人工智能
使用引语来验证 NLG 内容的危险

观点 自然语言生成(NLG)模型,如 GPT-3,容易“编造”出它们在事实信息中呈现的内容。在一个非常关注基于文本的虚假新闻增长的时代,这些“讨好”的幻想代表了自动写作和摘要系统的发展以及 AI 驱动的新闻业等自然语言处理(NLP)各个子领域的未来的一大障碍。
主要问题是,GPT 风格的语言模型从非常大的训练文本语料库中推导出关键特征和类别,并学会以巧妙和真实的方式使用这些特征作为语言的构建块,无论生成内容的准确性或可接受性如何。
NLG 系统因此目前依赖于人类对事实的验证,采用两种方法之一:模型要么被用作种子文本生成器,立即传递给人类用户,用于验证或其他形式的编辑或改编;要么人类被用作昂贵的过滤器来提高用于告知抽象和“创造性”模型的数据集的质量(这些模型本身在事实准确性方面仍然很难被信任,并且需要进一步的人类监督)。
旧闻和虚假事实
自然语言生成(NLG)模型能够产生令人信服和合理的输出,因为它们已经学会了语义架构,而不是更抽象地吸收实际的历史、科学、经济或其他主题,这些主题有效地作为“乘客”嵌入源数据中。
NLG 模型生成的信息的事实准确性假设训练它们的输入本身是可靠和最新的,这在预处理和进一步的人类验证方面带来了巨大的负担,这是一个昂贵的绊脚石,NLP 研究部门目前正在从多个方面解决。
GPT-3 级别的系统需要大量时间和金钱来训练,一旦训练完成,很难在“内核级”上更新。虽然会话和用户本地修改可以增加实施模型的实用性和准确性,但这些有用的好处很难传回核心模型,通常需要完全或部分重新训练。
因此,很难创建可以利用最新信息的训练语言模型。

在 COVID-19 出现之前训练的 text-davinci-002 – GPT-3 的迭代,被其创造者 OpenAI 认为是“最有能力”的 – 每个请求可以处理 4000 个标记,但不知道 COVID-19 或 2022 年乌克兰入侵(这些提示和响应来自 2022 年 4 月 5 日)。有趣的是,’未知’ 在两个失败案例中都是一个可接受的答案,但进一步的提示很容易确定 GPT-3 对这些事件一无所知。来源:https://beta.openai.com/playground
训练好的模型只能访问它在训练时内化的“真理”,而且很难通过默认的 GPT-3 模型获得准确和相关的引语,因为它有时会产生正确的引语,从而导致对其能力的虚假信心。

上面,2021 年 davinci-instruct-text GPT-3 获得的三个准确引语。中间,GPT-3 未能引用爱因斯坦最著名的引语之一(“上帝不与宇宙玩骰子”),尽管提示不含糊。下面,GPT-3 将一个丑闻和虚构的引语归因于阿尔伯特·爱因斯坦,显然是从同一会话中关于温斯顿·丘吉尔的早期问题中溢出。来源:作者 2021 年在 https://www.width.ai/post/business-applications-for-gpt-3 的文章
GopherCite
为了解决 NLG 模型的一般缺陷,谷歌的 DeepMind 最近提出了 GopherCite,一个 280 亿参数的模型,能够在其生成的响应中引用特定和准确的证据。



GopherCite 支持其主张的三个例子,使用真实引语。 来源:https://arxiv.org/pdf/2203.11147.pdf
GopherCite 利用来自人类偏好的强化学习(RLHP)来训练能够引用真实引语作为支持证据的查询模型。这些引语是从搜索引擎或用户提供的特定文档中获取的多个文档来源中实时提取的。
GopherCite 的性能是通过对模型响应的人类评估来衡量的,发现其在 Google 的 NaturalQuestions 数据集上 80% 的时间具有“高质量”,在 ELI5 数据集上 67% 的时间具有“高质量”。
引用虚假信息
然而,当在牛津大学的 TruthfulQA 基准测试中测试 GopherCite 时,其响应很少被评为真实的,与人类策划的“正确”答案相比。
作者认为这是因为“支持答案”的概念在定义真理方面没有客观的帮助,因为来源引语的有用性可能会因作者本身“编造”(即写关于虚构世界、制作广告内容或以其他方式虚构不真实的材料)等因素而受到损害。



