
AI 101
การลดมิติคืออะไร?
การลดมิติคืออะไร?
การลดมิติ เป็นกระบวนการที่ใช้ในการลดมิติข้อมูลของชุดข้อมูล โดยนำคุณสมบัติหลายอย่างมาแสดงเป็นคุณสมบัติที่น้อยลง ตัวอย่างเช่น การลดขนาดสามารถใช้เพื่อลดชุดข้อมูลที่มีคุณลักษณะ XNUMX รายการให้เหลือคุณลักษณะเพียงไม่กี่รายการ การลดขนาดมักใช้ใน การเรียนรู้โดยไม่ได้รับการดูแล งานเพื่อสร้างชั้นเรียนโดยอัตโนมัติจากคุณสมบัติมากมาย เพื่อให้เข้าใจได้ดีขึ้น เหตุใดจึงใช้การลดมิติข้อมูลเราจะพิจารณาปัญหาที่เกี่ยวข้องกับข้อมูลมิติสูงและวิธีที่ได้รับความนิยมมากที่สุดในการลดมิติข้อมูล
ขนาดที่มากขึ้นนำไปสู่การโอเวอร์ฟิตติ้ง
มิติข้อมูลหมายถึงจำนวนคุณลักษณะ/คอลัมน์ภายในชุดข้อมูล
มักสันนิษฐานว่าใน Machine Learning ฟีเจอร์ต่างๆ จะดีกว่า เนื่องจากจะสร้างโมเดลที่แม่นยำยิ่งขึ้น อย่างไรก็ตาม คุณสมบัติเพิ่มเติมไม่ได้แปลว่าเป็นโมเดลที่ดีกว่าเสมอไป
คุณลักษณะของชุดข้อมูลอาจแตกต่างกันมากในแง่ของความมีประโยชน์ต่อแบบจำลอง โดยคุณลักษณะหลายอย่างมีความสำคัญเพียงเล็กน้อย นอกจากนี้ ยิ่งชุดข้อมูลมีฟีเจอร์มากเท่าใดก็ยิ่งต้องการตัวอย่างมากขึ้นเพื่อให้แน่ใจว่าชุดค่าผสมของฟีเจอร์ต่างๆ จะแสดงได้ดีภายในข้อมูล ดังนั้นจำนวนตัวอย่างจึงเพิ่มขึ้นตามสัดส่วนกับจำนวนคุณลักษณะ ตัวอย่างที่มากขึ้นและคุณสมบัติที่มากขึ้นหมายความว่าโมเดลต้องมีความซับซ้อนมากขึ้น และเมื่อโมเดลมีความซับซ้อนมากขึ้น โมเดลจะไวต่อการปรับมากเกินไป โมเดลเรียนรู้รูปแบบในข้อมูลการฝึกได้ดีเกินไป และไม่สามารถสรุปเป็นข้อมูลทั่วไปจากข้อมูลตัวอย่างได้
การลดขนาดของชุดข้อมูลมีประโยชน์หลายประการ ดังที่ได้กล่าวไปแล้ว แบบจำลองที่เรียบง่ายกว่านั้นมีแนวโน้มที่จะเกินพอดีน้อยกว่า เนื่องจากแบบจำลองจะต้องตั้งสมมติฐานน้อยลงว่าคุณลักษณะต่างๆ เกี่ยวข้องกันอย่างไร นอกจากนี้ ขนาดที่น้อยลงหมายความว่าต้องใช้พลังการประมวลผลน้อยลงในการฝึกอัลกอริทึม ในทำนองเดียวกัน ต้องการพื้นที่จัดเก็บน้อยลงสำหรับชุดข้อมูลที่มีขนาดที่เล็กลง การลดมิติข้อมูลของชุดข้อมูลยังช่วยให้คุณใช้อัลกอริทึมที่ไม่เหมาะกับชุดข้อมูลที่มีคุณสมบัติมากมาย
