KI 101
Was sind CNNs (Convolutional Neural Networks)?
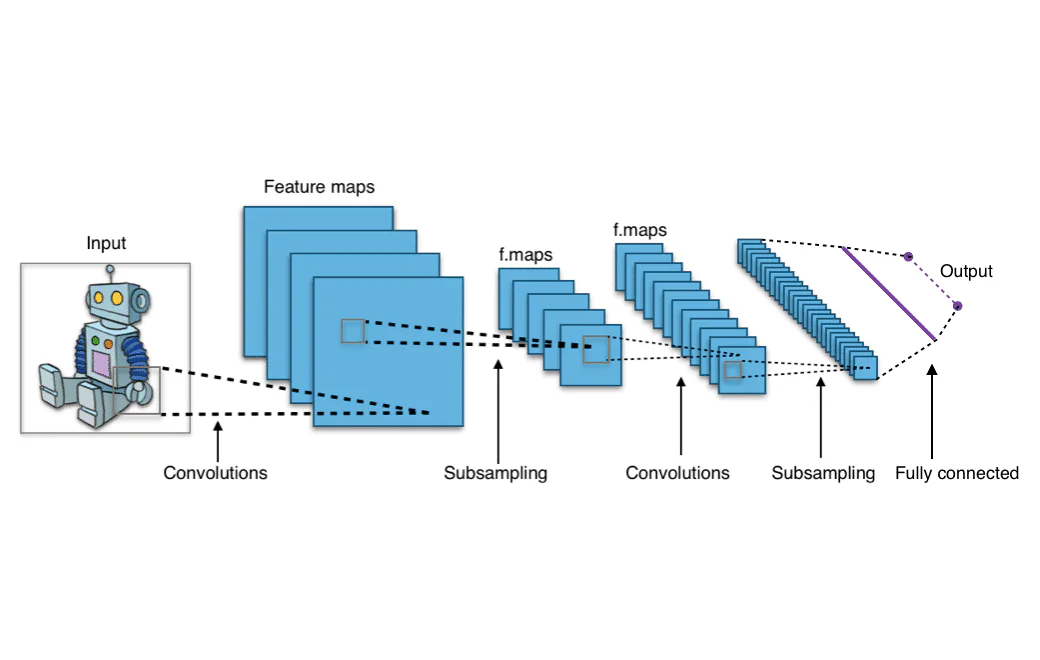
Vielleicht haben Sie sich schon einmal gefragt, wie Facebook oder Instagram Gesichter in einem Bild automatisch erkennen kann, oder wie Google es Ihnen ermöglicht, im Web nach ähnlichen Fotos zu suchen, indem Sie einfach ein Foto von sich selbst hochladen. Diese Funktionen sind Beispiele für Computer-Vision und werden von Convolutional Neural Networks (CNNs) angetrieben. Doch was genau sind Convolutional Neural Networks? Lassen Sie uns einen tiefen Einblick in die Architektur eines CNNs nehmen und verstehen, wie sie funktionieren.
Was sind Neuronale Netze?
Bevor wir über Convolutional Neural Networks sprechen, sollten wir uns zunächst mit den regulären neuronalen Netzen auseinandersetzen. Es gibt einen anderen Artikel zum Thema Neuronale Netze, also werden wir hier nicht zu tief darauf eingehen. Um sie jedoch kurz zu definieren: Sie sind computergestützte Modelle, die von dem menschlichen Gehirn inspiriert sind. Ein neuronales Netzwerk funktioniert, indem es Daten aufnimmt und diese Daten durch Anpassen von “Gewichten” manipuliert, die Annahmen über die Beziehungen zwischen den Eingabefeatures und der Objektklasse sind. Wenn das Netzwerk trainiert wird, werden die Werte der Gewichte angepasst und sie sollten hoffentlich auf Gewichte konvergieren, die die Beziehungen zwischen den Features genau erfassen.
Dies ist, wie ein feed-forward neuronales Netzwerk funktioniert, und CNNs bestehen aus zwei Hälften: einem feed-forward neuronalen Netzwerk und einer Gruppe von Convolutional-Schichten.
Was sind Convolutionale Neuronale Netze (CNNs)?
Was sind die “Konvolutionen”, die in einem Convolutional Neural Network auftreten? Eine Konvolution ist eine mathematische Operation, die eine Menge von Gewichten erstellt, die im Wesentlichen eine Darstellung von Teilen des Bildes ist. Diese Menge von Gewichten wird als Kernel oder Filter bezeichnet. Der Filter, der erstellt wird, ist kleiner als das gesamte Eingabebild und deckt nur einen Teil des Bildes ab. Die Werte im Filter werden mit den Werten im Bild multipliziert. Der Filter wird dann verschoben, um eine Darstellung eines neuen Teils des Bildes zu erstellen, und der Prozess wird wiederholt, bis das gesamte Bild abgedeckt ist.
