人工智能
直接偏好优化:一个完整的指南

将大型语言模型(LLM)与人类的价值观和偏好对齐是一个具有挑战性的任务。传统的方法,例如来自人类反馈的强化学习(RLHF),通过将人类的输入整合到模型的输出中,已经为此铺平了道路。然而,RLHF可能很复杂,需要大量的计算资源和数据处理。直接偏好优化(DPO)作为一种新颖且更简化的方法,提供了一个高效的替代方案,简化了优化过程,不仅减少了计算负担,还增强了模型快速适应人类偏好的能力。
在本指南中,我们将深入探讨DPO,探索其基础、实现和实际应用。
偏好对齐的必要性
要了解DPO,首先需要了解为什么将LLM与人类偏好对齐如此重要。尽管LLM具有令人印象深刻的能力,但在某些情况下,它们可能会产生不一致、有偏见或与人类价值观不符的输出。这种不符可以以多种方式表现出来:
- 生成不安全或有害的内容
- 提供不准确或误导性的信息
- 表现出训练数据中的偏见
为了解决这些问题,研究人员已经开发了使用人类反馈来微调LLM的技术。其中最著名的方法是RLHF。
理解RLHF:DPO的前身
来自人类反馈的强化学习(RLHF)一直是将LLM与人类偏好对齐的主要方法。让我们分解RLHF的过程,以了解其复杂性:
a)监督微调(SFT):该过程从在高质量响应数据集上微调预训练的LLM开始。这一步有助于模型为目标任务生成更相关、更连贯的输出。
b)奖励建模:训练一个单独的奖励模型来预测人类偏好。这涉及:
- 为给定的提示生成响应对
- 让人类评估哪个响应更受欢迎
- 训练一个模型来预测这些偏好
c)强化学习:然后使用强化学习进一步优化微调的LLM。奖励模型提供反馈,指导LLM生成与人类偏好一致的响应。
以下是RLHF过程的简化Python伪代码:
虽然有效,但RLHF有一些缺点:
- 需要训练和维护多个模型(SFT、奖励模型和RL优化模型)
- RL过程可能不稳定,且对超参数敏感
- 计算成本高,需要对模型进行许多前向和后向传递
这些限制促使人们寻找更简单、更高效的替代方法,从而导致了DPO的发展。
直接偏好优化:核心概念

直接偏好优化 https://arxiv.org/abs/2305.18290
这张图片对比了两种不同的方法来使LLM的输出与人类偏好一致:来自人类反馈的强化学习(RLHF)和直接偏好优化(DPO)。RLHF依赖于奖励模型来通过迭代反馈循环引导语言模型的策略,而DPO直接优化模型输出以匹配人类偏好的响应,使用偏好数据。这种比较突出了每种方法的优点和潜在应用,提供了对未来LLM如何训练以更好地符合人类期望的见解。
DPO背后的关键思想:
a)隐式奖励建模:DPO消除了对单独奖励模型的需求,将语言模型本身视为隐式奖励函数。
b)基于策略的公式:DPO直接优化策略(语言模型)以最大化首选响应的概率,而不是优化奖励函数。
c)闭式解:DPO利用数学洞察力,允许对最优策略进行闭式求解,避免了对迭代RL更新的需求。
实现DPO:实践代码演示
以下图片展示了使用PyTorch实现DPO损失函数的代码片段。该函数在优化语言模型的输出以匹配人类偏好方面起着至关重要的作用。以下是关键组件的分解:
- 函数签名:`dpo_loss`函数接受多个参数,包括策略对数概率(`pi_logps`)、参考模型对数概率(`ref_logps`)和首选和不首选完成的索引(`yw_idxs`、`yl_idxs`)。此外,`beta`参数控制KL惩罚的强度。
- 对数概率提取:代码从策略和参考模型中提取首选和不首选完成的对数概率。
- 对数比率计算:计算策略和参考模型中首选和不首选完成的对数概率差。该比率在确定优化的方向和幅度方面至关重要。
- 损失和奖励计算:使用`logsigmoid`函数计算损失,而奖励则通过将策略和参考对数概率之间的差异乘以`beta`来确定。

