
AI 101
Що таке зменшення розмірності?
Що таке зменшення розмірності?
Зменшення розмірності це процес, який використовується для зменшення розмірності набору даних, приймаючи багато функцій і представляючи їх у вигляді меншої кількості функцій. Наприклад, зменшення розмірності можна використати, щоб скоротити набір даних із двадцяти функцій до кількох. Зменшення розмірності зазвичай використовується в непідконтрольне навчання завдання для автоматичного створення класів із багатьох функцій. Щоб краще зрозуміти чому і як використовується зменшення розмірності, ми розглянемо проблеми, пов’язані з даними великої розмірності, і найпопулярніші методи зменшення розмірності.
Більше розмірів призводить до переобладнання
Розмірність стосується кількості ознак/стовпців у наборі даних.
Часто вважають, що в машинному навчанні більше функцій – це краще, оскільки це створює точнішу модель. Однак більше функцій не обов’язково означає кращу модель.
Функції набору даних можуть сильно відрізнятися залежно від того, наскільки вони корисні для моделі, причому багато функцій є неважливими. Крім того, чим більше функцій містить набір даних, тим більше зразків потрібно, щоб гарантувати, що різні комбінації ознак добре представлені в даних. Тому кількість зразків збільшується пропорційно кількості ознак. Більше зразків і більше функцій означають, що модель має бути складнішою, і коли моделі стають складнішими, вони стають більш чутливими до переобладнання. Модель надто добре запам’ятовує закономірності в навчальних даних, і їй не вдається узагальнити дані поза вибіркою.
Зменшення розмірності набору даних має кілька переваг. Як згадувалося, простіші моделі менш схильні до переобладнання, оскільки модель має робити менше припущень щодо того, як функції пов’язані одна з одною. Крім того, менша кількість розмірів означає, що для навчання алгоритмів потрібна менша обчислювальна потужність. Подібним чином, менше місця для зберігання потрібно для набору даних, який має меншу розмірність. Зменшення розмірності набору даних також може дозволити вам використовувати алгоритми, які не підходять для наборів даних із багатьма функціями.
Загальні методи зменшення розмірності
Зменшення розмірності може відбуватися шляхом вибору функцій або розробки функцій. Вибір функцій – це місце, де інженер визначає найбільш релевантні характеристики набору даних інженерія функцій це процес створення нових функцій шляхом поєднання або перетворення інших функцій.
Вибір функцій і розробку можна виконати програмно або вручну. Під час вибору та проектування об’єктів вручну типовою є візуалізація даних для виявлення кореляцій між об’єктами та класами. Зменшення розмірності таким чином може зайняти досить багато часу, тому деякі з найпоширеніших способів зменшення розмірності включають використання алгоритмів, доступних у бібліотеках, таких як Scikit-learn для Python. Ці загальні алгоритми зменшення розмірності включають: аналіз головних компонентів (PCA), сингулярне розкладання (SVD) і лінійний дискримінантний аналіз (LDA).
Алгоритми, які використовуються для зменшення розмірності для завдань неконтрольованого навчання, як правило, PCA та SVD, тоді як алгоритми, які використовуються для зменшення розмірності навчання під контролем, зазвичай LDA та PCA. У випадку моделей навчання під наглядом новостворені функції просто вводяться в класифікатор машинного навчання. Зверніть увагу, що описані тут способи використання є лише загальними випадками використання, а не єдиними умовами, у яких можна використовувати ці методи. Алгоритми зменшення розмірності, описані вище, є просто статистичними методами, і вони використовуються поза моделями машинного навчання.
Аналіз основних компонентів

Фото: Матриця з ідентифікованими основними компонентами
Аналіз основних компонентів (PCA) це статистичний метод, який аналізує характеристики/особливості набору даних і узагальнює характеристики, які є найбільш впливовими. Функції набору даних об’єднуються разом у представлення, які зберігають більшість характеристик даних, але розподіляються між меншою кількістю вимірів. Ви можете подумати про це як про «здавлювання» даних із представлення вищих вимірів до представлення лише з кількома вимірами.
