ШІ 101
Що таке RNN та LSTMs у глибокому навчанні?
Багато з найбільш вражаючих досягнень у галузі обробки природної мови та чат-ботів штучного інтелекту засновані на рекурентних нейронних мережах (RNN) та мережах з довгостроковою пам’яттю (LSTM). RNN та LSTMs – це спеціальні архітектури нейронних мереж, які здатні обробляти послідовні дані, дані, у яких хронологічний порядок має значення. LSTMs можна вважати покращеними версіями RNN, здатними інтерпретувати довші послідовності даних. Давайте розглянемо, як структуровані RNN та LSTMs, і як вони дозволяють створювати складні системи обробки природної мови.
Що таке нейронні мережі з прямим зв’язком?
Перш ніж ми поговоримо про те, як працюють довгострокова пам’ять (LSTM) та конволюційні нейронні мережі (CNN), ми повинні обговорити загальну структуру нейронної мережі.
Нейронна мережа призначена для вивчення даних та знаходження відповідних закономірностей, щоб ці закономірності можна було застосовувати до інших даних та класифікувати нові дані. Нейронні мережі складаються з трьох секцій: входної шари, прихований шар (або декілька прихованих шарів) та вихідної шари.
Вхідний шар приймає дані в нейронну мережу, тоді як приховані шари вчаться знаходити закономірності в даних. Приховані шари в наборі даних пов’язані з вхідними та вихідними шарами за допомогою “ваг” та “потенціалів”, які є лише припущеннями про те, як дані пов’язані між собою. Ці ваги коригуються під час навчання. Коли мережа навчається, передбачення моделі щодо навчальних даних (вихідні значення) порівнюються з фактичними навчальними мітками. Під час навчання мережа повинна (сподіваємося) ставати все більш точною в передбаченні відносин між даними точками, щоб могла точно класифікувати нові дані точки. Глибokie нейронні мережі – це мережі, які мають більше шарів посередині/більше прихованих шарів. Чим більше прихованих шарів і нейронів/вузлів у моделі, тим краще модель може розпізнавати закономірності в даних.
Регулярні нейронні мережі з прямим зв’язком, як ті, які я описав вище, часто називаються “густими нейронними мережами”. Ці густі нейронні мережі поєднуються з різними архітектурами мереж, які спеціалізуються на інтерпретації різних видів даних.
Що таке RNN (рекурентні нейронні мережі)?

Рекурентні нейронні мережі приймають загальне принцип нейронних мереж з прямим зв’язком та дозволяють їм обробляти послідовні дані, надаючи моделі внутрішню пам’ять. “Рекурентна” частина назви RNN походить від того факту, що входи та виходи мережі утворюють цикл. Як тільки мережа видає вихід, цей вихід копіюється та повертається в мережу як вхід. При прийнятті рішення не тільки поточний вхід та вихід аналізуються, але також розглядається попередній вхід. Інакше кажучи, якщо початковий вхід для мережі – X, а вихід – H, то як H, так і X1 (наступний вхід у послідовності даних) подаються в мережу для наступного раунду навчання. Таким чином, контекст даних (попередні входи) зберігається під час навчання мережі.
Результатом цієї архітектури є те, що RNN здатні обробляти послідовні дані. Однак RNN страждають від декількох проблем. RNN страждають від проблем зникаючого градієнта та вибухаючого градієнта.
Довжина послідовностей, яку може інтерпретувати RNN, досить обмежена, особливо порівняно з LSTMs.
Що таке LSTMs (мережі з довгостроковою пам’яттю)?
Мережі з довгостроковою пам’яттю можна вважати розширеннями RNN, знову застосовуючи концепцію збереження контексту входів. Однак LSTMs були модифіковані декількома важливими способами, які дозволяють їм інтерпретувати попередні дані більш досконалими методами. Зміни, внесені в LSTMs, стосуються проблеми зникаючого градієнта та дозволяють LSTMs розглядати значно довші послідовності входів.

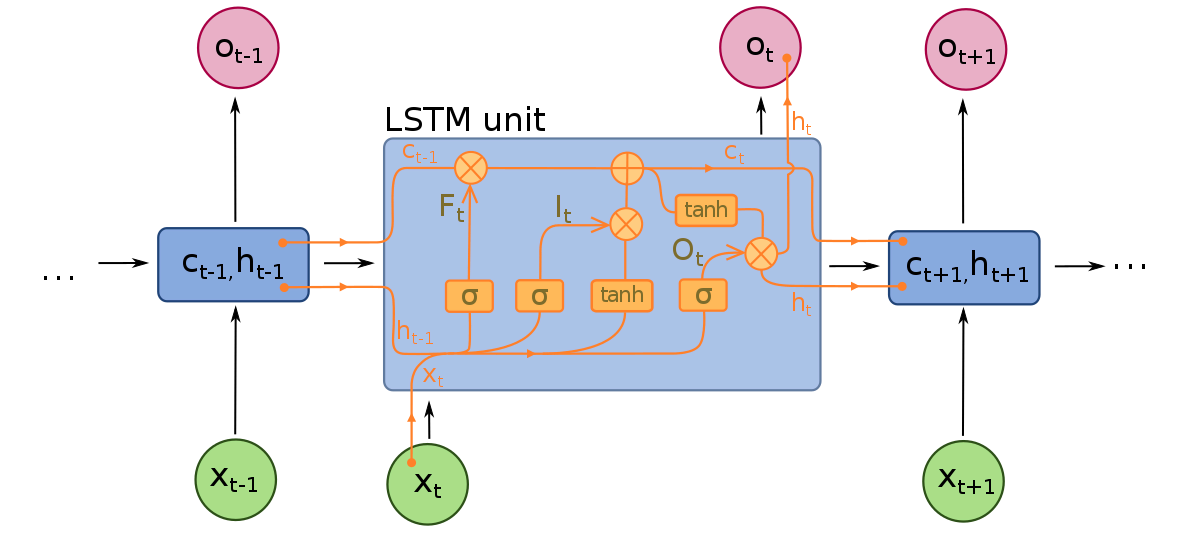
Моделі LSTMs складаються з трьох різних компонентів, або воріт. Є вхідні ворота, вихідні ворота та ворота, які забувають. Як і RNN, LSTMs приймають до уваги входи з попереднього часу при зміні пам’яті моделі та ваг входів. Вхідні ворота приймають рішення про те, які значення важливі та повинні бути пропущені через модель. Сигмоїдна функція використовується у вхідних воротах, яка приймає рішення про те, які значення пропускати через рекурентну мережу. Нуль скидає значення, тоді як 1 зберігає його. Функція TanH також використовується тут, яка приймає рішення про те, наскільки важливі для моделі входні значення, в діапазоні від -1 до 1.
Після того, як поточні входи та стан пам’яті враховані, вихідні ворота вирішують, які значення слід передати до наступного часу. У вихідних воротах значення аналізуються та присвоюється важливість у діапазоні від -1 до 1. Це регулює дані перед тим, як вони передаються до наступного часу розрахунку. Нарешті, завдання воріт, які забувають, полягає в тому, щоб скинути інформацію, яку модель вважає непотрібною для прийняття рішення про природу входних значень. Ворота, які забувають, використовують сигмоїдну функцію на значеннях, видаючи числа між 0 (забути це) та 1 (зберегти це).
Нейронна мережа LSTMs складається як зі спеціальних шарів LSTMs, які можуть інтерпретувати послідовні дані слів, так і з густих шарів, описаних вище. Як тільки дані проходять через шари LSTMs, вони переходять у густі шари.








