Anderson 视角
面向新一代深度伪造的法医数据方法

尽管私人个人的深度伪造已经成为一个日益增长的公共关注点,并且在各个地区日益被禁止,但证明一个用户创建的模型(例如用于报复色情的模型)是专门针对某个人的图像进行训练的仍然极具挑战性。
为了理解这个问题:深度伪造攻击的一个关键元素是虚假地声称某个图像或视频描绘了某个特定的人。仅仅声称视频中的人是身份#A,而不是仅仅是一个相似的人,就足以造成伤害,而且在这种情况下不需要任何人工智能。
然而,如果攻击者使用训练有素的模型生成人工图像或视频,社交媒体和搜索引擎的面部识别系统将自动将伪造的内容与受害者关联起来,无需在帖子或元数据中包含名称。人工生成的视觉内容本身就能保证这种关联。
一个人越是具有独特的外貌,这种情况就越是不可避免,直到伪造的内容出现在图像搜索中,最后到达受害者。
面对面
目前,分发以身份为中心的模型最常见的方式是通过低秩适应(LoRA),用户训练少数图像几个小时,以更大的基础模型(如稳定扩散(主要用于静态图像)或Hunyuan视频)为基础进行训练。
LoRA最常见的目标,包括新的基于视频的LoRA,都是女明星,他们的名气使他们更容易受到这种对待,公众批评较少,尤其是与“未知”受害者相比,因为人们认为这种衍生作品属于“合理使用”(至少在美国和欧洲如此)。

女明星占据了civit.ai门户上的LoRA和Dreambooth列表。最受欢迎的LoRA目前已有超过66,000次下载,这是相当可观的,考虑到这种人工智能的使用仍被视为“边缘”活动。
然而,对于非名人深度伪造的受害者来说,没有这样的公共论坛,他们只会在起诉案件出现时或受害者在热门媒体上发言时出现在媒体上。
但是,在这两种情况下,用于伪造目标身份的模型已经将其训练数据“提纯”到模型的潜在空间中,以至于很难识别出用于训练的源图像。
如果有可能在可接受的误差范围内做到这一点,那么这将使得起诉那些分享LoRA的人成为可能,因为这不仅证明了伪造特定身份(即特定“未知”人的身份,即使在诽谤过程中没有提及他们)的意图,还使上传者面临版权侵权指控(在适用情况下)。
后者在法规滞后或缺乏的司法管辖区将很有用。
过度暴露
训练基础模型(如从Hugging Face下载的多个GB的基础模型)的目标是使模型变得普遍且具有可塑性。这涉及训练足够多的多样化图像,并使用适当的设置,并在模型“过度拟合”到数据之前结束训练。
一个过度拟合的模型已经在训练过程中多次(过度)看到数据,因此它将倾向于重现非常相似的图像,从而暴露训练数据的来源。

身份“Ann Graham Lotz”可以在Stable Diffusion V1.5模型中几乎完美地重现。重建几乎与训练数据(图像左侧)相同。 来源:https://arxiv.org/pdf/2301.13188
然而,过度拟合的模型通常被其创建者丢弃,而不是分发,因为它们不适合目的。因此,这是一个不太可能的法医“幸运发现”。在任何情况下,这个原理更适用于昂贵的高容量基础模型的训练,在那里,多个版本的同一图像可能使某些训练图像容易被调用(见图像和上面的示例)。
事情对LoRA和Dreambooth模型略有不同(尽管Dreambooth由于其大文件大小已经过时)。在这里,用户选择有限数量的多样化图像,并使用它们来训练LoRA。

