
AI 101
Що таке матриця плутанини?
Один із найпотужніших аналітичних інструментів у машинному навчанні та науці про дані в матриця плутанини. Матриця плутанини здатна надати дослідникам детальну інформацію про те, як працює класифікатор машинного навчання щодо цільових класів у наборі даних. Матриця плутанини продемонструє приклади відображення, які були належним чином класифіковані проти неправильно класифікованих прикладів. Давайте глибше розглянемо, як структурована матриця плутанини та як її можна інтерпретувати.
Що таке матриця плутанини?
Давайте почнемо з простого визначення матриці плутанини. Матриця плутанини — це інструмент прогнозної аналітики. Зокрема, це таблиця, яка відображає та порівнює фактичні значення з прогнозованими значеннями моделі. У контексті машинного навчання матриця плутанини використовується як метрика для аналізу того, як класифікатор машинного навчання працює з набором даних. Матриця плутанини генерує візуалізацію таких показників, як точність, точність, специфічність і запам’ятовування.
Причина, чому матриця плутанини є особливо корисною, полягає в тому, що, на відміну від інших типів показників класифікації, таких як проста точність, матриця плутанини створює більш повну картину того, як працює модель. Лише використання такого показника, як точність, може призвести до ситуації, коли модель повністю й послідовно неправильно визначає один клас, але це залишається непоміченим, оскільки середня продуктивність хороша. А тим часом матриця плутанини дає порівняння різних значень як помилкові негативи, справжні негативи, помилкові позитивні результати та справжні позитивні результати.
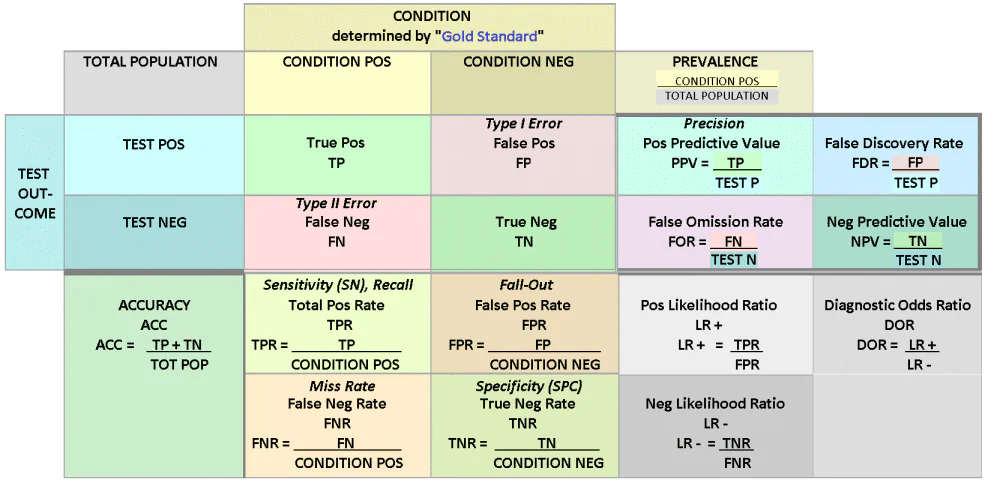
Давайте визначимо різні показники, які представляє матриця плутанини.
Згадайте в матриці плутанини
Відкликання — це кількість справді позитивних прикладів, поділена на кількість хибнонегативних прикладів і загальну кількість позитивних прикладів. Іншими словами, запам’ятовування репрезентує частку справжніх позитивних прикладів, які класифікувала модель машинного навчання. Відкликання вказано як відсоток позитивних прикладів, які модель змогла класифікувати з усіх позитивних прикладів, що містяться в наборі даних. Це значення також може називатися «показником», а пов’язане значення — «чутливість», який описує ймовірність відкликання або рівень справжніх позитивних прогнозів.
Точність в матриці плутанини
Як і пригадування, точність — це значення, яке відстежує ефективність моделі з точки зору класифікації позитивних прикладів. Однак, на відміну від відкликання, точність пов’язана з тим, скільки прикладів, які модель позначила позитивними, були справді позитивними. Щоб обчислити це, кількість істинно позитивних прикладів ділиться на кількість хибнопозитивних прикладів плюс істинно позитивні.
