anderen Variable beeinflusst wird. Wenn die unabhängige Variable angepasst wird, ändern sich die Werte der abhängigen Variable. Die abhängige Variable ist die Variable, die untersucht wird, und sie ist das, was das Regressionsmodell löst oder vorherzusagen versucht. Bei linearen Regressionsaufgaben besteht jede Beobachtung/Instanz aus beiden Werten der abhängigen Variable und der unabhängigen Variable.
Das war eine kurze Erklärung der linearen Regression, aber lasst uns sicherstellen, dass wir ein besseres Verständnis der linearen Regression erlangen, indem wir ein Beispiel betrachten und die Formel untersuchen, die sie verwendet.
Verständnis der Linearen Regression
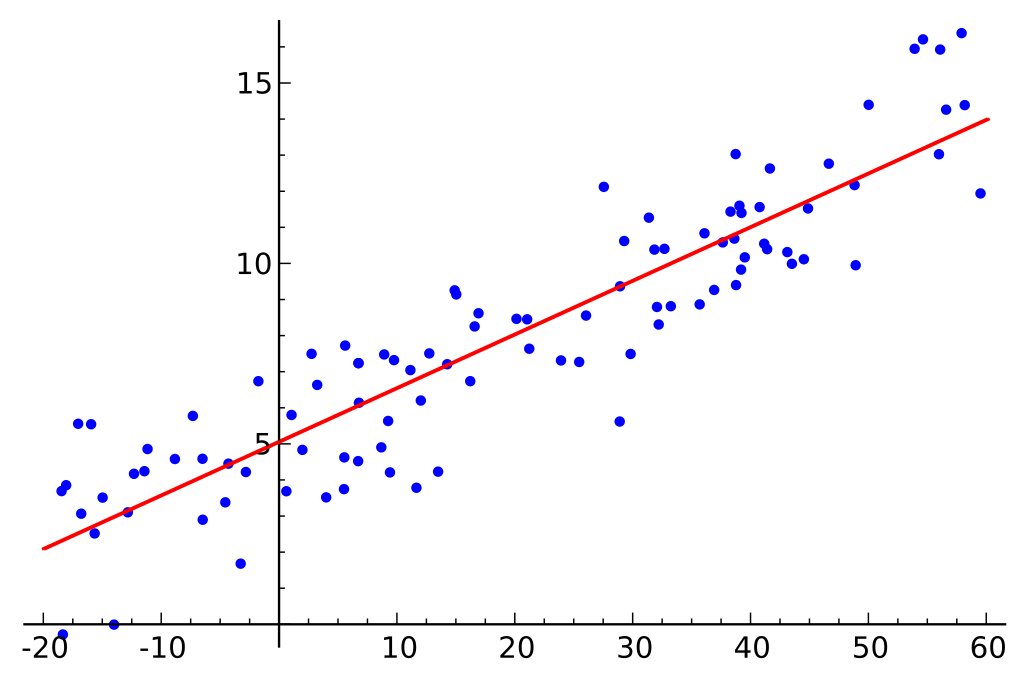
Nehmen wir an, wir haben ein Dataset, das Festplattengrößen und die Kosten dieser Festplatten abdeckt.
Lasst uns annehmen, dass unser Dataset aus zwei verschiedenen Merkmalen besteht: der Menge an Speicher und den Kosten. Je mehr Speicher wir für einen Computer kaufen, desto höher sind die Kosten des Kaufs. Wenn wir die einzelnen Datenpunkte in einem Streudiagramm plotten, könnten wir ein Diagramm erhalten, das ungefähr so aussieht:

Das genaue Verhältnis zwischen Speicher und Kosten kann je nach Hersteller und Modell der Festplatte variieren, aber im Allgemeinen ist der Trend der Daten ein solcher, der im unteren linken Bereich beginnt (wo Festplatten sowohl billiger als auch kleiner sind) und sich zum oberen rechten Bereich bewegt (wo die Platten teurer und größer sind).
Wenn wir die Menge an Speicher auf der X-Achse und die Kosten auf der Y-Achse hätten, würde eine Linie, die die Beziehung zwischen den X- und Y-Variablen beschreibt, im unteren linken Bereich beginnen und sich zum oberen rechten Bereich bewegen.