使用PyTorch的DPO损失函数
让我们深入了解DPO背后的数学原理,以了解它如何实现这些目标。
DPO的数学原理
DPO是偏好学习问题的巧妙重构。以下是逐步分解:
a)起点:KL约束奖励最大化
原始RLHF目标可以表述为:
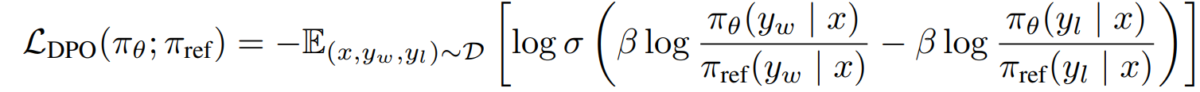
- πθ是我们优化的策略(语言模型)
- r(x,y)是奖励函数
- πref是参考策略(通常是初始SFT模型)
- β控制KL散度约束的强度
b)最优策略形式:可以证明该目标的最优策略具有以下形式:
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))其中Z(x)是归一化常数。
c)奖励-策略二元性:DPO的关键见解是将奖励函数表示为最优策略的形式:
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))d)假设偏好遵循Bradley-Terry模型,我们可以将y1比y2更受欢迎的概率表示为:
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))其中σ是逻辑函数。
e)DPO目标 将我们的奖励-策略二元性代入偏好模型,我们得到DPO目标:
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]该目标可以使用标准梯度下降技术进行优化,无需RL算法。
实现DPO
现在我们已经理解了DPO的理论,让我们来看看如何在实践中实现它。我们将使用Python和PyTorch来演示:
import torch
import torch.nn.functional as F
<p>class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)</p>
<p>def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty</p>
<p>每对(yw_idxs[i],yl_idxs[i])代表单个偏好对的索引。
"""</p>
<p># 提取首选和不首选完成的对数概率
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]</p>
<p># 计算对数比率
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps</p>
<p># 计算DPO损失
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()</p>
return losses.mean(), rewards
<p>def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()</p>
<p># 计算模型和参考模型的对数概率
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)</p>
<p># 计算损失
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()</p>
return loss.item()
<p># 使用方法
model = YourLanguageModel() # 初始化您的模型
ref_model = YourLanguageModel() # 加载预训练的参考模型
trainer = DPOTrainer(model, ref_model)</p>
<p>for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
挑战和未来方向
虽然DPO提供了显著的优势,但仍然存在挑战和需要进一步研究的领域:
a)扩展到更大的模型:
随着语言模型的不断增长,高效地将DPO应用于具有数百亿参数的模型仍然是一个开放的挑战。研究人员正在探索以下技术:
- 高效的微调方法(例如LoRA、前缀调优)
- 分布式训练优化
- 梯度检查点和混合精度训练
使用LoRA与DPO的示例:
<p>from peft import LoraConfig, get_peft_model</p> <p>class DPOTrainerWithLoRA(DPOTrainer): def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8): lora_config = LoraConfig( r=lora_rank, lora_alpha=32, target_modules=["q_proj", "v_proj"], lora_dropout=0.05, bias="none", task_type="CAUSAL_LM" ) self.model = get_peft_model(model, lora_config) self.ref_model = ref_model self.beta = beta self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)</p> <p># 使用方法 base_model = YourLargeLanguageModel() dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
b)多任务和少样本适应:
开发DPO技术,以便在有限的偏好数据的情况下高效地适应新任务或领域,是一个活跃的研究领域。正在探索的方法包括:
- 元学习框架,用于快速适应
- 基于提示的微调,用于DPO
- 从一般偏好模型到特定领域的迁移学习
c)处理模糊或冲突的偏好:
实际偏好数据通常包含模糊性或冲突。提高DPO对此类数据的鲁棒性至关重要。潜在的解决方案包括:
- 概率偏好建模
- 主动学习,用于解决模糊性
- 多代理偏好聚合
概率偏好建模的示例:
<p>class ProbabilisticDPOTrainer(DPOTrainer): def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob): # 计算对数比率 pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs] ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]</p> <p>log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1) loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) + (1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff)) return loss.mean()</p> <p># 使用方法 trainer = ProbabilisticDPOTrainer(model, ref_model) loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80%的偏好置信度
d)将DPO与其他对齐技术结合:
将DPO与其他对齐方法相结合可能会导致更强大、更具鲁棒性的系统:
- 宪法AI原则,用于显式约束满足
- 辩论和递归奖励建模,用于复杂偏好提取
- 逆强化学习,用于推断潜在的奖励函数
将DPO与宪法AI相结合的示例:
<p>class ConstitutionalDPOTrainer(DPOTrainer): def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None): super().__init__(model, ref_model, beta, lr) self.constraints = constraints or []</p> <p>def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs): base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)</p> <p>constraint_loss = 0 for constraint in self.constraints: constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)</p> return base_loss + constraint_loss <p># 使用方法 def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs): # 实现安全检查逻辑 unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps) return torch.relu(unsafe_score - 0.5) # 惩罚如果unsafe_score > 0.5</p> <p>constraints = [safety_constraint] trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)</p>
实用考虑和最佳实践
在为实际应用实现DPO时,请考虑以下提示:
a)数据质量:偏好数据的质量至关重要。确保您的数据集:
- 涵盖了多样化的输入和期望行为
- 具有一致且可靠的偏好注释
- 平衡了不同类型的偏好(例如,事实性、安全性、风格)
b)超参数调优:虽然DPO的超参数比RLHF少,但调优仍然很重要:
- β(beta):
- 学习率:
- 批大小:
c)迭代改进:DPO可以迭代应用:
- 使用DPO训练初始模型
- 使用训练好的模型生成新响应
- 收集这些响应的新偏好数据
- 使用扩展的数据集重新训练

直接偏好优化性能
这张图片显示了像GPT-4这样的LLM在各种训练技术下的性能,包括直接偏好优化(DPO)、监督微调(SFT)和近端策略优化(PPO)。表格显示,GPT-4的输出越来越符合人类偏好,特别是在总结任务中。GPT-4与人类审查员之间的协议水平表明,该模型能够生成与人类评估者产生共鸣的内容,几乎与人类生成的内容一样。
案例研究和应用
为了说明DPO的有效性,让我们来看看一些实际应用和其变体:
- 迭代DPO:由Snorkel(2023)开发,该变体将拒绝采样与DPO相结合,实现更精细的训练数据选择过程。通过对偏好采样进行多轮迭代,该模型可以更好地泛化并避免过拟合到噪声或偏见的偏好。
- IPO(迭代偏好优化):由Azar等人(2023)引入,IPO添加了一个正则化项以防止过拟合,这是偏好优化中的一个常见问题。这种扩展允许模型在遵循偏好和保持泛化能力之间保持平衡。
- KTO(知识转移优化):Ethyarajh等人(2023)提出的一个更近期的变体,KTO完全消除了二元偏好。相反,它专注于从参考模型到策略模型的知识转移,优化模型输出与人类价值观的一致性。
- 多模态DPO用于跨域学习 由Xu等人(2024)提出:一个将DPO应用于不同模态(文本、图像和音频)的方法,展示了其在不同数据类型中与人类偏好对齐的多功能性。该研究强调了DPO在创建能够处理复杂、多模态任务的综合AI系统方面的潜力。