左侧为Hunyuan Video LoRA的输出。右侧为使相似性成为可能的数据(使用所描绘人员的许可使用的图像)。
通常,LoRA将具有训练好的触发词,例如[nameofcelebrity]。但是,即使没有这样的提示,特定训练的主题也经常出现在生成的输出中,因为即使是平衡的(即没有过度拟合的)LoRA也对其训练材料有一定的“执着”,并且会倾向于在任何输出中包含它。
这种倾向性,结合LoRA数据集的有限图像数量,使得模型容易受到法医分析。
揭开数据的面纱
这些问题在丹麦的一篇新论文中得到了解决,该论文提出了一种方法来识别黑盒Membership Inference Attack(MIA)中的源图像(或图像组)。这种技术至少部分涉及使用自定义训练的模型来帮助通过生成自己的“深度伪造”来暴露源数据:

新方法生成的“假”图像示例,在逐渐增加的分类器自由指导(CFG)级别下,直到破坏。 来源:https://arxiv.org/pdf/2502.11619
虽然这项工作,题为针对细化的潜在扩散模型的面部图像的会员推理攻击,是该领域文献的有趣贡献,但它也是一个难以理解的论文,需要大量解码。因此,我们将在这里介绍该项目背后的基本原理和一些结果。
实际上,如果有人在你的脸上微调AI模型,这种方法可以帮助证明这一点,方法是寻找模型生成的图像中的记忆迹象。
首先,目标AI模型在一组面部图像上进行微调,使其更有可能在其输出中重现这些图像中的细节。然后,使用AI模型生成的图像作为“正”例(疑似训练集成员),以及来自不同数据集的其他图像作为“负”例(非成员)来训练分类器攻击模式。
通过学习这些组之间的微妙差异,攻击模型可以预测给定图像是否是原始微调数据集的一部分。
这种攻击在模型经过大量微调的情况下最为有效,特别是那些针对特定图像集(如某个个人的面部)进行训练的模型。然而,虽然这种攻击可以确定是否使用了某个数据集,但它难以识别数据集中的个别图像。
在实践中,后者并不是使用这种方法进行法医分析的障碍;虽然确定像ImageNet这样的著名数据集是否被使用并没有太大价值,但针对私人个人的攻击者往往具有有限的源数据选择,并需要充分利用可用的数据组(如社交媒体相册和其他在线集合)。这些集合有效地创建了一个“哈希”,可以通过所述方法发现。
该论文指出,另一种提高准确性的方法是使用AI生成的图像作为“非成员”,而不是仅仅依赖于真实图像。这可以防止由于依赖真实图像而可能误导结果的高成功率。
作者还指出,水印是一个显著影响检测的因素。当训练图像包含可见水印时,攻击变得非常有效,而隐藏水印几乎没有任何优势。

右侧图像显示测试中使用的实际“隐藏”水印。
最后,文本到图像生成中的指导级别也起着作用,理想的平衡点大约在8左右。即使没有直接提示,微调后的模型仍然倾向于产生类似其训练数据的输出,从而增强了攻击的有效性。
方法/数据
丹麦技术大学(DTU)的几个数据集被用于这项研究,用于微调目标模型和训练和测试攻击模式。
DseenDTU 基础图像集。
DDTU 从DTU Orbit中抓取的图像。
DseenDTU 用于微调目标模型的DDTU的分区。
DunseenDTU 未用于微调任何图像生成模型的DDTU的分区,而是用于测试或训练攻击模型。
WmDseenDTU 用于微调目标模型的DDTU的分区,带有可见水印。
hwmDseenDTU 用于微调目标模型的DDTU的分区,带有隐藏水印。
DgenDTU 由在DseenDTU图像集上微调的潜在扩散模型(LDM)生成的图像。
用于微调目标模型的数据集由图像-文本对组成,文本由BLIP字幕模型标注(可能不是巧合,这是非限制性人工智能社区中最受欢迎的模型之一)。
BLIP被设置为在每个描述前添加短语‘a dtu headshot of a’。
此外,来自奥尔堡大学(AAU)的几个数据集被用于测试,所有数据集都来自AU VBN语料库:
DAAU 从AAU VBN中抓取的图像。
DseenAAU 用于微调目标模型的DAAU的分区。
DunseenAAU 未用于微调任何图像生成模型的DAAU的分区,而是用于测试或训练攻击模型。
DgenAAU 由在DseenAAU图像集上微调的LDM生成的图像。
与前面的集合类似,短语‘a aau headshot of a’被使用,以确保DTU数据集中的所有标签都遵循‘a dtu headshot of a (…)’的格式,在微调过程中强化了数据集的核心特征。
测试
进行了多个实验来评估会员推理攻击对目标模型的性能。每个测试旨在确定是否可以在下图所示的模式中成功执行攻击,其中目标模型在未经授权获得的图像数据集上进行微调。