วิธีการลดขนาดทั่วไป
การลดขนาดสามารถทำได้โดยการเลือกคุณสมบัติหรือวิศวกรรมคุณสมบัติ การเลือกคุณลักษณะคือที่ที่วิศวกรระบุคุณลักษณะที่เกี่ยวข้องมากที่สุดของชุดข้อมูล ในขณะที่ วิศวกรรมคุณลักษณะ เป็นกระบวนการสร้างคุณลักษณะใหม่โดยการรวมหรือแปลงคุณลักษณะอื่นๆ
การเลือกคุณสมบัติและวิศวกรรมสามารถทำได้โดยทางโปรแกรมหรือด้วยตนเอง เมื่อเลือกและสร้างคุณลักษณะด้วยตนเอง การแสดงภาพข้อมูลเพื่อค้นหาความสัมพันธ์ระหว่างคุณลักษณะและคลาสเป็นเรื่องปกติ การดำเนินการลดขนาดด้วยวิธีนี้อาจใช้เวลาค่อนข้างมาก ดังนั้นวิธีการลดขนาดที่พบได้บ่อยที่สุดคือการใช้อัลกอริทึมที่มีอยู่ในไลบรารี เช่น Scikit-learn สำหรับ Python อัลกอริธึมการลดขนาดทั่วไปเหล่านี้ประกอบด้วย: การวิเคราะห์องค์ประกอบหลัก (PCA) การสลายตัวของค่าเอกพจน์ (SVD) และการวิเคราะห์การจำแนกเชิงเส้น (LDA)
อัลกอริธึมที่ใช้ในการลดขนาดการเรียนรู้ภายใต้การดูแลโดยทั่วไปคือ PCA และ SVD ในขณะที่อัลกอริธึมที่ใช้ในการลดขนาดการเรียนรู้ภายใต้การดูแลโดยทั่วไปคือ LDA และ PCA ในกรณีของโมเดลการเรียนรู้ภายใต้การดูแล คุณลักษณะที่สร้างขึ้นใหม่จะถูกป้อนเข้าไปในตัวแยกประเภทแมชชีนเลิร์นนิงเท่านั้น โปรดทราบว่าการใช้งานที่อธิบายไว้ที่นี่เป็นเพียงกรณีการใช้งานทั่วไปเท่านั้น และไม่ใช่เงื่อนไขเดียวที่อาจใช้เทคนิคเหล่านี้ อัลกอริธึมการลดขนาดที่อธิบายไว้ข้างต้นเป็นเพียงวิธีการทางสถิติ และจะใช้นอกโมเดลการเรียนรู้ของเครื่อง
การวิเคราะห์องค์ประกอบหลัก

รูปถ่าย: เมทริกซ์ที่มีการระบุองค์ประกอบหลัก