Eine andere Möglichkeit, darüber nachzudenken, ist, sich eine Ziegelwand vorzustellen, bei der die Ziegel die Pixel im Eingabebild darstellen. Ein “Fenster” wird über die Wand geschoben, das der Filter ist. Die Ziegel, die durch das Fenster sichtbar sind, sind die Pixel, deren Werte mit den Werten im Filter multipliziert werden. Aus diesem Grund wird diese Methode der Erstellung von Gewichten mit einem Filter oft als “Sliding-Windows”-Technik bezeichnet.
Die Ausgabe aus den Filtern, die über das gesamte Eingabebild bewegt werden, ist ein zweidimensionales Array, das das gesamte Bild darstellt. Dieses Array wird als “Feature-Map” bezeichnet.
Warum Konvolutionen unerlässlich sind
Was ist der Zweck der Erstellung von Konvolutionen? Konvolutionen sind notwendig, weil ein neuronales Netzwerk in der Lage sein muss, die Pixel in einem Bild als numerische Werte zu interpretieren. Die Funktion der Convolutional-Schichten ist es, das Bild in numerische Werte umzuwandeln, die das neuronale Netzwerk interpretieren und dann relevante Muster daraus extrahieren kann. Die Aufgabe der Filter im Convolutional-Netzwerk ist es, ein zweidimensionales Array von Werten zu erstellen, das an die späteren Schichten des neuronalen Netzwerks übergeben werden kann, die die Muster im Bild lernen werden.
Filter und Kanäle
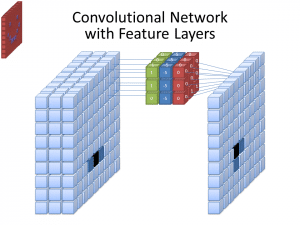
Photo: cecebur via Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)
CNNs verwenden nicht nur einen Filter, um Muster aus den Eingabebildern zu lernen. Es werden mehrere Filter verwendet, da die verschiedenen Arrays, die von den verschiedenen Filtern erstellt werden, zu einer komplexeren, reicheren Darstellung des Eingabebildes führen. Übliche Zahlen von Filtern für CNNs sind 32, 64, 128 und 512. Je mehr Filter es gibt, desto mehr Gelegenheiten hat das CNN, die Eingabedaten zu untersuchen und daraus zu lernen.
Ein CNN analysiert die Unterschiede in den Pixelwerten, um die Ränder von Objekten zu bestimmen. In einem Graustufenbild würde das CNN nur die Unterschiede in Schwarz und Weiß, Hell und Dunkel berücksichtigen. Wenn die Bilder Farbbilder sind, muss das CNN nicht nur Hell und Dunkel berücksichtigen, sondern auch die drei verschiedenen Farbkanäle – Rot, Grün und Blau. In diesem Fall besitzen die Filter 3 Kanäle, genau wie das Bild selbst. Die Anzahl der Kanäle, die ein Filter hat, wird als seine Tiefe bezeichnet, und die Anzahl der Kanäle im Filter muss der Anzahl der Kanäle im Bild entsprechen.
Convolutionales Neuronales Netzwerk (CNN) Architektur
Lassen Sie uns einen Blick auf die vollständige Architektur eines Convolutional Neural Networks werfen. Eine Convolutional-Schicht befindet sich am Anfang jedes Convolutional-Netzwerks, da sie notwendig ist, um die Bildaten in numerische Arrays umzuwandeln. Convolutional-Schichten können jedoch auch nach anderen Convolutional-Schichten kommen, was bedeutet, dass diese Schichten aufeinander gestapelt werden können. Mehrere Convolutional-Schichten bedeuten, dass die Ausgaben aus einer Schicht weitere Konvolutionen unterzogen werden können und in relevante Muster zusammengefasst werden. Praktisch bedeutet dies, dass das Netzwerk, wenn die Bildaten durch die Convolutional-Schichten verlaufen, beginnt, “komplexere Features” des Bildes zu “erkennen”.
Die frühen Schichten eines ConvNets sind für die Extraktion von low-level-Features verantwortlich, wie den Pixeln, die einfache Linien bilden. Spätere Schichten des ConvNets werden diese Linien zu Formen zusammenfügen. Dieser Prozess der Veränderung von oberflächlicher Analyse zu tiefer Analyse wird fortgesetzt, bis das ConvNet komplexe Formen wie Tiere, Gesichter und Autos erkennt.
Nachdem die Daten durch alle Convolutional-Schichten verlaufen sind, gelangen sie in den dicht verbundenen Teil des CNN. Die dicht verbundenen Schichten sind das, was ein traditionelles feed-forward neuronales Netzwerk ähnelt, eine Reihe von Knoten, die in Schichten angeordnet sind und miteinander verbunden sind. Die Daten verlaufen durch diese dicht verbundenen Schichten, die die Muster lernen, die von den Convolutional-Schichten extrahiert wurden, und indem sie dies tun, wird das Netzwerk in der Lage, Objekte zu erkennen.










