Anderson 视角
Adobe 研究扩展解耦 GAN 人脸编辑

很容易理解为什么 耦合 是图像合成中的一个问题,因为它经常是其他领域的生活中的一个问题;例如,从咖喱中去除姜黄比从汉堡中去除泡菜更难,而从一杯咖啡中去除糖几乎是不可能的。有些东西只是捆绑在一起的。
同样,耦合是图像合成架构中的一个绊脚石,这些架构理想地希望在使用机器学习创建或编辑面部(或 狗、船 或任何其他领域)时分离出不同的特征和概念。
如果你可以分离出诸如 年龄、性别、头发颜色、皮肤色调、情绪 等等,你将拥有真正的工具和灵活性,可以在面部图像中创建和编辑,粒度很细,不会带来不想要的“乘客”。

在最大耦合(上左),你只能改变学习的 GAN 网络的图像到另一个人的图像。
这基本上是使用最新的 AI 计算机视觉技术来实现一种在 三十多年前 就已经解决的问题。
有一定程度的分离(上图中的“中等分离”),可以执行基于风格的更改,例如头发颜色、表情、化妆和有限的头部旋转等。

来源:FEAT:面部编辑与注意,2022 年 2 月,https://arxiv.org/pdf/2202.02713.pdf
过去两年中,已经有多次尝试创建交互式面部编辑环境,允许用户使用滑块和其他传统 UI 交互更改面部特征,同时保持目标面部的核心特征完整。但是,这是一个挑战,因为 GAN 的潜在空间中存在潜在的特征/风格耦合。
例如,眼镜 特征经常与 年龄 特征交织在一起,这意味着添加眼镜可能也会“老化”面部,而老化面部可能会添加眼镜,取决于应用的高级特征分离程度(见下面的“测试”部分)。
最值得注意的是,几乎不可能改变头发颜色和其他头发方面而不重新计算头发线和摆放,这会产生“嘶嘶”的过渡效果。

来源:InterFaceGAN 演示(CVPR 2020),https://www.youtube.com/watch?v=uoftpl3Bj6w
潜在到潜在 GAN 遍历
Adobe 领导的一篇新论文 提交 到 WACV 2022,提出了一种解决这些潜在问题的新方法,论文名为 潜在到潜在:一种学习的映射器,用于在 StyleGAN 生成的图像中保留身份的多个面部属性编辑。