Як приклад ситуації, коли PCA може бути корисним, подумайте про різні способи опису вина. Хоча можна описати вино за допомогою багатьох дуже специфічних характеристик, таких як рівні CO2, рівні аерації тощо, такі специфічні характеристики можуть бути відносно марними при спробі ідентифікувати конкретний тип вина. Натомість було б розумніше визначити тип на основі більш загальних ознак, таких як смак, колір і вік. PCA можна використовувати для поєднання більш конкретних функцій і створення функцій, які є більш загальними, корисними та з меншою ймовірністю спричинять переобладнання.
PCA виконується шляхом визначення того, як вхідні ознаки відрізняються від середнього по відношенню один до одного, визначаючи, чи існують будь-які зв’язки між ознаками. Для цього створюється коваріантна матриця, яка встановлює матрицю, що складається з коваріацій щодо можливих пар характеристик набору даних. Це використовується для визначення кореляції між змінними, при цьому негативна коваріація вказує на зворотну кореляцію, а позитивна кореляція вказує на позитивну кореляцію.
Головні (найбільш впливові) компоненти набору даних створюються шляхом створення лінійних комбінацій початкових змінних, що виконується за допомогою концепцій лінійної алгебри, які називаються власні значення та власні вектори. Комбінації створюються таким чином, що основні компоненти не корельовані один з одним. Більшість інформації, що міститься у початкових змінних, стискається в кілька перших основних компонентів, тобто створено нові функції (основні компоненти), які містять інформацію з вихідного набору даних у меншому розмірному просторі.
Розкладання сингулярних значень
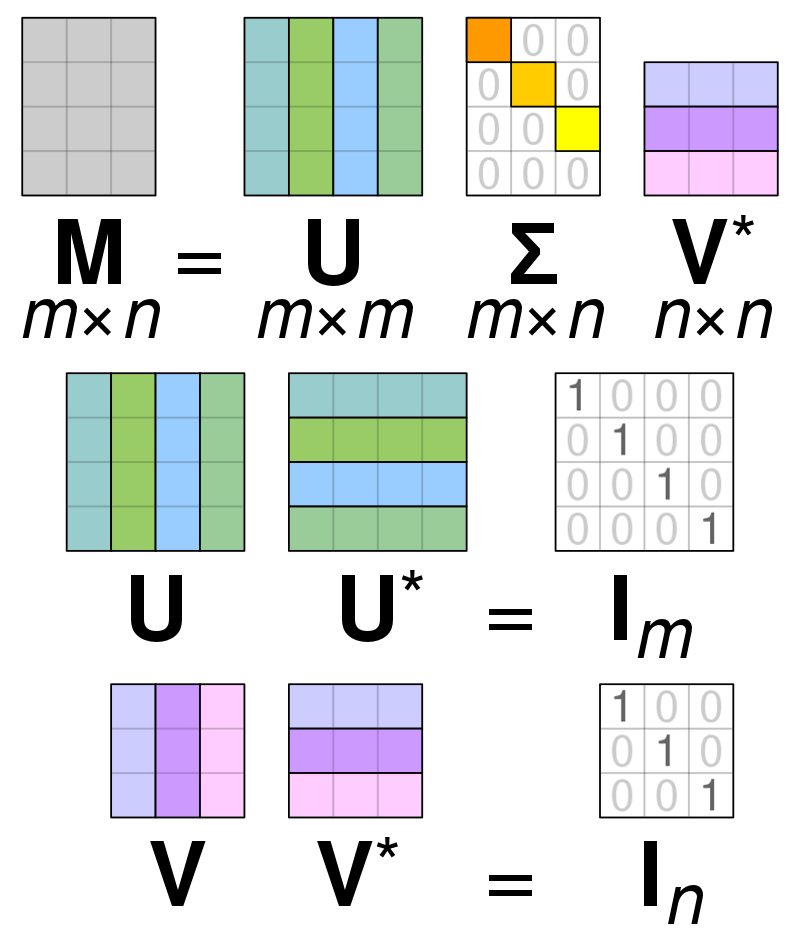
Фото: Автор Cmglee – Власна робота, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=67853297
Декомпозиція сингулярного значення (SVD) is використовується для спрощення значень у матриці, зводячи матрицю до її складових частин і полегшуючи обчислення з цією матрицею. SVD можна використовувати як для матриць реальних значень, так і для складних матриць, але для цілей цього пояснення ми розглянемо, як розкласти матрицю реальних значень.
