Штучний інтелект
Алгоритм міг би вирішити проблему расової упередженості в сфері охорони здоров’я, якщо його правильно натренувати
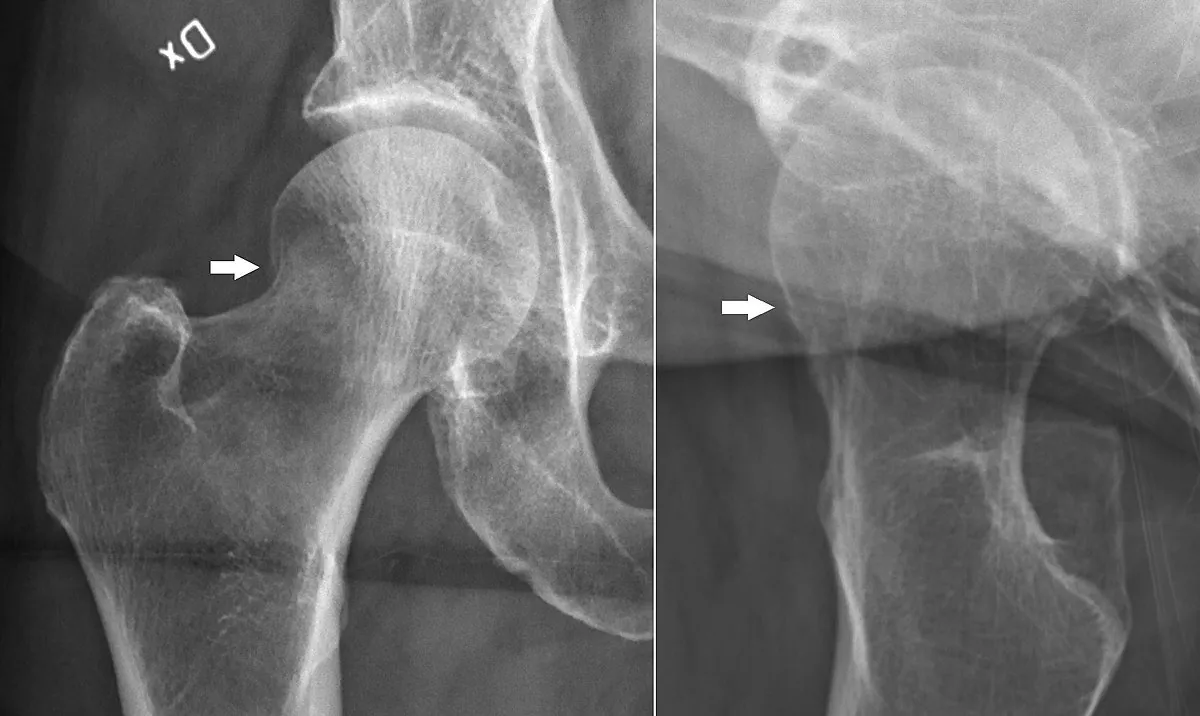
Команда дослідників з Стенфордського університету, Гарвардського університету та Чиказького університету натренувала алгоритми для діагностики артриту на рентгенограмах колін. Виявилося, що коли дані пацієнтів використовуються як тренувальні дані для алгоритму, алгоритм був більш точним, ніж радіологи при аналізі записів пацієнтів афроамериканців.
Проблема алгоритмічної упередженості
Використання алгоритмів машинного навчання в сфері медицини потенційно може покращити результати лікування пацієнтів, які страждають на різні захворювання, але також існують добре задокументовані проблеми з використанням алгоритмів штучного інтелекту для діагностики пацієнтів. Дослідження впливу розгорнутих моделей штучного інтелекту виявили ряд помітних інцидентів, пов’язаних з алгоритмічною упередженістю. Серед них алгоритми, які направляють меншість пацієнтів у кардіологічні відділення, ніж білих пацієнтів, хоча всі симптоми були однаковими.
Один із авторів дослідження, професор Зіад Обермаєр з Школи громадського здоров’я Університету Каліфорнії у Берклі, вирішив використати штучний інтелект для дослідження розбіжностей між діагнозами рентгенограм радіологами та рівнем болю, який повідомили пацієнти. Хоча афроамериканські пацієнти та пацієнти з низькими доходами повідомляли про вищій рівень болю, їхні рентгенограми були оцінені так само, як і у загальної популяції. Дані про рівень болю були отримані з Національного інституту охорони здоров’я, і дослідники хотіли дізнатися, чи пропускають люди-лікарі щось при аналізі даних.
Як повідомляє Wired, щоб визначити потенційні причини цих розбіжностей, Обермаєр та інші дослідники створили комп’ютерну модель візуального сприйняття, натреновану на даних Національного інституту охорони здоров’я. Алгоритми були розроблені для аналізу рентгенограм та передбачення рівня болю пацієнта на основі зображень. Програмне забезпечення виявило закономірності в зображеннях, які були тісно пов’язані з рівнем болю пацієнта.
Коли алгоритм представлений з невідомим зображенням, модель повертає передбачення рівня болю пацієнта. Прогнози, повернуті моделлю, збігалися ближче з фактичним рівнем болю пацієнтів, ніж оцінки радіологів. Це було особливо вірно для афроамериканських пацієнтів. Обермаєр пояснив через Wired, що алгоритм комп’ютерного сприйняття міг виявити явища, які були більш часто пов’язані з болем у афроамериканських пацієнтів.
Натренування систем правильно
Згідно повідомлень, критерії оцінки рентгенограм були спочатку розроблені на основі результатів малого дослідження, проведеного в північній Англії у 1957 році. Початкова популяція, використана для розробки критеріїв оцінки остеоартрозу, була значно різною від сучасної різноманітної популяції США, тому не дивно, що виникають помилки при діагностиці цих різноманітних людей.
Нове дослідження демонструє, що коли алгоритми штучного інтелекту правильно натреновані, вони можуть зменшити упередженість. Натренування проводилось на основі відгуку пацієнтів самих, а не на основі експертних оцінок. Обермаєр та його колеги раніше продемонстрували, що широко використовуваний алгоритм штучного інтелекту надавав перевагу білим пацієнтам над афроамериканськими пацієнтами, але Обермаєр також показав, що натренування системи машинного навчання на правильних даних може допомогти запобігти упередженості.
Існує помітна застереження до дослідження, знайома багатьом дослідникам машинного навчання. Модель штучного інтелекту, розроблена командою дослідників, є чорним ящиком, і сама команда дослідників не знає, які саме ознаки алгоритм виявляє на рентгенограмах, тобто вони не можуть сказати лікарям, чого їм бракує.
Інші радіологи та дослідники намагаються розібратися в чорному ящику та виявити закономірності в ньому, сподіваючись допомогти лікарям зрозуміти, чого їм бракує. Радіолог і професор Університету Еморі Джуді Гічоя збирає більш розширений і різноманітний набір рентгенограм для натренування моделі штучного інтелекту. Гічоя буде створювати докладні нотатки до цих рентгенограм. Ці нотатки будуть порівнюватися з виходом моделі, щоб побачити, чи можна виявити закономірності, виявлені алгоритмом.












