
AI 101
Що таке CNN (згорточні нейронні мережі)?
Можливо, ви задавалися питанням, як Facebook або Instagram можуть автоматично розпізнавати обличчя на зображенні, або як Google дозволяє шукати в Інтернеті схожі фотографії, просто завантажуючи власну фотографію. Ці функції є прикладами комп’ютерного зору, і вони працюють від згорткові нейронні мережі (CNN). Але що таке згорткові нейронні мережі? Давайте глибше зануримося в архітектуру CNN і зрозуміємо, як вони працюють.
Що таке нейронні мережі?
Перш ніж ми почнемо говорити про згорточні нейронні мережі, давайте трохи визначимо регулярну нейронну мережу. Є інша стаття на тему доступних нейронних мереж, тому ми не будемо заглиблюватися в них тут. Однак, якщо коротко їх визначити, то це обчислювальні моделі, створені людським мозком. Нейронна мережа працює, приймаючи дані та маніпулюючи даними, регулюючи «ваги», які є припущеннями про те, як вхідні характеристики пов’язані між собою та класом об’єкта. Коли мережа навчається, значення ваг коригуються, і, сподіваємося, вони будуть сходитися до ваг, які точно відображають зв’язки між функціями.
Ось як працює нейронна мережа прямого зв’язку, а CNN складаються з двох частин: нейронної мережі прямого зв’язку та групи згорткових шарів.
Що таке згорточні нейронні мережі (CNN)?
Що таке «згортки», які відбуваються в згортковій нейронній мережі? Згортка — це математична операція, яка створює набір вагових коефіцієнтів, по суті створюючи представлення частин зображення. Цей набір ваг називається ядро або фільтр. Створений фільтр менший за все вхідне зображення, охоплюючи лише частину зображення. Значення у фільтрі множаться на значення на зображенні. Потім фільтр переміщується, щоб сформувати представлення нової частини зображення, і процес повторюється, доки не буде покрито все зображення.
Інший спосіб подумати про це — уявити цегляну стіну, де цеглини представляють пікселі у вхідному зображенні. Вздовж стіни ковзають вперед і назад «вікно», яке є фільтром. Цеглинки, які можна переглянути у вікні, — це пікселі, значення яких помножено на значення у фільтрі. З цієї причини цей метод створення ваг за допомогою фільтра часто називають технікою «ковзних вікон».
Вихідні дані фільтрів, які переміщуються навколо всього вхідного зображення, є двовимірним масивом, що представляє все зображення. Цей масив називається a «карта функцій».
Чому згортки важливі
Яка взагалі мета створення звивин? Згортки необхідні, тому що нейронна мережа повинна мати можливість інтерпретувати пікселі зображення як числові значення. Функція згорткових шарів полягає в тому, щоб перетворювати зображення в числові значення, які нейронна мережа може інтерпретувати, а потім витягувати з них відповідні шаблони. Робота фільтрів у згортковій мережі полягає у створенні двовимірного масиву значень, які можуть бути передані на пізніші рівні нейронної мережі, ті, які вивчатимуть шаблони в зображенні.
Фільтри та канали
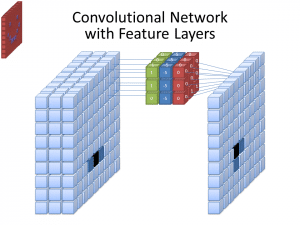
Фото: cecebur через Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)
CNN не використовують лише один фільтр для вивчення шаблонів із вхідних зображень. Використовується кілька фільтрів, оскільки різні масиви, створені різними фільтрами, призводять до більш складного, насиченого представлення вхідного зображення. Загальні номери фільтрів для CNN: 32, 64, 128 і 512. Чим більше фільтрів, тим більше можливостей CNN перевіряти вхідні дані та вчитися на них.
CNN аналізує різницю в значеннях пікселів, щоб визначити межі об’єктів. На зображенні в градаціях сірого CNN розглядатиме лише різницю в чорному та білому, від світлого до темного. Коли зображення є кольоровими, CNN не тільки враховує темний і світлий, але також має враховувати три різні колірні канали – червоний, зелений і синій. У цьому випадку фільтри мають 3 канали, як і саме зображення. Кількість каналів, які має фільтр, називається його глибиною, і кількість каналів у фільтрі має збігатися з кількістю каналів у зображенні.
Згортка нейронна мережа (CNN) архітектура
Давайте поглянемо на повну архітектуру згорточна нейронна мережа. Згортковий шар знаходиться на початку кожної згорткової мережі, оскільки необхідно перетворити дані зображення в числові масиви. Однак згорткові шари також можуть бути після інших згорткових шарів, тобто ці шари можна накладати один на одного. Наявність кількох згорткових шарів означає, що виходи з одного шару можуть зазнавати подальших згорток і групуватися разом у відповідні шаблони. На практиці це означає, що коли дані зображення проходять через згорткові шари, мережа починає «розпізнавати» більш складні характеристики зображення.
Ранні рівні ConvNet відповідають за виділення низькорівневих функцій, таких як пікселі, які складають прості лінії. Пізніші шари ConvNet об’єднають ці лінії разом у фігури. Цей процес переходу від аналізу поверхневого рівня до глибокого аналізу триває, доки ConvNet не почне розпізнавати складні форми, такі як тварини, людські обличчя та автомобілі.
Після того, як дані пройшли через усі шари згортки, вони переходять до щільно зв’язаної частини CNN. Щільно зв’язані шари – це те, як виглядає традиційна нейронна мережа прямого зв’язку, серія вузлів, об’єднаних у шари, які з’єднані один з одним. Дані проходять через ці щільно зв’язані шари, які вивчають шаблони, витягнуті згортковими шарами, і таким чином мережа стає здатною розпізнавати об’єкти.