การวิเคราะห์องค์ประกอบหลัก (PCA) เป็นวิธีการทางสถิติที่วิเคราะห์คุณลักษณะ/คุณลักษณะของชุดข้อมูล และสรุปคุณลักษณะที่มีอิทธิพลมากที่สุด คุณลักษณะของชุดข้อมูลจะรวมกันเป็นการแสดงที่รักษาคุณลักษณะส่วนใหญ่ของข้อมูลไว้ แต่กระจายไปในมิติที่น้อยลง คุณสามารถคิดได้ว่านี่เป็นการ "ยัดเยียด" ข้อมูลจากการแสดงมิติข้อมูลที่สูงขึ้นไปยังมิติข้อมูลเพียงไม่กี่มิติ
เป็นตัวอย่างของสถานการณ์ที่ PCA อาจมีประโยชน์ ลองนึกถึงวิธีต่างๆ ที่เราสามารถใช้อธิบายไวน์ได้ แม้ว่าจะสามารถอธิบายไวน์โดยใช้คุณสมบัติเฉพาะสูงหลายอย่าง เช่น ระดับ CO2 ระดับการเติมอากาศ ฯลฯ คุณลักษณะเฉพาะดังกล่าวอาจค่อนข้างไร้ประโยชน์เมื่อพยายามระบุประเภทไวน์เฉพาะ แต่จะเป็นการดีกว่าหากระบุประเภทตามลักษณะทั่วไป เช่น รสชาติ สี และอายุ สามารถใช้ PCA เพื่อรวมคุณสมบัติเฉพาะต่างๆ เข้าด้วยกัน และสร้างคุณสมบัติที่กว้างกว่า มีประโยชน์ และมีโอกาสน้อยที่จะทำให้เกิดการใช้งานมากเกินไป
PCA ดำเนินการโดยการพิจารณาว่าคุณลักษณะอินพุตแตกต่างจากค่าเฉลี่ยที่เกี่ยวข้องกันอย่างไร โดยพิจารณาว่ามีความสัมพันธ์ใดๆ ระหว่างคุณลักษณะต่างๆ หรือไม่ ในการทำเช่นนี้ เมทริกซ์ความแปรปรวนร่วมจะถูกสร้างขึ้น โดยสร้างเมทริกซ์ที่ประกอบด้วยความแปรปรวนร่วมที่เกี่ยวข้องกับคู่ที่เป็นไปได้ของคุณลักษณะชุดข้อมูล สิ่งนี้ใช้เพื่อกำหนดความสัมพันธ์ระหว่างตัวแปร โดยค่าความแปรปรวนร่วมเชิงลบบ่งชี้ความสัมพันธ์แบบผกผัน และความสัมพันธ์เชิงบวกบ่งชี้ความสัมพันธ์เชิงบวก
ส่วนประกอบหลัก (มีอิทธิพลมากที่สุด) ของชุดข้อมูลถูกสร้างขึ้นโดยการสร้างชุดค่าผสมเชิงเส้นของตัวแปรต้น ซึ่งทำได้โดยใช้แนวคิดพีชคณิตเชิงเส้นที่เรียกว่า ค่าลักษณะเฉพาะและเวกเตอร์ลักษณะเฉพาะ. ชุดค่าผสมถูกสร้างขึ้นเพื่อให้องค์ประกอบหลักไม่มีความเกี่ยวข้องกัน ข้อมูลส่วนใหญ่ที่มีอยู่ในตัวแปรเริ่มต้นถูกบีบอัดลงในองค์ประกอบหลักสองสามส่วนแรก ซึ่งหมายความว่ามีการสร้างคุณลักษณะใหม่ (องค์ประกอบหลัก) ที่มีข้อมูลจากชุดข้อมูลดั้งเดิมในพื้นที่มิติที่เล็กลง