方法的模式。
使用微调后的模型生成输出图像,然后使用这些图像作为攻击模型的正例,而将其他无关图像作为负例。
攻击模型使用监督学习进行训练,然后在新图像上进行测试,以确定它们是否最初是用于微调目标模型的数据集的一部分。为了评估攻击的准确性,15%的测试数据被设置为验证。
由于目标模型是在已知的数据集上进行微调的,因此在创建攻击模型的训练数据时,每个图像的成员身份状态已经确定。这使得可以清楚地评估攻击模型在区分图像是否属于微调数据集的能力。
对于这些测试,使用了Stable Diffusion V1.5。虽然这个相当旧的模型经常出现在研究中,主要是由于需要一致的测试和使用该模型的先前工作的大量语料库,但这是一个合适的用例;V1.5在稳定扩散的爱好者社区中仍然很受欢迎,主要是因为它没有审查,即使在多个后续版本发布之后,即使在Flux的出现之后——因为该模型完全没有审查。
研究人员的攻击模型基于Resnet-18,保留了预训练的权重。ResNet-18的1000个神经元的最后一层被替换为一个具有两个神经元的全连接层。训练损失为分类交叉熵,使用Adam优化器。
对于每个测试,攻击模型使用不同的随机种子进行了五次训练,以计算关键指标的95%置信区间。使用CLIP模型进行零次分类作为基线。
(请注意,论文中的原始主要结果表格简洁且难以理解。因此,我将其重新格式化为更用户友好的格式。请单击图像以查看更高的分辨率)
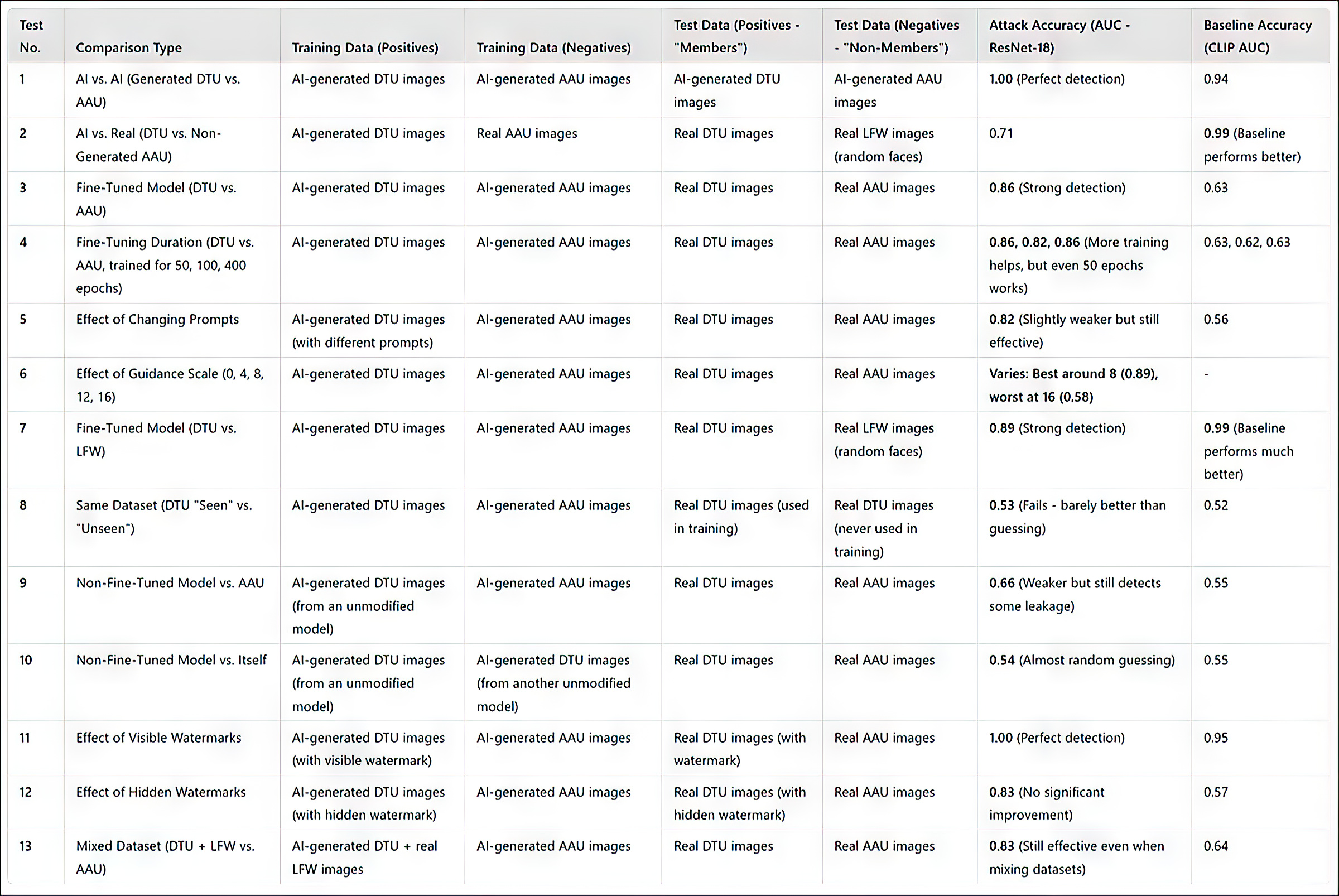
所有测试的结果摘要。单击图像以查看更高的分辨率
