
AI 101
Що таке дерево рішень?
Що таке дерево рішень?
A дерево рішень це корисний алгоритм машинного навчання, який використовується як для завдань регресії, так і для класифікації. Назва «дерево рішень» походить від того факту, що алгоритм продовжує ділити набір даних на дедалі менші частини, доки дані не будуть розділені на окремі екземпляри, які потім класифікуються. Якби ви візуалізували результати алгоритму, спосіб розподілу категорій нагадував би дерево та багато листя.
Це коротке визначення дерева рішень, але давайте глибше зануримося в те, як працюють дерева рішень. Краще розуміння того, як працюють дерева рішень, а також варіанти їх використання, допоможе вам знати, коли їх використовувати під час проектів машинного навчання.
Формат дерева рішень
Дерево рішень є дуже схожий на блок-схему. Щоб використовувати блок-схему, ви починаєте з початкової точки або кореня діаграми, а потім, залежно від того, як ви відповідаєте критеріям фільтрації цього початкового вузла, ви переходите до одного з наступних можливих вузлів. Цей процес повторюється, поки не буде досягнуто кінця.
Дерева рішень працюють, по суті, так само, причому кожен внутрішній вузол у дереві є певним критерієм перевірки/фільтрації. Вузли назовні, кінцеві точки дерева, є мітками для відповідної точки даних, і вони називаються «листям». Гілки, які ведуть від внутрішніх вузлів до наступного вузла, є об’єктами або об’єднаннями об’єктів. Правила, які використовуються для класифікації точок даних, — це шляхи, що проходять від кореня до листя.
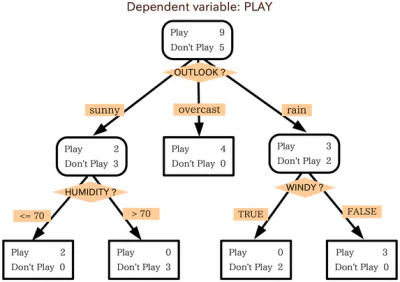
Алгоритми для дерев рішень
Дерева рішень працюють на основі алгоритмічного підходу, який розбиває набір даних на окремі точки даних на основі різних критеріїв. Ці розбиття виконуються за допомогою різних змінних або різних функцій набору даних. Наприклад, якщо мета полягає в тому, щоб визначити, чи описується собака чи кіт за допомогою вхідних характеристик, змінними, на які розділяються дані, можуть бути такі речі, як «кігті» та «гавкіт».
Отже, які алгоритми використовуються для фактичного поділу даних на гілки та листи? Існують різні методи, за допомогою яких можна розбити дерево, але найпоширенішим способом розбиття є техніка, яка називається «рекурсивне двійкове розбиття”. Під час виконання цього методу поділу процес починається з кореня, а кількість ознак у наборі даних представляє можливу кількість можливих поділів. Функція використовується, щоб визначити, скільки точності буде коштувати кожне можливе розбиття, і розбиття здійснюється за критерієм, який жертвує найменшою точністю. Цей процес здійснюється рекурсивно, і підгрупи формуються за тією ж загальною стратегією.
Для того, щоб визначити вартість розколу, використовується функція витрат. Для завдань регресії та завдань класифікації використовується інша функція вартості. Метою обох функцій витрат є визначення того, які гілки мають найбільш схожі значення відповіді або найбільш однорідні гілки. Подумайте, що ви хочете, щоб тестові дані певного класу йшли певними шляхами, і це має інтуїтивний сенс.
З точки зору регресійної функції вартості для рекурсивного двійкового розбиття, алгоритм, який використовується для обчислення вартості, такий:
sum(y – передбачення)^2
Прогноз для певної групи точок даних є середнім значенням відповідей навчальних даних для цієї групи. Усі точки даних проходять через функцію вартості, щоб визначити вартість для всіх можливих розподілів, і вибирається розділ із найнижчою вартістю.
Що стосується функції витрат для класифікації, то ця функція виглядає наступним чином:
G = сума (pk * (1 – pk))
Це оцінка Джіні, яка є показником ефективності розбиття на основі кількості екземплярів різних класів у групах, отриманих у результаті розбиття. Іншими словами, він кількісно визначає, наскільки змішаними є групи після поділу. Оптимальний розкол - це коли всі групи, отримані в результаті розбиття, складаються лише з вхідних даних одного класу. Якщо створено оптимальний розподіл, значення «pk» буде 0 або 1, а G дорівнюватиме нулю. Можливо, ви зможете здогадатися, що найгірший варіант розбиття — це той, у якому представлено 50-50 класів у поділі, у випадку двійкової класифікації. У цьому випадку значення «pk» буде 0.5, а G також буде 0.5.
Процес поділу завершується, коли всі точки даних перетворено на листя та класифіковано. Однак ви можете зупинити ріст дерева раніше. Великі складні дерева схильні до переобладнання, але для боротьби з цим можна використовувати кілька різних методів. Одним із методів зменшення надмірного оснащення є визначення мінімальної кількості точок даних, які використовуватимуться для створення листа. Інший метод контролю за надмірним облаштуванням — це обмеження дерева до певної максимальної глибини, яка контролює, як довго може простягатися шлях від кореня до листка.
Ще один процес, пов’язаний зі створенням дерев рішень відбувається обрізка. Відсікання може допомогти підвищити продуктивність дерева рішень, видаляючи гілки, що містять функції, які мають невелику передбачувану силу/неважливі для моделі. Таким чином, складність дерева зменшується, стає меншою ймовірність його переобладнання, а також збільшується прогностична корисність моделі.
При проведенні обрізки процес може починатися або з верхівки, або знизу дерева. Однак найпростіший спосіб обрізання — почати з листків і спробувати видалити вузол, який містить найпоширеніший клас у цьому листі. Якщо при цьому точність моделі не погіршується, зміна зберігається. Існують інші методи, які використовуються для скорочення, але метод, описаний вище – скорочення помилок – є, мабуть, найпоширенішим методом скорочення дерева рішень.
Міркування щодо використання дерев рішень
Рішення дерев часто корисні коли необхідно провести класифікацію, але основним обмеженням є час обчислення. Дерева рішень можуть чітко визначити, які функції у вибраних наборах даних мають найбільшу передбачувану силу. Крім того, на відміну від багатьох алгоритмів машинного навчання, де правила, що використовуються для класифікації даних, важко інтерпретувати, дерева рішень можуть відтворювати інтерпретовані правила. Дерева рішень також можуть використовувати як категоричні, так і безперервні змінні, що означає, що потрібно менше попередньої обробки порівняно з алгоритмами, які можуть обробляти лише один із цих типів змінних.
Дерева рішень, як правило, не дуже добре працюють, коли використовуються для визначення значень безперервних атрибутів. Іншим обмеженням дерев рішень є те, що під час класифікації, якщо є мало навчальних прикладів, але багато класів, дерево рішень має тенденцію бути неточним.










