AI 101
อะไรคือ Overfitting?
อะไรคือ Overfitting?
เมื่อคุณฝึกเครือข่ายประสาทเทียม คุณต้องหลีกเลี่ยงการ Overfitting Overfitting เป็นปัญหาภายในการเรียนรู้ของเครื่องและสถิติซึ่งแบบจำลองเรียนรู้รูปแบบของชุดข้อมูลฝึกอบรมได้ดีเกินไป โดยอธิบายชุดข้อมูลฝึกอบรมได้อย่างสมบูรณ์แบบ แต่ล้มเหลวในการสร้างพลังในการคาดการณ์ไปยังชุดข้อมูลอื่น
เพื่ออธิบายอีกครั้ง ในกรณีของแบบจำลอง Overfitting มันจะแสดงความแม่นยำสูงมากในชุดข้อมูลฝึกอบรม แต่ความแม่นยำต่ำในชุดข้อมูลที่รวบรวมและนำไปใช้กับแบบจำลองในอนาคต นั่นคือคำจำกัดความที่รวดเร็วของ Overfitting แต่มาเรียนรู้เกี่ยวกับแนวคิดของ Overfitting กันอย่างละเอียด มาเรียนรู้เกี่ยวกับวิธีการเกิด Overfitting และวิธีการหลีกเลี่ยงมัน
การทำความเข้าใจ “Fit” และ Underfitting
มันจะช่วยให้คุณเข้าใจแนวคิดของ Underfitting และ “fit” โดยทั่วไปเมื่อพูดถึง Overfitting เมื่อเราฝึกแบบจำลอง เรากำลังพัฒนากรอบงานที่สามารถคาดการณ์ธรรมชาติหรือประเภทของรายการในชุดข้อมูลตามคุณลักษณะที่อธิบายรายการเหล่านั้น แบบจำลองควรสามารถอธิบายรูปแบบในชุดข้อมูลและคาดการณ์ประเภทของจุดข้อมูลในอนาคตตามรูปแบบนี้ ความสัมพันธ์ที่ดีกว่าระหว่างคุณลักษณะของชุดฝึกอบรมที่แบบจำลองอธิบายได้ จะทำให้แบบจำลองของเรามีความ “fit” มากขึ้น

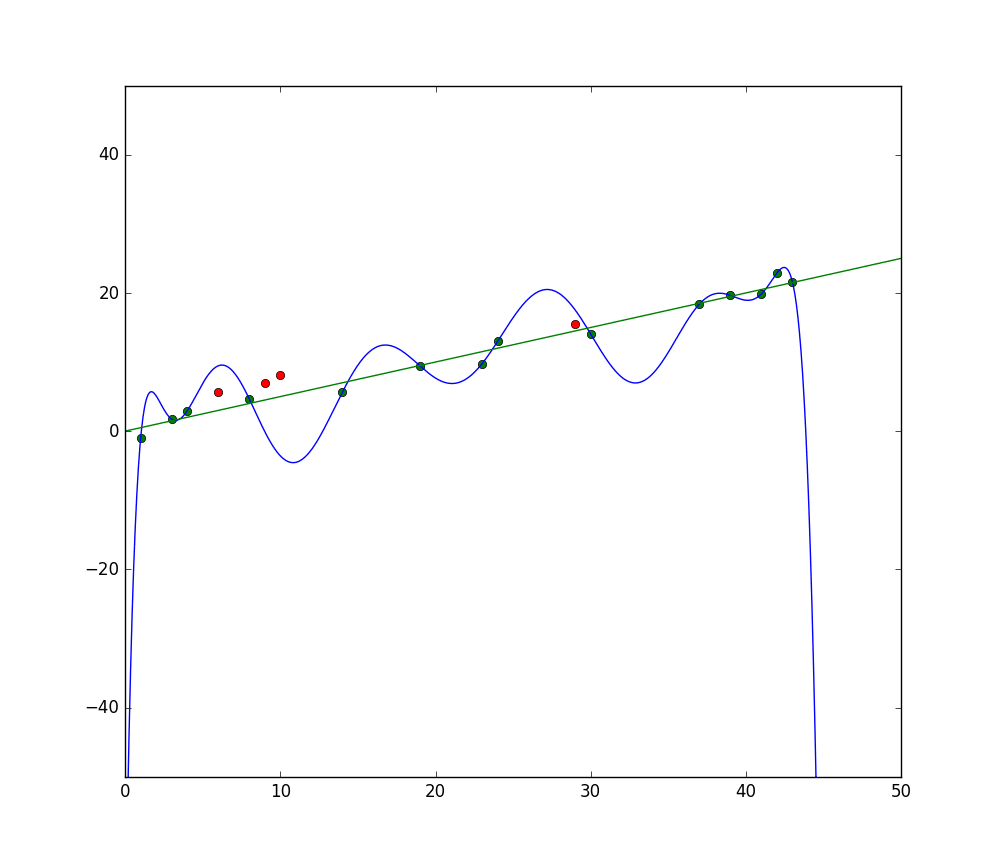
เส้นสีน้ำเงินแสดงถึงการคาดการณ์ของแบบจำลองที่ Underfitting ในขณะที่เส้นสีเขียวแสดงถึงแบบจำลองที่มีการ “fit” ที่ดีกว่า ภาพ: Pep Roca via Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
แบบจำลองที่อธิบายความสัมพันธ์ระหว่างคุณลักษณะของข้อมูลฝึกอบรมได้ไม่ดีและล้มเหลวในการคาดการณ์ประเภทของตัวอย่างข้อมูลในอนาคตจึงเป็นการ Underfitting หากคุณวางแผนการคาดการณ์ของแบบจำลองที่ Underfitting กับจุดข้อมูลที่แท้จริง การคาดการณ์จะออกไปจากเป้าหมาย หากเรามีแผนภูมิที่มีค่าจริงของชุดฝึกอบรมที่มีฉลาก แบบจำลองที่ Underfitting อย่างรุนแรงจะพลาดจุดข้อมูลส่วนใหญ่ แบบจำลองที่มีการ “fit” ที่ดีกว่าอาจผ่านจุดกึ่งกลางของจุดข้อมูล โดยมีจุดข้อมูลแต่ละจุดอยู่ห่างจากค่า预测ไปไม่มากนัก