研究人员的攻击方法在针对微调模型(尤其是那些针对特定图像集训练的模型)时最为有效。然而,虽然攻击可以确定是否使用了某个数据集,但它难以识别数据集中的个别图像。
在实践中,后者并不是使用这种方法进行法医分析的障碍;虽然确定像ImageNet这样的著名数据集是否被使用并没有太大价值,但针对私人个人的攻击者往往具有有限的源数据选择,并需要充分利用可用的数据组(如社交媒体相册和其他在线集合)。这些集合有效地创建了一个“哈希”,可以通过所述方法发现。
该论文指出,另一种提高准确性的方法是使用AI生成的图像作为“非成员”,而不是仅仅依赖于真实图像。这可以防止由于依赖真实图像而可能误导结果的高成功率。
作者还指出,水印是一个显著影响检测的因素。当训练图像包含可见水印时,攻击变得非常有效,而隐藏水印几乎没有任何优势。

右侧图像显示测试中使用的实际“隐藏”水印。
最后,文本到图像生成中的指导级别也起着作用,理想的平衡点大约在8左右。即使没有直接提示,微调后的模型仍然倾向于产生类似其训练数据的输出,从而增强了攻击的有效性。
结论
这篇有趣的论文以一种难以理解的方式写成,这是令人遗憾的,因为它应该对隐私倡导者和非专业的AI研究人员都很有趣。
虽然会员推理攻击可能会成为一个有趣且富有成果的法医工具,但也许更重要的是,这条研究途径应该发展出可应用的广泛原则,以防止它陷入与深度伪造检测相同的“打地鼠”游戏中,当新模型的发布对检测和类似的法医系统产生不利影响时。
由于这项新研究中有一些证据表明存在更高层次的指导原则,我们可以希望看到更多在这个方向上的工作。
最初发布于2025年2月21日星期五