Щоб зробити різницю між відкликання та точність чіткіше, точність має на меті визначити відсоток усіх прикладів, позначених як позитивні, які були справді позитивними, тоді як пригадування відстежує відсоток усіх справді позитивних прикладів, які модель могла розпізнати.
Специфіка в матриці плутанини
Хоча запам’ятовування та точність є цінностями, які відстежують позитивні приклади та справжній позитивний рівень, специфічність кількісно визначає справжній негативний показник або кількість прикладів, які модель визначила як негативні, які були дійсно негативними. Це обчислюється шляхом ділення кількості прикладів, класифікованих як негативні, на кількість хибнопозитивних прикладів у поєднанні з істинно негативними прикладами.
Осмислення матриці плутанини

Фото: Jackverr через Wikimedia Commons, (https://commons.wikimedia.org/wiki/File:ConfusionMatrix.png), CC BY SA 3.0
Приклад матриці плутанини
Після визначення необхідних термінів, таких як точність, запам’ятовування, чутливість і специфічність, ми можемо дослідити, як ці різні значення представлені в матриці плутанини. Матриця плутанини генерується у випадках класифікації, застосовна, коли є два або більше класів. Створена матриця плутанини може бути такою високою та широкою, як це необхідно, утримувати будь-яку бажану кількість класів, але для спрощення ми розглянемо матрицю плутанини 2 x 2 для завдання двійкової класифікації.
Як приклад, припустимо, що класифікатор використовується для визначення того, чи є у пацієнта захворювання. Характеристики будуть подані в класифікатор, і класифікатор поверне одну з двох різних класифікацій – або пацієнт не має захворювання, або він має.
Почнемо з лівої частини матриці. Ліва частина матриці помилок представляє прогнози, зроблені класифікатором для окремих класів. Завдання двійкової класифікації матиме тут два рядки. Що стосується верхньої частини матриці, то вона відстежує справжні значення, фактичні мітки класу екземплярів даних.
Інтерпретація матриці плутанини може бути здійснена шляхом дослідження місця перетину рядків і стовпців. Перевірте прогнози моделі на справжні мітки моделі. У цьому випадку значення True Positives, кількість правильних позитивних прогнозів, розташовані у верхньому лівому куті. Помилкові спрацьовування знаходяться у верхньому правому куті, де насправді приклади є негативними, але класифікатор позначив їх як позитивні.
У нижньому лівому куті сітки показано випадки, які класифікатор позначив як негативні, але справді позитивні. Нарешті, у нижньому правому куті матриці плутанини знаходяться справжні негативні значення або де знаходяться справді помилкові приклади.
Коли набір даних містить більше двох класів, матриця збільшується на стільки класів. Наприклад, якщо є три класи, матриця буде матрицею 3 x 3. Незалежно від розміру матриці плутанини, метод їх інтерпретації абсолютно однаковий. Ліва сторона містить передбачені значення, а фактичні мітки класів розташовані вгорі. Екземпляри, які класифікатор правильно передбачив, проходять по діагоналі від верхнього лівого до нижнього правого кута. Дивлячись на матрицю, ви можете розрізнити чотири прогностичні метрики, розглянуті вище.
Наприклад, ви можете обчислити запам’ятовування, взявши істинні позитивні та хибні негативні результати, додавши їх разом і розділивши їх на кількість справді позитивних прикладів. Водночас точність можна обчислити, об’єднавши хибні спрацьовування з істинними спрацьовуваннями, а потім розділивши значення на загальну кількість справжніх спрацьовувань.
Хоча можна витратити час на ручне обчислення таких показників, як точність, запам’ятовуваність і специфічність, ці показники настільки широко використовуються, що більшість бібліотек машинного навчання мають методи їх відображення. Наприклад, Scikit-learn для Python має функцію генерації матриці плутанини.