การ Underfitting มักจะเกิดขึ้นเมื่อมีข้อมูลไม่เพียงพอในการสร้างแบบจำลองที่แม่นยำ หรือเมื่อพยายามออกแบบแบบจำลองเชิงเส้นสำหรับข้อมูลที่ไม่ใช่เชิงเส้น ข้อมูลฝึกอบรมเพิ่มเติมหรือคุณลักษณะเพิ่มเติมมักจะช่วยลดการ Underfitting
แล้วทำไมเราจึงไม่สร้างแบบจำลองที่อธิบายทุกจุดในชุดข้อมูลฝึกอบรมได้อย่างสมบูรณ์แบบ? แน่นอนว่าความแม่นยำที่สมบูรณ์แบบนั้นเป็นที่ต้องการ? การสร้างแบบจำลองที่เรียนรู้รูปแบบของชุดข้อมูลฝึกอบรมได้ดีเกินไปนั้นเป็นสาเหตุของการ Overfitting ชุดข้อมูลฝึกอบรมและชุดข้อมูลในอนาคตที่คุณจะนำไปใช้กับแบบจำลองจะไม่เหมือนกันอย่างแน่นอน มันจะคล้ายกันในหลายด้าน แต่จะแตกต่างกันในหลายด้านที่สำคัญ ดังนั้นการออกแบบแบบจำลองที่อธิบายชุดข้อมูลฝึกอบรมได้อย่างสมบูรณ์แบบจะทำให้คุณมีทฤษฎีเกี่ยวกับความสัมพันธ์ระหว่างคุณลักษณะที่ไม่สามารถสร้างพลังในการคาดการณ์ไปยังชุดข้อมูลอื่นได้
การทำความเข้าใจ Overfitting
การ Overfitting เกิดขึ้นเมื่อแบบจำลองเรียนรู้รายละเอียดในชุดข้อมูลฝึกอบรมได้ดีเกินไป ทำให้แบบจำลองมีปัญหาเมื่อคาดการณ์ข้อมูลภายนอก สิ่งนี้อาจเกิดขึ้นเมื่อแบบจำลองไม่เพียงแต่เรียนรู้คุณลักษณะของชุดข้อมูล แต่ยังเรียนรู้การแกว่งเกินไปหรือ เสียงรบกวน ภายในชุดข้อมูล โดยให้ความสำคัญกับการเกิดขึ้นแบบสุ่มหรือสิ่งที่ไม่สำคัญ
การ Overfitting มีแนวโน้มที่จะเกิดขึ้นเมื่อใช้แบบจำลองที่ไม่ใช่เชิงเส้น เนื่องจากมีความยืดหยุ่นมากกว่าเมื่อเรียนรู้คุณลักษณะของข้อมูล แบบจำลองการเรียนรู้ของเครื่องไม่มีพารามิเตอร์มักจะมีพารามิเตอร์และเทคนิคต่างๆ ที่สามารถใช้เพื่อจำกัดความไวต่อข้อมูลของแบบจำลองและลดการ Overfitting ตัวอย่างเช่น แบบจำลองต้นไม้ตัดสินใจ มีความไวต่อการ Overfitting สูง แต่เทคนิคที่เรียกว่าการตัดแต่งสามารถใช้เพื่อลบรายละเอียดบางส่วนที่แบบจำลองได้เรียนรู้ออกไป
หากคุณวางแผนการคาดการณ์ของแบบจำลองบนแกน X และ Y คุณจะมีเส้นคาดการณ์ที่เคลื่อนไหวไปมา ซึ่งสะท้อนถึงความจริงที่ว่าแบบจำลองพยายามที่จะพอดีกับทุกจุดในชุดข้อมูลมากเกินไป