补充材料来自论文潜在到潜在:一种学习的映射器,用于在 StyleGAN 生成的图像中保留身份的多个面部属性编辑。这里我们看到,在学习的面部中,基本特征不会被拖入无关的变化中。查看文章末尾的视频嵌入以获取更好的细节和分辨率。来源:https://www.youtube.com/watch?v=rf_61llRH0Q
该论文由 Adobe 应用科学家 Siavash Khodadadeh 领导,其他四位 Adobe 研究人员和来自佛罗里达中部大学计算机科学系的一位研究人员共同参与。
这篇文章有趣的部分是,Adobe 一直在这个领域工作,这让人很容易想象这种功能会在未来几年进入 Creative Suite 项目;但主要是因为该项目创建的架构采取了不同的方法来保持 GAN 面部编辑器的视觉完整性,同时应用更改。
作者声明:
‘[我们] 训练一个神经网络执行潜在到潜在的转换,找到对应于具有更改属性的图像的潜在编码。由于该技术是一次性的,因此它不依赖于属性渐进变化的线性或非线性轨迹。’
‘通过在整个生成管道上对网络进行端到端训练,该系统可以适应现成的生成器架构。保护属性,例如保持人的身份,可以以训练损失的形式编码。’
‘一旦潜在到潜在的网络被训练,它就可以在不需要重新训练的情况下重复用于任意图像。’
这最后一部分意味着提出的架构以最终用户的形式到达,并且已经完成。它仍然需要在本地资源上运行神经网络,但新的图像可以“放入”并几乎立即准备好进行修改,因为框架已经解耦,不需要进一步的图像特定训练。
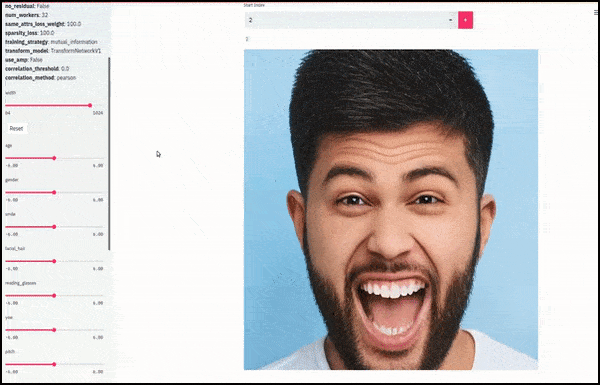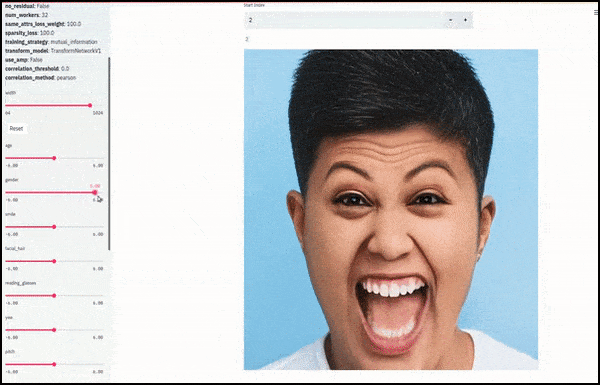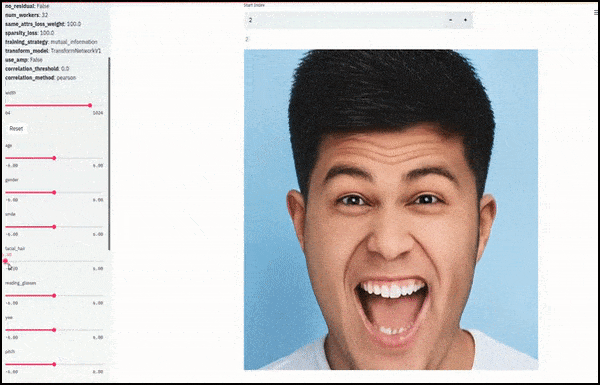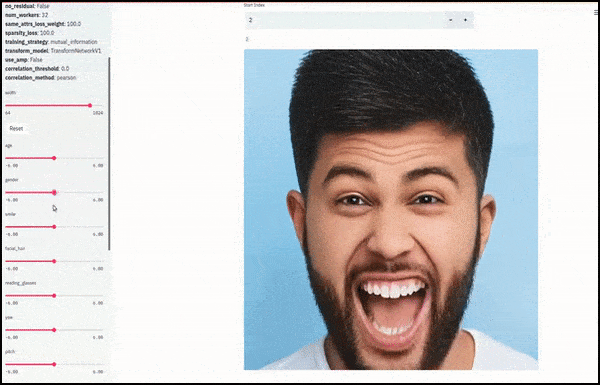
性别和面部毛发随着滑块绘制随机和任意路径通过潜在空间,而不仅仅是“擦除端点之间”。查看文章末尾的视频嵌入以获取更好的转换和更高的分辨率。
在这项工作中,主要成就是网络能够在潜在空间中“冻结”身份,只更改目标向量中的属性,并提供“纠正项”以保持正在转换的身份。
基本上,提出的网络嵌入在一个更广泛的架构中,所有处理的元素都通过预训练的组件传递,这些组件具有冻结的权重,不会对转换产生不想要的侧面影响。
由于训练过程依赖于 三元组,这些三元组可以通过种子图像(在 GAN 反转 下)或现有的初始潜在编码生成,因此整个训练过程是无监督的,通常在此类系统中使用的标签和策划系统的隐式操作基本上已经融入了架构中。事实上,新系统使用现成的属性回归器:
‘[我们] 网络可以独立控制的属性数量仅受限于识别器(s)的能力 – 如果您有一个识别器用于属性,我们可以将其添加到任意面部。 在我们的实验中,我们训练了潜在到潜在的网络,以允许调整 35 个不同的面部属性,超过任何以前的方法。’
该系统包含一个额外的保障措施,以防止不需要的“副作用”转换:如果没有请求属性更改,潜在到潜在的网络将潜在向量映射到自身,从而进一步增加了目标身份的稳定性。
面部识别
过去几年中,GAN 和编码器/解码器基于的面部编辑器的一个反复出现的问题是,应用的转换往往会降低相似度。为了解决这个问题,Adobe 项目使用了一个名为 FaceNet 的嵌入式面部识别网络作为判别器。

