KI 101
Was ist ein Entscheidungsbaum?
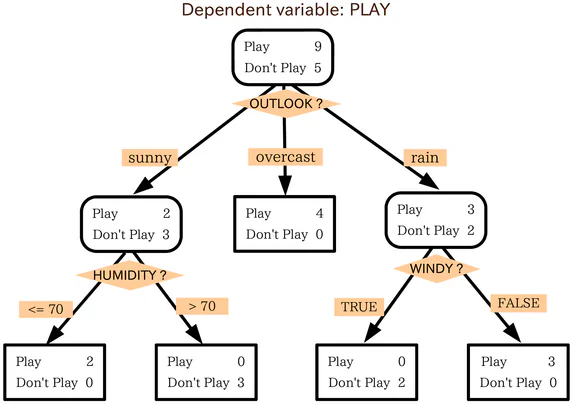
Was ist ein Entscheidungsbaum?
Ein Entscheidungsbaum ist ein nützliches Machine-Learning-Algorithmus, der für Regression- und Klassifizierungsaufgaben verwendet wird. Der Name “Entscheidungsbaum” kommt von der Tatsache, dass der Algorithmus das Dataset in immer kleinere Teile aufteilt, bis die Daten in einzelne Instanzen unterteilt sind, die dann klassifiziert werden. Wenn man die Ergebnisse des Algorithmus visualisieren würde, würde die Art und Weise, wie die Kategorien unterteilt werden, einem Baum mit vielen Blättern ähneln.
Das ist eine kurze Definition eines Entscheidungsbaums, aber lassen Sie uns einen tiefen Einblick in die Funktionsweise von Entscheidungsbäumen nehmen. Ein besseres Verständnis davon, wie Entscheidungsbäume funktionieren, sowie ihre Anwendungsfälle, wird Ihnen helfen, zu wissen, wann Sie sie in Ihren Machine-Learning-Projekten verwenden sollten.
Format eines Entscheidungsbaums
Ein Entscheidungsbaum ist ähnlich wie ein Flussdiagramm. Um ein Flussdiagramm zu verwenden, beginnt man am Startpunkt oder an der Wurzel des Diagramms und bewegt sich dann basierend auf den Filterkriterien des Startknotens zu einem der nächsten möglichen Knoten. Dieser Prozess wird wiederholt, bis ein Ende erreicht ist.
Entscheidungsbäume funktionieren im Wesentlichen auf die gleiche Weise, wobei jeder interne Knoten im Baum eine Art Test- oder Filterkriterium darstellt. Die Knoten außen, die Endpunkte des Baums, sind die Labels für den Datenpunkt in Frage und werden als “Blätter” bezeichnet. Die Zweige, die von den internen Knoten zu den nächsten Knoten führen, sind Merkmale oder Kombinationen von Merkmalen. Die Regeln, die zur Klassifizierung der Datenpunkte verwendet werden, sind die Pfade, die von der Wurzel zu den Blättern führen.

Algorithmen für Entscheidungsbäume
Entscheidungsbäume funktionieren auf einem algorithmischen Ansatz, der das Dataset in einzelne Datenpunkte aufteilt, basierend auf verschiedenen Kriterien. Diese Aufteilungen werden mit verschiedenen Variablen oder Merkmalen des Datasets durchgeführt. Zum Beispiel, wenn das Ziel darin besteht, zu bestimmen, ob ein Hund oder eine Katze durch die Eingabemerkmale beschrieben wird, können die Variablen, auf denen die Daten aufgeteilt werden, Dinge wie “Krallen” und “Bellen” sein.
Was sind also die Algorithmen, die tatsächlich verwendet werden, um die Daten in Zweige und Blätter aufzuteilen? Es gibt verschiedene Methoden, die verwendet werden können, um einen Baum aufzuteilen, aber die häufigste Methode der Aufteilung ist wahrscheinlich eine Technik, die als “rekursive binäre Aufteilung” bezeichnet wird. Wenn diese Methode der Aufteilung durchgeführt wird, beginnt der Prozess an der Wurzel und die Anzahl der Merkmale im Dataset stellt die mögliche Anzahl der möglichen Aufteilungen dar. Eine Funktion wird verwendet, um zu bestimmen, wie viel Genauigkeit jede mögliche Aufteilung kostet, und die Aufteilung wird durchgeführt, basierend auf den Kriterien, die die geringste Genauigkeit opfern. Dieser Prozess wird rekursiv durchgeführt und Untergruppen werden mit der gleichen allgemeinen Strategie gebildet.
Um die Kosten der Aufteilung zu bestimmen, wird eine Kostenfunktion verwendet. Eine andere Kostenfunktion wird für Regressions- und Klassifizierungsaufgaben verwendet. Das Ziel beider Kostenfunktionen ist es, zu bestimmen, welche Zweige die meisten ähnlichen Antwortwerte oder die homogensten Zweige haben. Betrachten Sie, dass Sie Testdaten einer bestimmten Klasse haben möchten, die bestimmte Pfade befolgen, und dies macht intuitiv Sinn.