การควบคุม Overfitting
เมื่อเราฝึกแบบจำลอง เราต้องการให้แบบจำลองไม่มีข้อผิดพลาด เมื่อประสิทธิภาพของแบบจำลองเข้าใกล้การคาดการณ์ที่ถูกต้องทั้งหมดในชุดข้อมูลฝึกอบรม การ “fit” จะดีขึ้น แบบจำลองที่มีการ “fit” ที่ดีสามารถอธิบายชุดข้อมูลฝึกอบรมได้เกือบหมดโดยไม่เกิดการ Overfitting
เมื่อแบบจำลองฝึกอบรม ประสิทธิภาพจะดีขึ้นตามเวลา อัตราความผิดพลาดของแบบจำลองจะลดลงเมื่อเวลาผ่านไป แต่จะลดลงเพียงจุดหนึ่ง จุดที่ประสิทธิภาพของแบบจำลองในชุดข้อมูลทดสอบเริ่มเพิ่มขึ้นอีกครั้ง通常เป็นจุดที่การ Overfitting เกิดขึ้น เพื่อให้ได้การ “fit” ที่ดีที่สุดสำหรับแบบจำลอง เราต้องการหยุดการฝึกอบรมแบบจำลองที่จุดของการสูญเสียต่ำสุดในชุดข้อมูลฝึกอบรม ก่อนที่ความผิดพลาดจะเริ่มเพิ่มขึ้นอีกครั้ง จุดหยุดการฝึกอบรมที่เหมาะสมสามารถกำหนดได้โดยการวางแผนประสิทธิภาพของแบบจำลองตลอดเวลาในการฝึกอบรมและหยุดการฝึกอบรมเมื่อการสูญเสียต่ำสุด อย่างไรก็ตาม มีความเสี่ยงอย่างหนึ่งในการควบคุมการ Overfitting โดยใช้วิธีนี้ คือ การกำหนดจุดสิ้นสุดการฝึกอบรมตามประสิทธิภาพของแบบจำลองทดสอบหมายความว่าข้อมูลทดสอบจะถูกนำมาใช้ในการฝึกอบรมและเสียคุณสมบัติในการเป็นข้อมูล “ไม่สัมผัส” ที่บริสุทธิ์
มีหลายวิธีในการต่อสู้กับการ Overfitting วิธีหนึ่งในการลดการ Overfitting คือการใช้กลยุทธ์การสุ่มตัวอย่าง ซึ่งทำงานโดยการประมาณความแม่นยำของแบบจำลอง คุณยังสามารถใช้ ชุดข้อมูลทดสอบ เพิ่มเติมพร้อมกับชุดข้อมูลทดสอบและวางแผนความแม่นยำในการฝึกอบรมกับชุดข้อมูลทดสอบแทนชุดข้อมูลทดสอบ ซึ่งจะเก็บชุดข้อมูลทดสอบไว้ไม่สัมผัส วิธีการสุ่มตัวอย่างที่นิยมคือการ 교차-ตรวจสอบ K-folds เทคนิคนี้ช่วยให้คุณสามารถแบ่งข้อมูลออกเป็นชุดย่อยๆ ที่แบบจำลองจะฝึกอบรมและจากนั้นการตรวจสอบประสิทธิภาพของแบบจำลองในชุดย่อยเหล่านั้นเพื่อประมาณว่าแบบจำลองจะทำงานอย่างไรกับข้อมูลภายนอก
การใช้การ 교차-ตรวจสอบเป็นวิธีที่ดีที่สุดในการประมาณความแม่นยำของแบบจำลองกับข้อมูลที่ไม่สัมผัส และเมื่อรวมกับชุดข้อมูลทดสอบ การ Overfitting สามารถลดลงได้มาก








