人工智能
MIT:使用机器学习在主要新闻媒体中测量媒体偏见

麻省理工学院(MIT)的研究人员使用机器学习技术来识别大约100家最大的和最有影响力的新闻媒体中的偏见性措辞,包括83家最有影响力的印刷新闻出版物。这项研究表明了自动系统的潜力,这些系统可以自动分类出版物的政治性质,并让读者更深入地了解媒体在他们关心的主题上的道德立场。
这项工作集中在如何处理特定话题的措辞,例如 无证移民 | 非法移民,胎儿 | 未出生的婴儿,示威者 | 无政府主义者。
该项目使用自然语言处理(NLP)技术来提取和分类此类“带电”语言(假设看似更“中立”的术语也代表一种政治立场),并将其映射到一个广泛的图谱中,揭示了100多家新闻媒体中超过300万篇文章的左倾和右倾偏见,形成了一个可导航的 偏见地图。
这篇论文来自麻省理工学院物理系的萨曼莎·达隆佐(Samantha D’Alonzo)和马克斯·特格马克(Max Tegmark),他们观察到,最近围绕“事实核查”的一些举措,在众多“假新闻”丑闻之后,可以被视为 不真诚,并服务于特定利益的目的。该项目旨在提供一种更基于数据的方法来研究偏见性语言和“影响”语言在所谓中立新闻背景下的使用。

研究中得出的左到右的短语谱系。 来源:https://arxiv.org/pdf/2109.00024.pdf
NLP处理
该研究的源数据来自开源 Newspaper3K数据库,包括100家媒体新闻来源的3,078,624篇文章,包括83家报纸。报纸的选择基于其影响力,而在线媒体来源还包括军事新闻分析网站 Defense One 和 Science 的文章。

研究中使用的来源。
论文报告称,下载的文本经过“最小”的预处理。直接引语被删除,因为该研究关注的是记者选择的语言(尽管引语选择本身就是一个 有趣的研究领域)。
将英国拼写改为美国拼写以标准化数据库,删除所有标点符号,删除除序数以外的所有数字。将初始句子大写转换为小写,但保留所有其他大写。
找到了最常见的100,000个短语,并对其进行了排名、清除和合并,形成了一个短语列表。所有可以识别的冗余语言(例如“分享此文章”和“文章转载”)也被删除。标准化了基本相同的短语变体(例如“大科技”和“Big Tech”,“网络安全”和“cyber security”)。
‘Nutpicking’
初始测试针对“黑人的生命很重要”(Black lives matter)话题,能够辨别出短语偏见和同义词在数据中的分布。
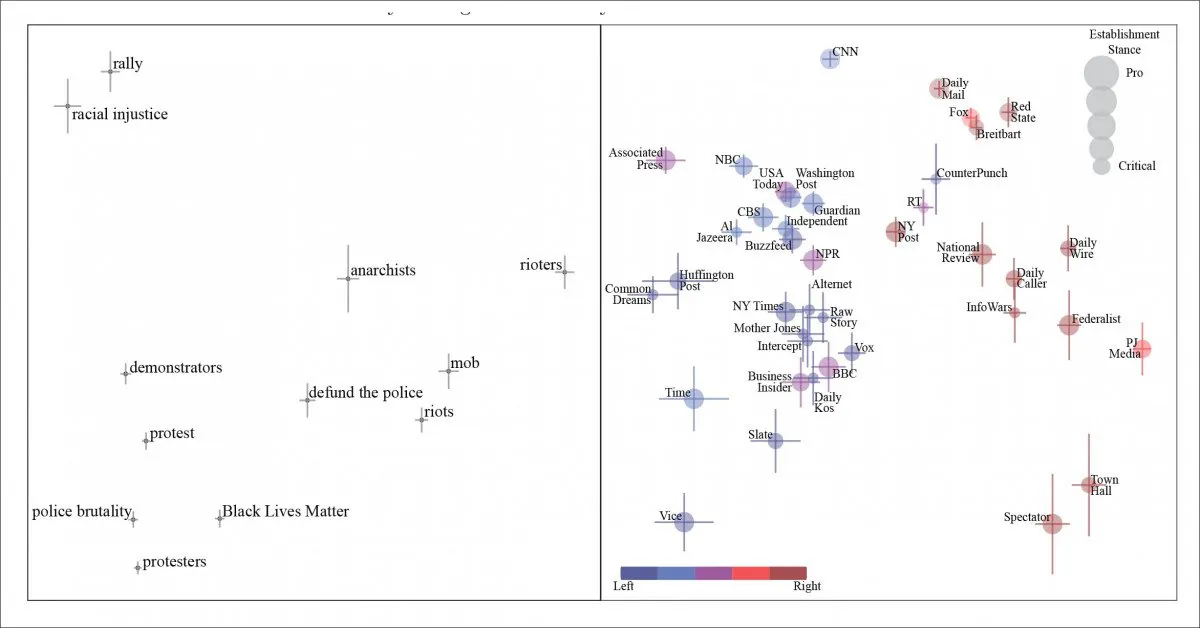
关于黑人的生命很重要(BLM)的文章的普遍主成分。我们看到人们参与民间行动的特征,从左到右,分别被描述为示威者、无政府主义者和最右端的“暴徒”。右侧面板显示了产生这些短语的报纸。
当“抗议者”从“无政府主义者”转变为“暴徒”时,我们沿着媒体的政治立场移动,论文指出,NLP提取和分析立场受到“nutpicking”实践的阻碍——媒体引用一个被不同政治派别视为有效的短语,并依赖其读者将其视为负面。论文引用“解除警察武装”作为例子。
这种情况意味着一个“左倾”短语出现在右翼语境中,代表着对依赖编码短语作为政治立场指标的NLP系统的一个特殊挑战。
此类短语是“双值”的,而某些其他短语具有普遍的负面含义(例如“杀婴”),在各种媒体中始终被视为负面。
研究还揭示了类似的映射,涉及诸如堕胎、科技审查、美国移民和枪支管制等“热点”话题。
业余爱好马
有一些媒体的政治偏见并不能以这种方式可预测地划分,例如军事支出话题。论文发现,“左倾”的CNN在这个问题上与右倾的国家评论和福克斯新闻并列。
一般来说,政治立场可以通过其他短语来确定,例如更喜欢“军事工业复合体”而不是更右倾的“防御工业”。结果显示,前者被批评性媒体如 Canary 和 美国保守派 使用,而后者更常被福克斯和CNN使用。
研究建立了从批判性到支持性语言的几个进展,包括从“枪杀”到更被动的“杀戮”;从“囚犯罪犯”到“被监禁的人”;从“石油生产者”到“大石油”。