In Bezug auf die Regressionskostenfunktion für die rekursive binäre Aufteilung wird der Algorithmus wie folgt verwendet, um die Kosten zu berechnen:
sum(y – Vorhersage)^2
Die Vorhersage für eine bestimmte Gruppe von Datenpunkten ist der Mittelwert der Antworten der Trainingsdaten für diese Gruppe. Alle Datenpunkte werden durch die Kostenfunktion geführt, um die Kosten für alle möglichen Aufteilungen zu bestimmen, und die Aufteilung mit den geringsten Kosten wird ausgewählt.
In Bezug auf die Kostenfunktion für die Klassifizierung ist die Funktion wie folgt:
G = sum(pk * (1 – pk))
Dies ist der Gini-Score, und es ist ein Maß für die Effektivität einer Aufteilung, basierend auf der Anzahl der Instanzen verschiedener Klassen in den Gruppen, die durch die Aufteilung entstehen. Mit anderen Worten, es quantifiziert, wie gemischt die Gruppen nach der Aufteilung sind. Eine optimale Aufteilung ist, wenn alle Gruppen, die durch die Aufteilung entstehen, nur aus Eingaben einer Klasse bestehen. Wenn eine optimale Aufteilung erstellt wurde, wird der “pk”-Wert entweder 0 oder 1 sein und G wird gleich 0 sein. Sie können vielleicht erraten, dass die schlechteste Aufteilung eine ist, bei der es eine 50-50-Vertretung der Klassen in der Aufteilung gibt, im Falle der binären Klassifizierung. In diesem Fall wäre der “pk”-Wert 0,5 und G würde auch 0,5 sein.
Der Aufteilungsprozess wird beendet, wenn alle Datenpunkte in Blätter umgewandelt und klassifiziert wurden. Es kann jedoch sein, dass Sie das Wachstum des Baums frühzeitig stoppen möchten. Große komplexe Bäume neigen zu Überanpassung, aber es gibt mehrere Methoden, um dies zu bekämpfen. Eine Methode, um Überanpassung zu reduzieren, besteht darin, eine Mindestanzahl von Datenpunkten zu spezifizieren, die zum Erstellen eines Blatts verwendet werden. Eine andere Methode, um die Überanpassung zu kontrollieren, besteht darin, den Baum auf eine bestimmte maximale Tiefe zu beschränken, was bestimmt, wie lang ein Pfad von der Wurzel zu einem Blatt sein kann.
Ein weiterer Prozess, der bei der Erstellung von Entscheidungsbäumen involviert ist, ist das Beschneiden. Das Beschneiden kann dazu beitragen, die Leistung eines Entscheidungsbaums zu verbessern, indem es Zweige entfernt, die Merkmale enthalten, die wenig Vorhersagekraft oder wenig Bedeutung für das Modell haben. Auf diese Weise wird die Komplexität des Baums reduziert, es wird weniger wahrscheinlich, dass er überanpasst, und die Vorhersageleistung des Modells wird verbessert.
Wenn das Beschneiden durchgeführt wird, kann der Prozess am Anfang oder am Ende des Baums beginnen. Die einfachste Methode des Beschneidens ist jedoch, mit den Blättern zu beginnen und versuchen, den Knoten zu entfernen, der die häufigste Klasse in diesem Blatt enthält. Wenn die Genauigkeit des Modells nicht verschlechtert wird, wenn dies getan wird, wird die Änderung beibehalten. Es gibt andere Techniken, die zum Beschneiden verwendet werden, aber die oben beschriebene Methode – das Beschneiden mit reduziertem Fehler – ist wahrscheinlich die häufigste Methode des Beschneidens von Entscheidungsbäumen.
Überlegungen für die Verwendung von Entscheidungsbäumen
Entscheidungsbäume sind oft nützlich, wenn Klassifizierung durchgeführt werden muss, aber die Rechenzeit ein wichtiger Einschränkungsfaktor ist. Entscheidungsbäume können klar machen, welche Merkmale in den ausgewählten Datasets die meisten Vorhersagekraft haben. Darüber hinaus können Entscheidungsbäume im Gegensatz zu vielen Machine-Learning-Algorithmen, bei denen die Regeln, die zur Klassifizierung der Daten verwendet werden, schwer zu interpretieren sein können, interpretierbare Regeln liefern. Entscheidungsbäume können auch sowohl kategorische als auch kontinuierliche Variablen verwenden, was bedeutet, dass weniger Vorverarbeitung erforderlich ist, im Vergleich zu Algorithmen, die nur eine dieser Variablentypen verarbeiten können.
Entscheidungsbäume neigen dazu, nicht sehr gut zu funktionieren, wenn sie verwendet werden, um die Werte von kontinuierlichen Attributen zu bestimmen. Eine weitere Einschränkung von Entscheidungsbäumen ist, dass sie, wenn sie zur Klassifizierung verwendet werden, bei wenigen Trainingsbeispielen, aber vielen Klassen, ungenau sind.