GopherCite 示例,表明合理性不一定等同于“真理”。
有效地,需要区分“支持”和“真理”这两个概念。人类文化在使用定义真理的方法和框架方面远远领先于机器学习,即使在那里,“重要”的真理似乎也处于争议和边缘否认的状态。
问题是递归的,出现在试图设计明确的“佐证”机制的 NLG 架构中:人类主导的共识被用作真理的基准,通过外包、AMT 风格的模型来实现,其中人类评估者(和那些调解他们之间纠纷的人类)本身是偏见和有偏见的。
例如,最初的 GopherCite 实验使用“超级评估者”模型来选择最好的人类主题来评估模型的输出,仅选择那些在质量保证集与之比较时至少得分 85% 的评估者。最后,选择了 113 名超级评估者来完成这项任务。
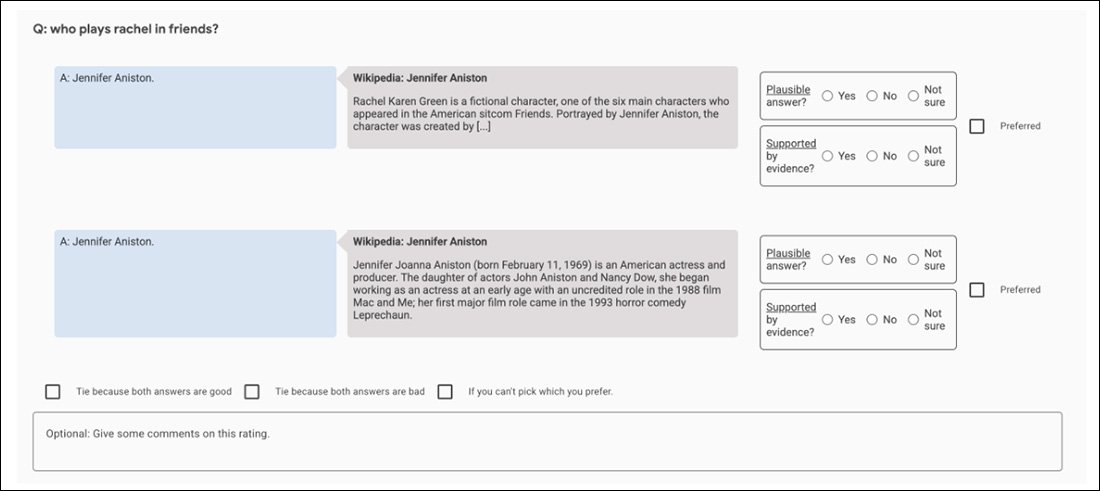
用于帮助评估 GopherCite 输出的比较应用程序的屏幕截图。
可以说,这是一个完美的不可战胜的分形追求的例子:用于评估评估者的质量保证集本身就是另一个“人类定义”的真理指标,就像用于评估 GopherCite 的牛津 TruthfulQA 集一样。
在支持和“验证”的内容方面,NLG 系统只能从训练数据中合成人类的差异和多样性,这本身就是一个不正确且未解决的问题。我们有引用的倾向,支持我们的观点,并以信心和权威说话,即使我们的来源信息可能过时、完全不准确或以其他方式故意歪曲;并且有直接将这些观点传播到野外的倾向,以前所未有的规模和效率,直接进入为新的 NLG 框架提供信息的知识采集框架的路径中。
因此,开发支持引用 NLG 系统的危险似乎与来源材料的不可预测性有关。任何增加用户对 NLG 输出信心的机制(例如直接引用和引语)在当前的技术水平下,增加了输出的真实性,但不是其真实性的危险性。
这些技术可能在 NLP 最终重现奥威尔的《1984》中虚构的“万花筒”时是有用的;但它们代表了对客观文档分析、AI 驱动的新闻业和机器摘要及自发或引导式文本生成的其他可能的“非虚构”应用的危险追求。
首次发布于 2022 年 4 月 5 日。更新于 2022 年 4 月 5 日 15:29 EET 修正术语。