Die Funktion eines Regressionsmodells ist es, eine lineare Funktion zwischen den X- und Y-Variablen zu bestimmen, die die Beziehung zwischen den beiden Variablen am besten beschreibt. Bei der linearen Regression wird angenommen, dass Y aus einer Kombination der Eingangsvariablen berechnet werden kann. Die Beziehung zwischen den Eingangsvariablen (X) und den Zielvariablen (Y) kann durch Zeichnen einer Linie durch die Punkte im Diagramm dargestellt werden. Die Linie repräsentiert die Funktion, die die Beziehung zwischen X und Y am besten beschreibt (z.B. für jeden Anstieg von X um 3 erhöht sich Y um 2). Das Ziel ist es, eine optimale “Regressionslinie” oder die Linie/Funktion zu finden, die die Daten am besten beschreibt.
Linien werden normalerweise durch die Gleichung dargestellt: Y = m*X + b. X bezieht sich auf die unabhängige Variable, während Y die abhängige Variable ist. Der Wert m ist die Steigung der Linie, definiert als “Anstieg” über “Lauf”. Machine-Learning-Praktiker stellen die berühmte Steigungs-Linie-Gleichung ein wenig anders dar, indem sie stattdessen die folgende Gleichung verwenden:
y(x) = w0 + w1 * x
In der obigen Gleichung ist y die Zielvariable, während “w” die Parameter des Modells sind und der Eingabe “x” entspricht. Die Gleichung wird also wie folgt gelesen: “Die Funktion, die Y in Abhängigkeit von X angibt, ist gleich den Parametern des Modells multipliziert mit den Merkmalen”. Die Parameter des Modells werden während des Trainings angepasst, um die beste Regressionslinie zu erhalten.
Mehrfache Lineare Regression

Foto: Cbaf via Wikimedia Commons, Public Domain (https://commons.wikimedia.org/wiki/File:2d_multiple_linear_regression.gif)
Der oben beschriebene Prozess gilt für die einfache lineare Regression oder die Regression auf Datensätzen, bei denen es nur eine einzelne Variable/unabhängige Variable gibt. Es kann jedoch auch eine Regression mit mehreren Variablen durchgeführt werden. Im Falle der “mehrfachen linearen Regression” wird die Gleichung um die Anzahl der Variablen im Datensatz erweitert. Mit anderen Worten: Während die Gleichung für die einfache lineare Regression y(x) = w0 + w1 * x lautet, wäre die Gleichung für die multiple lineare Regression y(x) = w0 + w1x1 plus die Gewichte und Eingaben für die verschiedenen Merkmale. Wenn wir die Gesamtzahl der Gewichte und Merkmale als w(n)x(n) darstellen, könnten wir die Formel wie folgt darstellen:
y(x) = w0 + w1x1 + w2x2 + … + w(n)x(n)
Nachdem wir die Formel für die lineare Regression festgelegt haben, verwendet das Machine-Learning-Modell unterschiedliche Werte für die Gewichte und zeichnet verschiedene Anpassungslinien. Denken Sie daran, dass das Ziel darin besteht, die Linie zu finden, die die Daten am besten beschreibt, um zu bestimmen, welche der möglichen Gewichtskombinationen (und somit welche mögliche Linie) die Daten am besten beschreibt und die Beziehung zwischen den Variablen erklärt.
Eine Kostenfunktion wird verwendet, um zu messen, wie nah die angenommenen Y-Werte den tatsächlichen Y-Werten sind, wenn ein bestimmter Gewichtswert gegeben ist. Die Kostenfunktion für die lineare Regression ist der mittlere quadratische Fehler, der einfach den mittleren (quadratischen) Fehler zwischen dem vorhergesagten Wert und dem tatsächlichen Wert für alle Datenpunkte im Datensatz ermittelt. Die Kostenfunktion wird verwendet, um eine Kosten zu berechnen, die die Differenz zwischen dem vorhergesagten Zielwert und dem tatsächlichen Zielwert erfasst. Wenn die Anpassungslinie weit von den Datenpunkten entfernt ist, ist die Kosten höher, während die Kosten kleiner werden, je näher die Linie die tatsächlichen Beziehungen zwischen den Variablen beschreibt. Die Gewichte des Modells werden dann angepasst, bis die Gewichtskonfiguration gefunden wird, die den kleinsten Fehler produziert.








