
ปัญญาประดิษฐ์
Andrew Ng วิจารณ์วัฒนธรรมของการโอเวอร์ฟิตติ้งในแมชชีนเลิร์นนิง
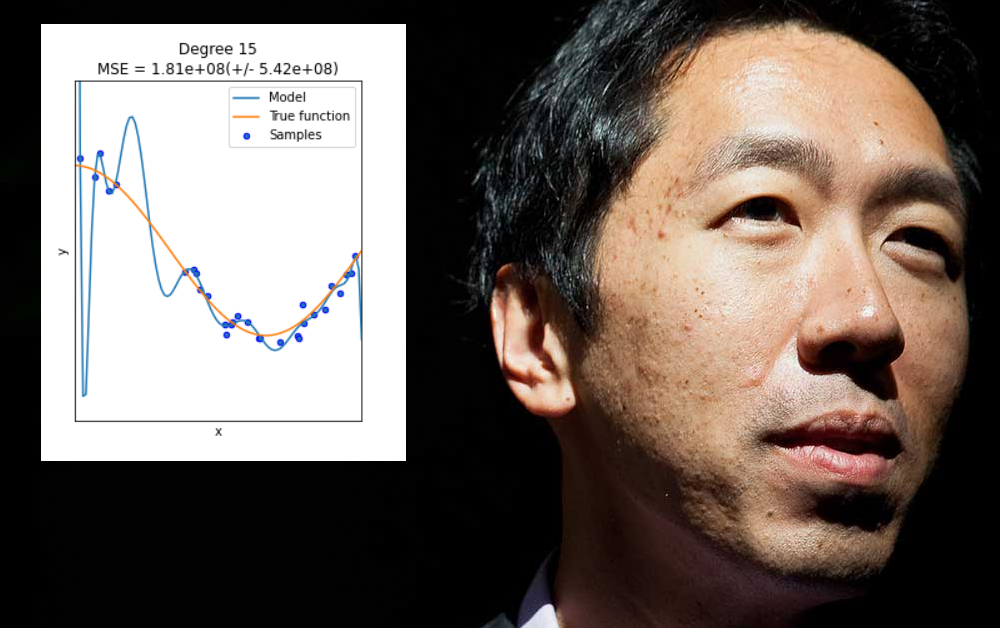
Andrew Ng หนึ่งในผู้ที่มีอิทธิพลมากที่สุดในด้านการเรียนรู้ของเครื่องในช่วงทศวรรษที่ผ่านมา กำลังแสดงความกังวลเกี่ยวกับขอบเขตที่ภาคส่วนนี้เน้นที่นวัตกรรมในสถาปัตยกรรมแบบจำลองมากกว่าข้อมูล และโดยเฉพาะอย่างยิ่ง ขอบเขตที่อนุญาตให้ผลลัพธ์ที่ 'ถูกติดตั้งมากเกินไป' ถูกมองว่าเป็นวิธีแก้ปัญหาหรือความก้าวหน้าทั่วไป
สิ่งเหล่านี้เป็นการวิพากษ์วิจารณ์อย่างกว้างขวางเกี่ยวกับวัฒนธรรมแมชชีนเลิร์นนิงในปัจจุบัน ซึ่งมาจากหนึ่งในหน่วยงานที่มีอำนาจสูงสุด และมีนัยถึงความเชื่อมั่นในภาคส่วนที่รุมเร้าด้วยความกลัวต่อ การล่มสลายครั้งที่สาม ของความเชื่อมั่นทางธุรกิจในการพัฒนา AI ในระยะเวลาหกสิบปี
อึ้ง ศาสตราจารย์แห่งมหาวิทยาลัยสแตนฟอร์ด เป็นหนึ่งในผู้ก่อตั้ง deeplearning.ai และในเดือนมีนาคมตีพิมพ์ จดหมาย บนไซต์ขององค์กรที่กลั่นก คำพูดล่าสุด จากคำแนะนำหลักสองสามประการของเขา:
ประการแรก ชุมชนการวิจัยควรหยุดบ่นว่าการล้างข้อมูลแสดงถึงความท้าทาย 80% ในแมชชีนเลิร์นนิง และเริ่มทำงานในการพัฒนาวิธีการและแนวทางปฏิบัติของ MLOps ที่มีประสิทธิภาพ
ประการที่สอง ควรย้ายออกจาก 'การชนะอย่างง่าย' ที่สามารถรับได้โดยการใส่ข้อมูลให้พอดีมากเกินไปกับโมเดลแมชชีนเลิร์นนิง เพื่อให้ทำงานได้ดีกับโมเดลนั้น แต่ล้มเหลวในการสรุปหรือสร้างโมเดลที่ปรับใช้ได้อย่างกว้างขวาง
ยอมรับความท้าทายของสถาปัตยกรรมข้อมูลและการดูแลจัดการ
'มุมมองของฉัน' อึ้งเขียน 'คือถ้า 80 เปอร์เซ็นต์ของงานของเราคือการเตรียมข้อมูล ดังนั้นการทำให้มั่นใจว่าคุณภาพของข้อมูลคืองานสำคัญของทีมแมชชีนเลิร์นนิง'
เขายังคง:
'แทนที่จะพึ่งพาวิศวกรเพื่อหาแนวทางที่ดีที่สุดในการปรับปรุงชุดข้อมูล ฉันหวังว่าเราจะสามารถพัฒนาเครื่องมือ MLOps ที่ช่วยสร้างระบบ AI รวมถึงการสร้างชุดข้อมูลคุณภาพสูง ทำซ้ำได้และเป็นระบบมากขึ้น
'MLOPs เป็นฟิลด์ที่เพิ่งตั้งขึ้นใหม่ และต่างคนต่างนิยามมันต่างกัน แต่ฉันคิดว่าหลักการจัดระเบียบที่สำคัญที่สุดของทีมและเครื่องมือ MLOps ควรเป็นเพื่อให้แน่ใจว่าการไหลของข้อมูลที่สม่ำเสมอและมีคุณภาพสูงตลอดทุกขั้นตอนของโครงการ สิ่งนี้จะช่วยให้หลาย ๆ โครงการดำเนินไปอย่างราบรื่นยิ่งขึ้น'