การสลายตัวของค่าเอกพจน์
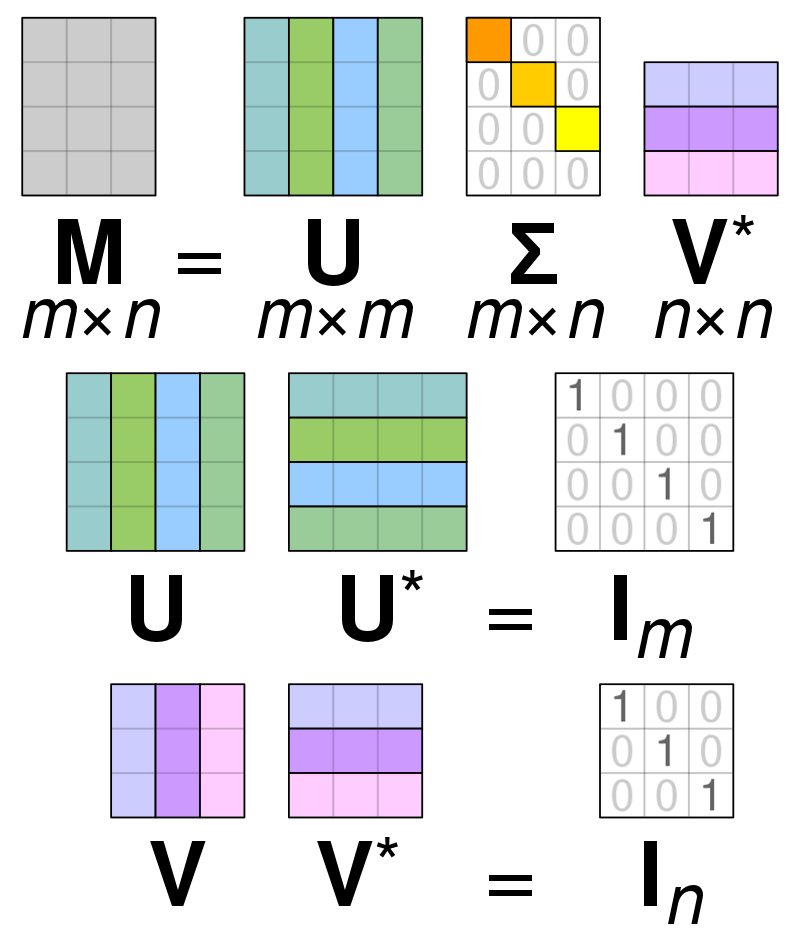
รูปภาพ: โดย Cmglee – งานของตัวเอง, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=67853297
การสลายตัวของค่าเอกพจน์ (SVD) is ใช้เพื่อลดความซับซ้อนของค่าภายในเมทริกซ์ลดเมทริกซ์ลงเหลือส่วนต่างๆ และทำให้การคำนวณด้วยเมทริกซ์นั้นง่ายขึ้น SVD สามารถใช้ได้กับทั้งเมทริกซ์แบบค่าจริงและแบบซับซ้อน แต่สำหรับจุดประสงค์ของคำอธิบายนี้จะตรวจสอบวิธีการแยกย่อยเมทริกซ์ของค่าจริง
สมมติว่าเรามีเมทริกซ์ที่ประกอบด้วยข้อมูลมูลค่าจริง และเป้าหมายของเราคือลดจำนวนคอลัมน์/คุณสมบัติภายในเมทริกซ์ คล้ายกับเป้าหมายของ PCA เช่นเดียวกับ PCA SVD จะบีบอัดขนาดของเมทริกซ์ในขณะที่รักษาความแปรปรวนของเมทริกซ์ให้ได้มากที่สุด ถ้าเราต้องการดำเนินการบนเมทริกซ์ A เราสามารถแสดงเมทริกซ์ A เป็นเมทริกซ์อีกสามตัวที่เรียกว่า U, D และ V เมทริกซ์ A ประกอบด้วยองค์ประกอบ x * y ดั้งเดิม ในขณะที่เมทริกซ์ U ประกอบด้วยองค์ประกอบ X * X (มันคือ เมทริกซ์มุมฉาก) เมทริกซ์ V เป็นเมทริกซ์มุมฉากที่แตกต่างกันซึ่งมีองค์ประกอบ y * y เมทริกซ์ D มีองค์ประกอบ x * y และเป็นเมทริกซ์แนวทแยง
ในการแยกย่อยค่าสำหรับเมทริกซ์ A เราจำเป็นต้องแปลงค่าเมทริกซ์เอกพจน์เดิมให้เป็นค่าแนวทแยงที่พบในเมทริกซ์ใหม่ เมื่อทำงานกับเมทริกซ์มุมฉาก คุณสมบัติของเมทริกซ์จะไม่เปลี่ยนแปลงหากคูณด้วยตัวเลขอื่นๆ ดังนั้น เราสามารถประมาณเมทริกซ์ A ได้โดยใช้คุณสมบัตินี้ เมื่อเราคูณเมทริกซ์มุมฉากร่วมกับทรานสโพสของเมทริกซ์ V ผลลัพธ์ที่ได้คือเมทริกซ์ที่เทียบเท่ากับ A ดั้งเดิมของเรา
เมื่อแยกเมทริกซ์ a ออกเป็นเมทริกซ์ U, D และ V พวกมันมีข้อมูลที่พบในเมทริกซ์ A อย่างไรก็ตาม คอลัมน์ซ้ายสุดของเมทริกซ์จะเก็บข้อมูลส่วนใหญ่ไว้ เราสามารถใช้แค่สองสามคอลัมน์แรกเหล่านี้และเป็นตัวแทนของเมทริกซ์ A ที่มีขนาดน้อยกว่ามากและข้อมูลส่วนใหญ่ภายใน A