项目架构,查看下中左侧的 FaceNet 包含。来源:潜在到潜在:一种学习的映射器,用于在 StyleGAN 生成的图像中保留身份的多个面部属性编辑,OpenAccess。
(在个人笔记中,这似乎是一个令人鼓舞的举动,朝着将标准的面部识别和甚至表情识别系统集成到生成网络中迈出了一步,可能是克服当前深度伪造架构中占主导地位的盲像素到像素映射的最佳方法,代价是牺牲表情的忠实度和面部生成领域中的其他重要领域。)
潜在空间中的所有区域
该框架的另一个令人印象深刻的功能是它能够在用户的任性下在潜在空间中任意行进。以前的几个系统提供了探索式接口,通常会让用户基本上“擦除”固定特征转换时间线之间 -令人印象深刻,但通常是一种线性或规定的体验。

来自提高 GAN 平衡通过提高空间意识:这里,用户擦除两个潜在空间位置之间的一系列潜在转换点,但在预训练的潜在空间位置的约束下。要应用同一材料的其他类型的转换,重新配置和/或重新训练是必要的。来源:https://genforce.github.io/eqgan/
除了能够接受完全新的用户图像外,用户还可以手动“冻结”他们想要在转换过程中保留的元素。这样,用户可以确保(例如)背景不会移动,或者眼睛保持睁开或闭合。
数据
属性回归网络是在三个网络上训练的:FFHQ、CelebAMask-HQ 和一个本地生成的网络,通过从 StyleGAN-V2 的 Z 空间中采样 400,000 个向量获得。
过滤掉分布外(OOD)图像,并使用 Microsoft 的 Face API 提取属性,得到的图像集被分成 90/10,剩下 721,218 个训练图像和 72,172 个测试图像进行比较。
测试
虽然实验网络最初配置为适应 35 个潜在转换,但这些被缩小到八个,以便对比可比框架 InterFaceGAN、GANSpace 和 StyleFlow 进行类似的测试。
所选的八个属性是 年龄、秃头、胡须、表情、性别、眼镜、俯仰 和 偏航。需要重新配置竞争框架以适应八个属性中的某些属性,例如将 秃头 和 胡须 添加到 InterFaceGAN 中。
如预期,竞争框架中出现了更高程度的耦合。例如,在一个测试中,InterFaceGAN 和 StyleFlow 都在请求 年龄 时改变了主题的性别:

两个竞争框架将性别更改融入“年龄”转换中,还更改了头发颜色,而没有用户的直接要求。
此外,两个对手发现眼镜和年龄是不可分割的方面:

眼镜和头发颜色更改都包含在内!
这并不是对研究的全面胜利;如文章末尾嵌入的视频所示,该框架在尝试外推多样化角度(偏航)时是最不有效的,而 GANSpace 对于 年龄 和眼镜的施加有更好的总体结果。潜在到潜在的框架在添加俯仰(头部角度)方面与 GANSpace 和 StyleFlow 并列。

基于 MTCNN 面部检测器的校准计算结果。结果越低越好。
有关更多详细信息和示例的更好分辨率,请查看文章末尾的论文附件视频。
首次发布于 2022 年 2 月 16 日。