具有机构偏见的同义词,从上到下。
研究承认,媒体可能会偏离其基本的政治立场,无论是从语言上还是出于其他动机。例如,英国著名的右翼出版物 观察家 经常刊登左翼观点的文章,这可能是出于公正报道的愿望,或者是为了激发其核心读者的兴趣。
这些特定的“业余爱好马”和单个新闻机构中“刺耳”观点的模糊使用,会使研究最终提供的左-右映射有些混乱,但仍提供了对政治归属的广泛指示。

被抑制的意义
尽管这篇论文日期为9月2日,并于2021年8月底发表,但它相对较少引起关注。部分原因可能是针对主流媒体的批评性研究不太可能被媒体热情地接受;但也可能是由于作者不愿意制作清晰、明确的图表来展示有影响力和权威的媒体在各个问题上的立场,以及总结出版物倾向于左或右的聚合值。
事实上,作者似乎在淡化结果的潜在煽动性影响。
同样,项目发布的 数据 显示了词语的频率计数,但似乎是匿名的,使得很难对所研究的媒体偏见有一个清晰的认识。没有以某种方式运用该项目,只有论文中呈现的选定示例。
以后的类似研究可能会更有用,如果它们不仅考虑话题的措辞,还考虑话题是否被报道,因为 沉默也很有意义,它本身具有明显的政治特征,往往超出了新闻选择的预算限制或其他实际因素。
尽管如此,MIT的研究似乎是迄今为止最大的此类研究,并可能为未来分类系统提供框架,甚至包括可能提醒普通读者当前阅读的出版物的政治色彩的浏览器插件。
信息泡沫、偏见和反弹
此外,还需要考虑这样的系统是否会加剧算法推荐系统最具争议的方面之一——将观众引入一个他们永远不会看到相反或具有挑战性的观点的环境中,这可能会进一步巩固读者的核心立场。
无论这样的 内容泡沫 是“安全环境”、“智力成长的障碍”还是对部分宣传的保护,是一个价值判断——一个从机器学习系统的机械、统计立场上难以解决的哲学问题。
此外,短语的政治价值的分类最终也是一种价值判断,这种判断很难抵御语言重新编码有毒或有争议的内容为新短语的能力,这些短语不在手册中,不在论坛规则中,也不在训练数据库中。
如果这种编码被嵌入到流行的在线系统中,很可能会发展成人工智能识别偏见和出版商以不断演变的方式表达其立场的冷战,人工智能始终难以跟上语言的语义。
14/09/21 – 1.41 GMT+2 – 将“100家报纸”改为“100家新闻媒体”
4:58pm – 更正论文引用以包括萨曼莎·达隆佐,并进行相关更正。