การวิเคราะห์การเลือกปฏิบัติเชิงเส้น

ซ้าย: เมทริกซ์ก่อน LDA ขวา: แกนหลัง LDA แยกส่วนได้แล้ว
การวิเคราะห์การเลือกปฏิบัติเชิงเส้น (LDA) เป็นกระบวนการที่นำข้อมูลจากกราฟหลายมิติและ ฉายภาพซ้ำบนกราฟเชิงเส้น. คุณสามารถจินตนาการสิ่งนี้ได้โดยนึกถึงกราฟสองมิติที่เต็มไปด้วยจุดข้อมูลที่อยู่ในสองคลาสที่แตกต่างกัน สมมติว่าจุดต่างๆ กระจัดกระจายไปทั่วจนไม่สามารถลากเส้นที่จะแยกคลาสทั้งสองออกจากกันได้อย่างเรียบร้อย เพื่อจัดการกับสถานการณ์นี้ จุดที่พบในกราฟ 2 มิติสามารถลดลงเป็นกราฟ 1 มิติ (เส้น) บรรทัดนี้จะมีจุดข้อมูลทั้งหมดกระจายอยู่ทั่ว และหวังว่าจะสามารถแบ่งออกเป็นสองส่วนที่แสดงถึงการแยกข้อมูลที่ดีที่สุดเท่าที่จะเป็นไปได้
เมื่อดำเนินการ LDA มีเป้าหมายหลักสองประการ เป้าหมายแรกคือลดความแปรปรวนของคลาสให้น้อยที่สุด ในขณะที่เป้าหมายที่สองคือเพิ่มระยะห่างระหว่างค่าเฉลี่ยของคลาสทั้งสองให้สูงสุด เป้าหมายเหล่านี้สำเร็จได้ด้วยการสร้างแกนใหม่ที่จะอยู่ในกราฟ 2 มิติ แกนที่สร้างขึ้นใหม่ทำหน้าที่แยกสองคลาสตามเป้าหมายที่อธิบายไว้ก่อนหน้านี้ หลังจากสร้างแกนแล้ว จุดที่พบในกราฟ 2 มิติจะถูกวางไว้ตามแกน
มีสามขั้นตอนที่จำเป็นในการย้ายจุดเดิมไปยังตำแหน่งใหม่ตามแกนใหม่ ในขั้นตอนแรก ระยะห่างระหว่างแต่ละคลาสมีความหมาย (ความแปรปรวนระหว่างคลาส) ใช้เพื่อคำนวณความสามารถในการแยกออกจากกันของคลาส ในขั้นตอนที่สอง ความแปรปรวนภายในคลาสต่างๆ จะถูกคำนวณ โดยกำหนดระยะห่างระหว่างตัวอย่างและค่าเฉลี่ยสำหรับคลาสที่ต้องการ ในขั้นตอนสุดท้าย พื้นที่มิติล่างที่เพิ่มความแปรปรวนระหว่างคลาสจะถูกสร้างขึ้น
เทคนิค LDA บรรลุผลลัพธ์ที่ดีที่สุดเมื่อค่าเฉลี่ยสำหรับคลาสเป้าหมายอยู่ห่างไกลจากกัน LDA ไม่สามารถแยกคลาสด้วยแกนเชิงเส้นได้อย่างมีประสิทธิภาพหากค่าเฉลี่ยสำหรับการแจกแจงทับซ้อนกัน