พูดผ่าน Zoom ในการสตรีมสด เซสชันถาม & ตอบ เมื่อปลายเดือนเมษายน Ng ได้กล่าวถึงปัญหาการบังคับใช้ในระบบการวิเคราะห์แมชชีนเลิร์นนิงสำหรับรังสีวิทยา:
“กลายเป็นว่าเมื่อเรารวบรวมข้อมูลจากโรงพยาบาลสแตนฟอร์ด แล้วเราฝึกและทดสอบข้อมูลจากโรงพยาบาลเดียวกัน เราสามารถเผยแพร่เอกสารที่แสดง [อัลกอริทึม] เทียบได้กับนักรังสีวิทยาในมนุษย์ในการระบุสภาวะบางอย่าง
“…[เมื่อ] คุณนำโมเดลเดียวกัน ระบบ AI เดียวกัน ไปยังโรงพยาบาลเก่าข้างถนน ด้วยเครื่องรุ่นเก่า และช่างเทคนิคใช้โปรโตคอลการถ่ายภาพที่แตกต่างกันเล็กน้อย ข้อมูลดังกล่าวจะลอยไปทำให้ประสิทธิภาพของระบบ AI ลดลงอย่างมาก ในทางตรงกันข้าม นักรังสีวิทยาในมนุษย์ทุกคนสามารถเดินไปตามถนนเพื่อไปยังโรงพยาบาลเก่าและทำได้ดี”
ข้อกำหนดที่ต่ำกว่าไม่ใช่วิธีแก้ปัญหา
การติดตั้งมากเกินไปเกิดขึ้นเมื่อโมเดลแมชชีนเลิร์นนิงได้รับการออกแบบมาเป็นพิเศษเพื่อรองรับความเยื้องศูนย์ของชุดข้อมูลเฉพาะ (หรือวิธีการจัดรูปแบบข้อมูล) ซึ่งอาจเกี่ยวข้องกับการระบุน้ำหนักที่จะสร้างผลลัพธ์ที่ดีจากชุดข้อมูลนั้น แต่จะไม่ 'สรุป' กับข้อมูลอื่น
ในหลายกรณี พารามิเตอร์ดังกล่าวถูกกำหนดในด้าน 'ที่ไม่ใช่ข้อมูล' ของชุดการฝึก เช่น ความละเอียดเฉพาะของข้อมูลที่รวบรวม หรือลักษณะเฉพาะอื่นๆ ที่ไม่รับประกันว่าจะเกิดขึ้นซ้ำในชุดข้อมูลอื่นๆ ที่ตามมา
แม้ว่าจะเป็นเรื่องดี แต่การใช้เกินพอดีไม่ใช่ปัญหาที่สามารถแก้ไขได้โดยการขยายขอบเขตหรือความยืดหยุ่นของสถาปัตยกรรมข้อมูลหรือการออกแบบแบบจำลองแบบสุ่มสี่สุ่มห้า เมื่อสิ่งที่จำเป็นจริง ๆ สามารถนำไปใช้ได้อย่างกว้างขวางและคุณลักษณะเด่นที่มีประสิทธิภาพสูงซึ่งจะทำงานได้ดีในช่วงของข้อมูล สภาพแวดล้อม - ความท้าทายที่ยากขึ้น
โดยทั่วไปแล้ว 'ข้อมูลที่ต่ำกว่าข้อกำหนด' ประเภทนี้มีแต่จะนำไปสู่ปัญหาที่ Ng ได้ระบุไว้เมื่อเร็วๆ นี้ ซึ่งโมเดลการเรียนรู้ของเครื่องล้มเหลวจากข้อมูลที่มองไม่เห็น ข้อแตกต่างในกรณีนี้คือ โมเดลล้มเหลว ไม่ใช่เพราะข้อมูลหรือการจัดรูปแบบข้อมูลแตกต่างจากชุดการฝึกดั้งเดิมที่มากเกินไป แต่เนื่องจากโมเดลมีความยืดหยุ่นเกินไปแทนที่จะเปราะเกินไป
ปลายปี 2020 กระดาษ ข้อกำหนดที่ต่ำกว่าเกณฑ์นำเสนอความท้าทายสำหรับความน่าเชื่อถือในการเรียนรู้ของเครื่องสมัยใหม่ ยกระดับการวิพากษ์วิจารณ์อย่างรุนแรงต่อแนวทางปฏิบัตินี้ และทำให้ชื่อของนักวิจัยและนักวิทยาศาสตร์ด้านการเรียนรู้ของเครื่องไม่น้อยกว่าสี่สิบคนจาก Google และ MIT รวมถึงสถาบันอื่นๆ
