ШІ 101
Що таке Теорема Баєса?
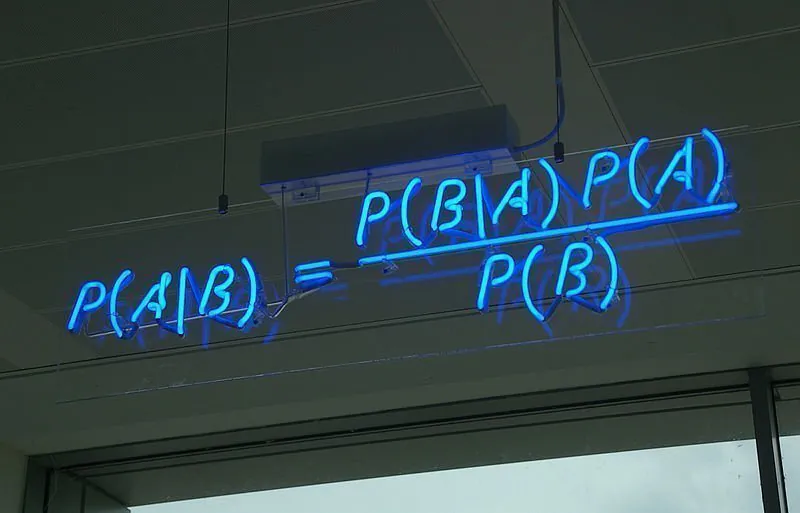
Якщо ви вивчали дані науки або машинне навчання, є велика ймовірність, що ви вже чули термін “Теорема Баєса” раніше, або “класифікатор Баєса”. Ці концепції можуть бути трохи плутаними, особливо якщо ви не звикли думати про ймовірність з традиційної, частотної статистичної точки зору. Ця стаття спробує пояснити принципи, що стоять за Теоремою Баєса, і як вона використовується в машинному навчанні.
Що таке Теорема Баєса?
Теорема Баєса – це метод обчислення умовної ймовірності. Традиційний метод обчислення умовної ймовірності (ймовірність того, що одна подія відбувається, якщо відбувається інша подія) полягає в тому, щоб використовувати формулу умовної ймовірності, обчислювати спільну ймовірність події один і події два, що відбуваються в одночасно, і потім ділити її на ймовірність події два. Однак умовну ймовірність також можна обчислювати трохи іншим способом, використовуючи Теорему Баєса.
Коли ви обчислюєте умовну ймовірність за допомогою Теореми Баєса, ви використовуєте наступні кроки:
- Визначте ймовірність того, що умова Б є істинною, якщо умова А є істинною.
- Визначте ймовірність того, що подія А є істинною.
- Помножте дві ймовірності разом.
- Поділите на ймовірність того, що подія Б відбувається.
Це означає, що формула Теореми Баєса може бути виражена так:
P(A|B) = P(B|A)*P(A) / P(B)
Обчислення умовної ймовірності таким чином особливо корисно, коли зворотна умовна ймовірність можна легко обчислити, або коли обчислення спільної ймовірності було б надто складним.
Приклад Теореми Баєса
Це може бути легше зрозуміти, якщо ми розглянемо приклад того, як ви застосовуєте баєсівське міркування і Теорему Баєса. Припустимо, ви граєте в просту гру, де кілька учасників розповідають вам історію, і вам потрібно визначити, хто з учасників бреше вам. Припустимо, ми хочемо заповнити рівняння Теореми Баєса змінними в цьому гіпотетичному сценарії.
Ми намагаємося спрогнозувати, чи кожна особа в грі бреше чи говорить правду, тому категоріальні змінні можна виразити як А1, А2 і А3. Докази їхньої брехні/правди – їхнє поведінка. Як і при грі в покер, ви шукали б певних “приміток” того, що людина бреше, і використовували б ці відомості, щоб сформувати свою думку. Або якщо вам було дозволено запитувати їх, це було б будь-який доказ того, що їхня історія не складалася. Ми можемо представити доказ того, що людина бреше, як Б.
Щоб бути ясним, ми намагаємося спрогнозувати ймовірність (А бреше/говорить правду|даних доказів їхньої поведінки). Для цього нам потрібно визначити ймовірність Б, дану А, або ймовірність того, що їхнє поведінка буде такою, якщо людина справді бреше чи говорить правду. Ви намагаєтеся визначити, під яких умов їхнє поведінка мав би найбільший сенс. Якщо ви спостерігаєте три поведінки, ви зробили б розрахунок для кожної поведінки. Наприклад, P(B1, B2, B3 * A). Ви зробили б це для кожного випадку А/для кожної людини в грі, крім вас. Це частина рівняння вище:
P(B1, B2, B3,|A) * P|A
Нарешті, ви просто ділите це на ймовірність Б.
Якщо ми отримали б будь-які відомості про фактичні ймовірності в цьому рівнянні, ми переробили б нашу модель ймовірності, враховуючи нові відомості. Це називається оновленням наших апріорних припущень, оскільки ви оновлюєте свої припущення про апріорну ймовірність спостережуваних подій.
Застосування машинного навчання для Теореми Баєса
Найпоширенішим застосуванням Теореми Баєса в машинному навчанні є алгоритм Наївного Баєса.
Наївний Баєс використовується для класифікації як двійкових, так і багатокласових наборів даних. Наївний Баєс отримав свою назву через те, що значення, призначені свідченням/атрибутам – Б в P(B1, B2, B3 * A) – вважаються незалежними один від одного. Припускається, що ці атрибути не впливають один на одного, щоб спростити модель і зробити розрахунки можливими, а не намагатися обчислити складні завдання розрахунку відносин між кожним з атрибутів. Незважаючи на це спрощене моделювання, Наївний Баєс має тенденцію добре виконувати свою роль як алгоритм класифікації, навіть коли це припущення, ймовірно, не є правдою (що відбувається більшу частину часу).
Існують також поширені варіанти класифікатора Наївного Баєса, такі як Багатомірний Наївний Баєс, Бернулліївський Наївний Баєс і Гаусівський Наївний Баєс.
Багатомірний Наївний Баєс часто використовується для класифікації документів, оскільки він ефективно інтерпретує частоту слів у документі.
Бернулліївський Наївний Баєс працює схожим чином з Багатомірним Наївним Баєсом, але передбачення, зроблені алгоритмом, є булевими. Це означає, що при передбаченні класу значення будуть двійковими, ні або так. У галузі текстової класифікації алгоритм Бернулліївського Наївного Баєса призначить параметрам так або ні, залежно від того, чи слово знайдено в текстовому документі.
Якщо значення передбачуваних/ознакових не дискретні, а є безперервними, Гаусівський Наївний Баєс можна використовувати. Припускається, що значення безперервних ознак вибрані з гаусівського розподілу.