Припустімо, що у нас є матриця, що складається з даних реального значення, і наша мета — зменшити кількість стовпців/функцій у матриці, подібно до мети PCA. Подібно до PCA, SVD стискає розмірність матриці, зберігаючи при цьому якомога більшу частину мінливості матриці. Якщо ми хочемо працювати з матрицею A, ми можемо представити матрицю A у вигляді трьох інших матриць, які називаються U, D і V. Матриця A складається з початкових елементів x * y, тоді як матриця U складається з елементів X * X (це ортогональну матрицю). Матриця V — це інша ортогональна матриця, що містить елементи y * y. Матриця D містить елементи x * y і є діагональною матрицею.
Для того, щоб розкласти значення для матриці A, нам потрібно перетворити вихідні сингулярні значення матриці на діагональні значення, знайдені в новій матриці. При роботі з ортогональними матрицями їх властивості не змінюються, якщо їх помножити на інші числа. Отже, ми можемо апроксимувати матрицю A, скориставшись цією властивістю. Коли ми множимо ортогональні матриці разом із транспонуванням матриці V, результатом є матриця, еквівалентна нашій вихідній A.
Коли матриця a розкладається на матриці U, D і V, вони містять дані, знайдені в матриці A. Однак крайні ліві стовпці матриць міститимуть більшість даних. Ми можемо взяти лише ці кілька перших стовпців і мати представлення матриці А, яке має набагато менше вимірів і більшість даних в А.
Лінійний дискримінантний аналіз

Ліворуч: матриця перед LDA, праворуч: вісь після LDA, тепер роздільна
Лінійний дискримінантний аналіз (LDA) це процес, який бере дані з багатовимірного графіка та перепроектує його на лінійний графік. Ви можете уявити це, подумавши про двовимірний графік, заповнений точками даних, що належать до двох різних класів. Припустимо, що точки розкидані навколо так, що неможливо намалювати лінію, яка б чітко розділяла два різні класи. Щоб впоратися з цією ситуацією, точки, знайдені на двовимірному графіку, можна зменшити до одновимірного графіка (лінії). Цей рядок матиме всі точки даних, розподілені по ньому, і, сподіваємось, його можна розділити на дві частини, які представляють найкраще розділення даних.
При проведенні LDA є дві основні цілі. Перша мета — мінімізація дисперсії для класів, а друга — максимізація відстані між середніми значеннями двох класів. Ці цілі досягаються шляхом створення нової осі, яка буде існувати на двовимірному графіку. Новостворена вісь розділяє два класи на основі описаних раніше цілей. Після створення осі точки, знайдені на двовимірному графіку, розміщуються вздовж осі.
Для переміщення початкових точок у нове положення вздовж нової осі необхідно виконати три кроки. На першому кроці відстань між окремими класами (міжкласова дисперсія) використовується для обчислення роздільності класів. На другому кроці розраховується дисперсія в межах різних класів шляхом визначення відстані між вибіркою та середнім для даного класу. На останньому кроці створюється низьковимірний простір, який максимізує відмінності між класами.
Техніка LDA досягає найкращих результатів, коли засоби для цільових класів знаходяться далеко один від одного. LDA не може ефективно відокремити класи лінійною віссю, якщо засоби для розподілів перекриваються.