บทความวิพากษ์ 'การเรียนรู้ทางลัด' และสังเกตวิธีที่แบบจำลองที่ไม่ระบุรายละเอียดสามารถเริ่มต้นที่ไวด์แทนเจนต์โดยอิงจากจุดสุ่มที่การฝึกอบรมแบบจำลองเริ่มต้นขึ้น ผู้ร่วมให้ข้อมูลสังเกต:
'เราได้เห็นแล้วว่าข้อกำหนดที่ต่ำกว่านั้นมีอยู่ทั่วไปในไปป์ไลน์แมชชีนเลิร์นนิงที่ใช้งานได้จริงในหลายโดเมน ต้องขอบคุณการระบุรายละเอียดที่ต่ำกว่าความเป็นจริง แง่มุมที่สำคัญของการตัดสินใจถูกกำหนดโดยตัวเลือกตามอำเภอใจ เช่น เมล็ดสุ่มที่ใช้สำหรับการกำหนดค่าเริ่มต้นของพารามิเตอร์'
การแตกสาขาทางเศรษฐกิจของการเปลี่ยนแปลงวัฒนธรรม
แม้ว่าเขาจะมีความรู้ความสามารถด้านวิชาการ แต่ Ng ก็ไม่ใช่นักวิชาการที่โปร่งสบาย แต่มีประสบการณ์ในอุตสาหกรรมระดับสูงและลึกซึ้งในฐานะผู้ร่วมก่อตั้ง Google Brain และ Coursera ในฐานะอดีตหัวหน้านักวิทยาศาสตร์ของ Big Data และ AI ที่ Baidu และในฐานะ ผู้สร้าง ของ Landing AI ซึ่งดูแลเงิน 175 ล้านเหรียญสหรัฐสำหรับสตาร์ทอัพใหม่ในภาคส่วนนี้
เมื่อเขากล่าวว่า “AI ทั้งหมด ไม่ใช่แค่การดูแลสุขภาพเท่านั้นที่มีช่องว่างระหว่างการพิสูจน์แนวคิดและการผลิต” ตั้งใจให้เป็นการปลุกให้ภาคส่วนที่มีกระแสโฆษณาเกินจริงและประวัติที่พบเห็นได้โดดเด่นมากขึ้นเรื่อย ๆ ว่าเป็น การลงทุนทางธุรกิจระยะยาวที่ไม่แน่นอน รุมเร้า จากปัญหาด้านนิยามและขอบเขต
อย่างไรก็ตาม ระบบแมชชีนเลิร์นนิงที่เป็นกรรมสิทธิ์ซึ่งทำงานได้ดีในแหล่งกำเนิดและล้มเหลวในสภาพแวดล้อมอื่นๆ แสดงถึงประเภทของการยึดครองตลาดที่สามารถให้รางวัลแก่การลงทุนในอุตสาหกรรม การนำเสนอ 'ปัญหาเกินพอดี' ในบริบทของอันตรายจากการทำงานเป็นวิธีการที่คลุมเครือ สร้างรายได้ การลงทุนขององค์กรในการวิจัยโอเพ่นซอร์สและเพื่อผลิตระบบที่เป็นกรรมสิทธิ์ (อย่างมีประสิทธิภาพ) ซึ่งการจำลองแบบโดยคู่แข่งเป็นไปได้ แต่มีปัญหา
แนวทางนี้จะได้ผลในระยะยาวหรือไม่ขึ้นอยู่กับขอบเขตที่ความก้าวหน้าอย่างแท้จริงในการเรียนรู้ของเครื่องยังคงต้องการ ระดับการลงทุนที่มากขึ้นและไม่ว่าความคิดริเริ่มที่มีประสิทธิผลทั้งหมดจะโยกย้ายไปยัง FAANG อย่างหลีกเลี่ยงไม่ได้ในระดับหนึ่งหรือไม่ เนื่องจากทรัพยากรจำนวนมหาศาลที่จำเป็นสำหรับการโฮสต์และการดำเนินงาน















